Última actualización: enero 30, 2022
12.0. Introducción
12.0.1. ¿Por qué debería tomar este módulo?
Bienvenido a la Resolución de problemas de red!
¿Quién es el mejor administrador de red que haya visto? ¿Por qué crees que esta persona es tan buena en eso? Probablemente, es porque esta persona es realmente buena para resolver problemas de red. Probablemente sean administradores experimentados, pero esa no es toda la historia. Los buenos solucionadores de problemas de red generalmente lo hacen de manera metódica, y utilizan todas las herramientas disponibles para ellos.
La verdad es que la única manera de convertirse en un buen solucionador de problemas de red es siempre solucionar problemas. Lleva tiempo ser bueno en esto. Pero por suerte para ti, hay muchos, muchos consejos y herramientas que puedes usar. Este módulo cubre los diferentes métodos de resolución de problemas de red y todos los consejos y herramientas que necesita para comenzar. Este módulo también tiene dos muy buenas actividades Packet Tracer para poner a prueba sus nuevas habilidades y conocimientos. Tal vez su objetivo debería ser convertirse en el mejor administrador de red que nadie jamás ha visto nunca!
12.0.2. ¿Qué aprenderé en este módulo?
Título del módulo: Resolución de problemas de red
Objetivos del módulo: Resuelva problemas de redes empresariales.
| Título del tema | Objetivo del tema |
|---|---|
| Documentación de red | Explique la forma en que se elabora y se utiliza la documentación de red para resolver problemas de red. |
| Proceso de resolución de problemas | Compare los métodos de resolución de problemas que usan un enfoque sistemático, en capas. |
| Herramientas para la resolución de problemas | Describa las diferentes herramientas para la resolución de problemas de redes. |
| Síntomas y causas de los problemas de red | Determine los síntomas y las causas de los problemas de red mediante un modelo en capas. |
| Resolución de problemas de conectividad IP | Solucione problemas de una red mediante un modelo en capas. |
12.1. Documentación de red
12.1.1. Descripción general de la documentación
Al igual que con cualquier actividad compleja, como la resolución de problemas de red, se debe comenzar con una buena documentación. Se requiere documentación de red precisa y completa para supervisar y solucionar problemas de redes de manera eficaz.
La documentación de red común incluye lo siguiente:
- Diagramas lógicos y físicos de topología de la red
- Documentación de dispositivos de red que registra toda la información pertinente del dispositivo
- Documentación de referencia del rendimiento de la red
Toda la documentación de red debe guardarse en una misma ubicación, ya sea como copia local o en un servidor protegido de la red. Debe realizarse una copia de seguridad del registro, la que se debe conservar en una ubicación diferente.
12.1.2. Diagramas de topología de la red
Los diagramas de topología de la red mantienen un registro de la ubicación, la función y el estado de los dispositivos en la red. Hay dos tipos de diagramas de topología de la red: la topología física y la topología lógica.
Haga clic en cada botón para ver un ejemplo y una explicación de las topologías físicas y lógicas.
- Topología física
- Topología lógica IPv4
- Topología lógica IPv6
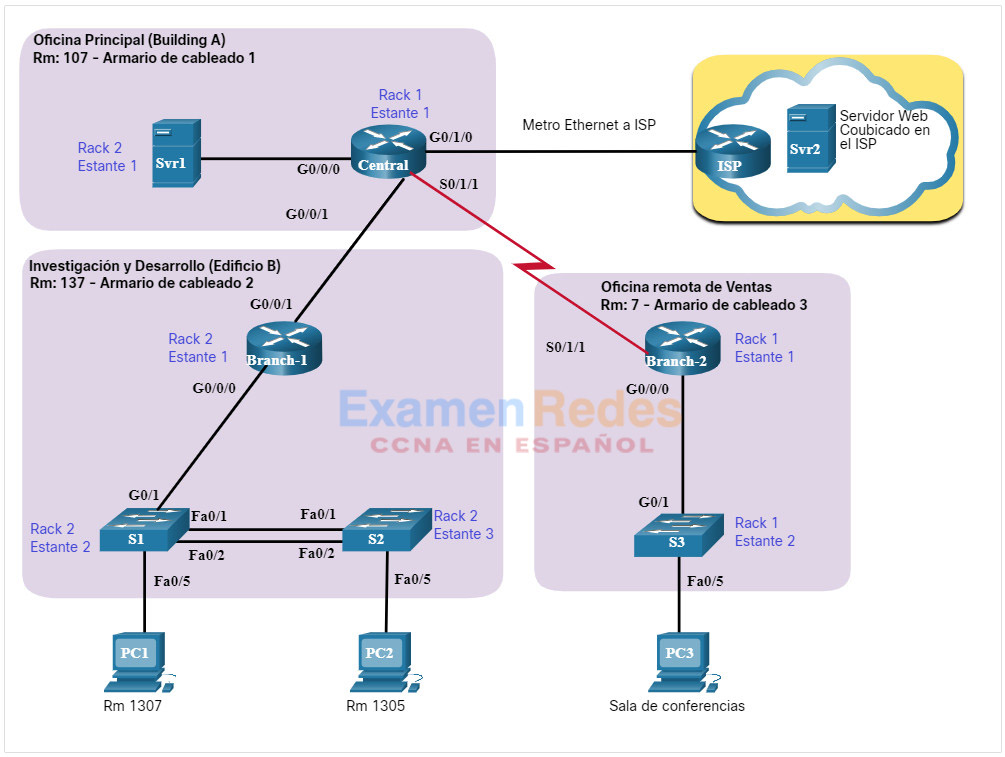
Una topología física de la red muestra la distribución física de los dispositivos conectados a la red. Para resolver problemas de la capa física, es necesario conocer la forma en que los dispositivos están conectados físicamente. La información registrada en la topología física suele incluir lo siguiente:
- Nombre del dispositivo
- Ubicación del dispositivo (dirección, número de habitación, ubicación del rack)
- Interfaces y puertos usados
- Tipo de cable
En la figura 1, se muestra un ejemplo de un diagrama de topología física de la red.
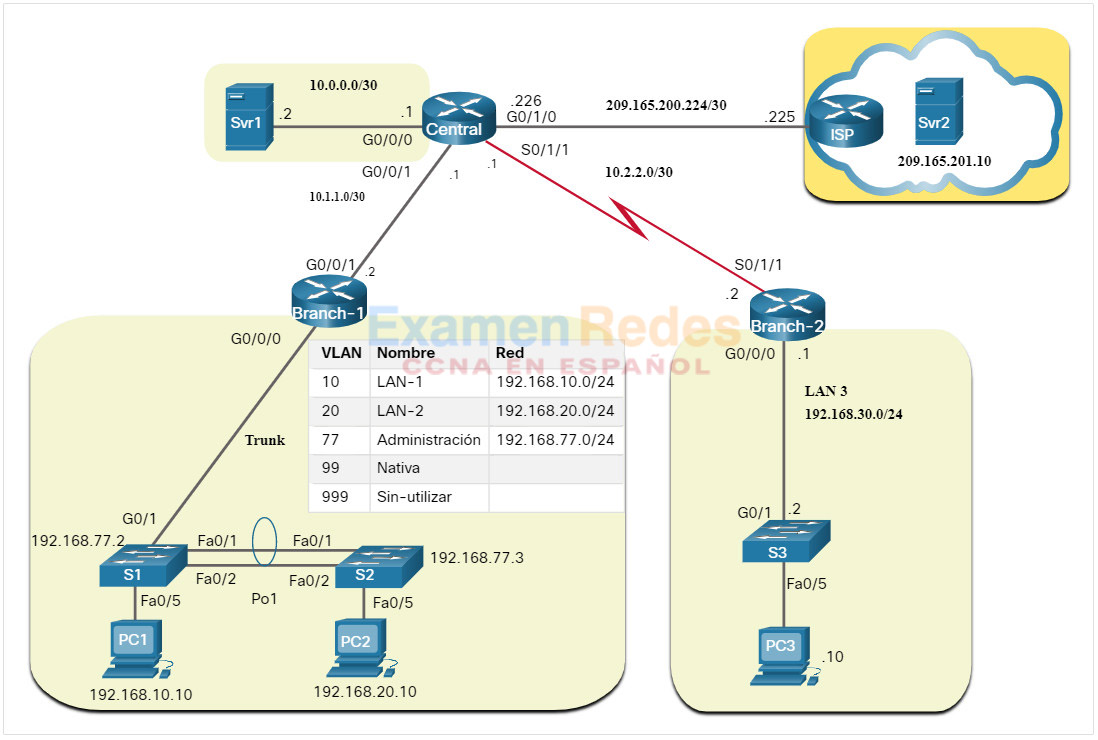
Los diagramas de red de topología lógica muestran la conexión lógica de los dispositivos a la red. Esto se refiere a cómo los dispositivos transfieren datos a través de la red cuando se comunican con otros dispositivos. Los símbolos se usan para representar los elementos de la red, como routers, switches, servidores, hosts. De manera adicional, se pueden mostrar conexiones entre varios sitios, pero no representan ubicaciones físicas reales.
La información registrada en un diagrama de red lógico puede incluir lo siguiente:
- Identificadores de dispositivos
- Dirección IP y longitudes de prefijos
- Identificadores de interfaz
- Protocolos de enrutamiento / rutas estáticas
- Información de Capa 2 (VLAN, enlaces troncales, EtherChannels)
En la figura 2, se muestra un ejemplo de topología lógica de red IPv4.
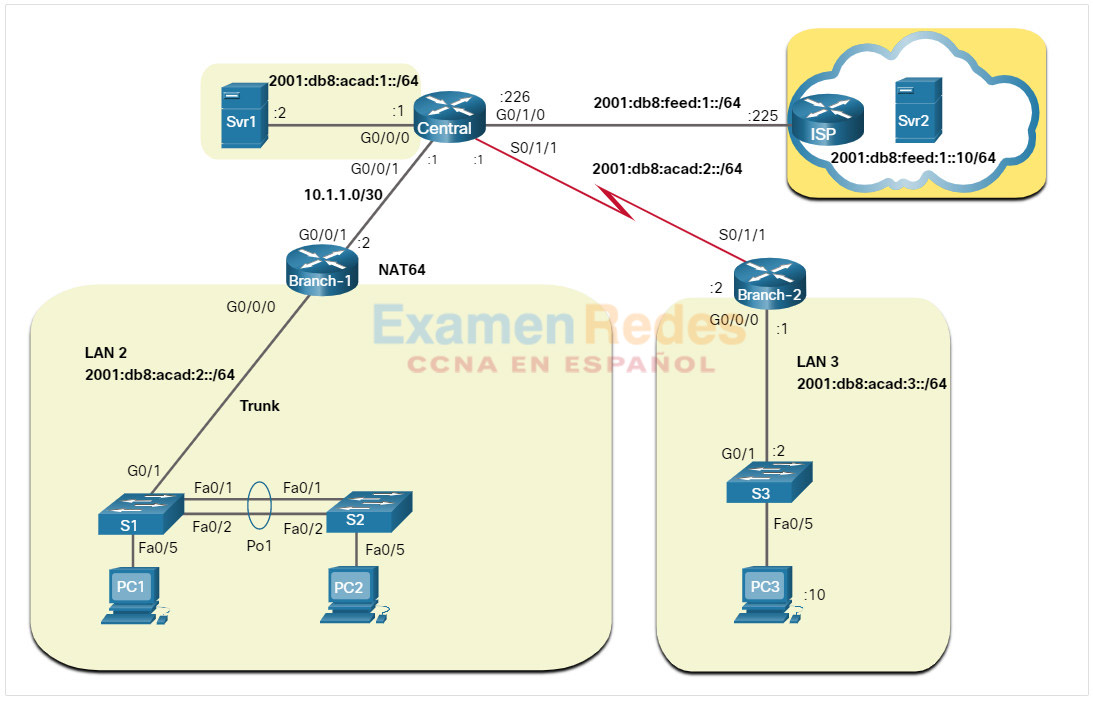
Si bien las direcciones IPv6 también se podrían mostrar en la misma topología, puede resultar más claro crear un diagrama separado de topología lógica de red IPv6.
La figura muestra un ejemplo de topología lógica IPv6
12.1.3. Documentación de dispositivos de red
La documentación de red debería contener registros precisos y actualizados del hardware y el software usados en una red. La documentación debe incluir toda la información pertinente sobre los dispositivos de red.
Muchas organizaciones crean documentos con tablas u hojas de cálculo para capturar información relevante del dispositivo.
Haga clic en cada botón para ver ejemplos de documentación del router, el switch y el dispositivo final.
- Documentación del Router
- Documentación del Switch LAN
- Registro del Sistema finales
La tabla muestra un ejemplo de la documentación de dos routers interconectados.
| Dispositivo | Modelo | Descripción | Ubicación | IOS | Licencia | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Central | ISR 4321 | Central Edge Router | Edificio A Rm: 137 | Cisco IOS XE Software, Version 16.09.04 flash:isr4300-universalk9_ias.16.09.04.SPA.bin | ipbasek9 securityk9 | |||||||||
| Interface | Descripción | Dirección IPv4 | Dirección IPv6 | Dirección MAC | Enrutamiento | |||||||||
| G0/0/0 | Se conecta a SVR-1 | 10.0.0.1/30 | 2001:db8:acad:1::1/64 | a03d.6fe1.e180 | OSPF | |||||||||
| G0/0/1 | Se conecta a la Sucursal-1 | 10.1.1.1/30 | 2001:db8:acad:a001::1/64 | a03d.6fe1.e181 | OSPFv3 | |||||||||
| G0/1/0 | Se conecta al ISP | 209.165.200.226/30 | 2001:db8:feed:1::2/64 | a03d.6fc3.a132 | Predeterminada | |||||||||
| S0/1/1 | Se conecta a la Sucursal-2 | 10.1.1.2/24 | 2001:db8:acad:2::1/64 | n/a | OSPFv3 | |||||||||
| Dispositivo | Modelo | Descripción | Sitio | IOS | Licencia | |||||||||
| Sucursal-1 | ISR 4221 | Router de Borde Sucursal-2 | Edificio B Rm: 107 | Cisco IOS XE Software, Version 16.09.04 Flash:ISR4200-UniversalK9.16.09.04.SPA.bin | ipbasek9 securityk9 | |||||||||
| Interfaz | Descripción | Dirección IPv4 | Dirección IPv6 | Dirección MAC | Enrutamiento | |||||||||
| G0/0/0 | Se conecta a S1 | Router-on-a-stick | Router-on-a-stick | a03d.6fe1.9d90 | OSPF | |||||||||
| G0/0/1 | Conecta a Central | 10.1.1.2/30 | 2001:db8:acad:a001::2/64 | a03d.6fe1.9d91 | OSPF | |||||||||
Esta tabla muestra un ejemplo de la documentación de un Switch LAN.
| Dispositivo | Modelo | Descripción | Dirección IP Mgt. | IOS | VTP | ||||||
| S1 | Cisco Catalyst WS-C2960-24TC-L | Siwtch LAN1 de Sucursal-1 | 192.168.77.2/24 | IOS: 15.0 (2) SE7 Image: C2960-LANBASEK9-M | Dominio: CCNA Modo: Server | ||||||
| Puerto | Descripción | Acceso | VLAN | Troncal | EtherChannel | Nativo | Habilitado | ||||
| Fa0/1 | Port-Channel 1 Puerto troncal a S2 Fa0/1 | – | – | Sí | Port-Channel 1 | 99 | Sí | ||||
| Fa0/2 | Port-Channel puerto troncal a S2 Fa0/2 | – | – | Sí | Port-Channel 1 | 99 | Sí | ||||
| Fa0/3 | *** Not in use *** | Sí | 999 | – | – | Apagado | |||||
| Fa0/4 | *** Not in use *** | Sí | 999 | – | – | Apagado | |||||
| Fa0/5 | Puerto de acceso usuario | Sí | 10 | – | – | Sí | |||||
| … | – | – | – | ||||||||
| Fa0/24 | Puerto de acceso usuario | Sí | 20 | – | – | Sí | |||||
| Fa0/24 | *** Not in use *** | Sí | 999 | – | – | Apagar | |||||
| G0/1 | Enlace troncal a la Sucursal-1 | – | – | Sí | – | 99 | Sí | ||||
| G0/2 | *** Not in use *** | Sí | 999 | – | |||||||
Los archivos de configuración del sistema finales se centran en el hardware y el software usados en los dispositivos, como servidores, consolas de administración de red y estaciones de trabajo de los usuarios. Un sistema final configurado incorrectamente puede tener un impacto negativo en el rendimiento general de una red. Por esta razón, tener acceso a la documentación del dispositivo del sistema final puede ser muy útil a la hora de solucionar problemas.
En esta tabla se muestra un ejemplo de información que podría grabarse en un documento de dispositivo del sistema final.
| Dispositivo | SO | Servicios | Dirección MAC | Direcciones IPv4 / IPv6 | Puerta de enlace predeterminado | DNS |
|---|---|---|---|---|---|---|
| SRV1 | MS Server 2016 | SMTP, POP3, Servicios de archivos, DHCP | 5475.d08e.9ad8 | 10.0.0.2/30 | 10.0.0.1 | 10.0.0.1 |
| 2001:db8:acad:1::2/64 | 2001:db8:acad:1::1 | 2001:db8:acad:1::1 | ||||
| SRV2 | MS Server 2016 | HTTP, HTTPS | 5475.d07a.5312 | 209.165.201.10 | 209.165.201.1 | 209.165.201.1 |
| 2001:db8:feed:1::10/64 | 2001:db8:alimentación:1::1 | 2001:db8:feed:1::1 | ||||
| PC1 | MS Windows 10 | HTTP, HTTPS | 5475.d017.3133 | 192.168.10.10/24 | 192.168.10.1 | 192.168.10.1 |
| 2001:db8:acad:1::251/64 | 2001:db8:acad:1::1 | 2001:db8:acad:1::1 | ||||
| … |
12.1.4. Establecer una línea de base
El monitoreo de red permite controlar el rendimiento de la red con respecto a la línea de base predeterminada. Una línea de base se utiliza para establecer el rendimiento normal de la red o del sistema, para determinar la «personalidad» de una red en condiciones normales.
Para establecer una línea de base de rendimiento de la red, es necesario reunir datos sobre el rendimiento de los puertos y los dispositivos que son esenciales para el funcionamiento de la red.
Una línea de base debería responder las siguientes preguntas:
- ¿Cómo funciona la red durante un día normal o promedio?
- ¿Dónde ocurre la mayoría de los errores?
- ¿Qué parte de la red se usa con más frecuencia?
- ¿Qué parte de la red se usa con menos frecuencia?
- ¿Qué dispositivos deben monitorearse? ¿Qué umbrales de alerta deben establecerse?
- ¿Puede la red cumplir con las políticas identificadas?
Medir el rendimiento y la disponibilidad inicial, de los dispositivos de red críticos, permite a los administradores determinar la diferencia entre un rendimiento normal y uno anormal, ya sea cuando la red crece, o el flujo de tráfico cambia. Una línea de base también proporciona información sobre si el diseño actual de la red puede satisfacer los requisitos comerciales. Sin una línea de base, no existe ningún estándar para medir la naturaleza óptima de los niveles de tráfico y congestión de la red.
Un análisis después de establecer una línea de base inicial también tiende a revelar problemas ocultos. Los datos reunidos muestran la verdadera naturaleza de la congestión, o la congestión potencial, en una red. También puede revelar las áreas de la red que están sub-utilizando y, con bastante frecuencia, puede originar esfuerzos para rediseñar la red sobre la base de las observaciones de calidad y capacidad.
La línea de base inicial de rendimiento de la red prepara el terreno para medir los efectos de los cambios en la red y de las tareas de solución de problemas posteriores. Por lo tanto, es importante planificarla cuidadosamente.
12.1.5. Paso 1 – Determinar el tipo de informacion a recopilar
Al establecer la línea de base inicial, comience por seleccionar algunas variables que representen a las políticas definidas. Si se seleccionan demasiados datos, la cantidad de datos puede ser abrumadora, lo que dificulta el análisis. Comience de manera simple y realice ajustes a lo largo del proceso. Algunos puntos de inicio a considerar son la utilización de CPU e interfaces.
12.1.6. Paso 2 – Identifique los dispositvos y puertos de interés
Use la topología de la red para identificar aquellos dispositivos y puertos para los que se deben medir los datos de rendimiento. Dispositivos y puertos de interés incluyen los siguientes:
- Puertos de dispositivos de red que se conectan a otros dispositivos de red
- Servidores
- Usuarios principales
- Cualquier otro elemento que se considere fundamental para las operaciones
Una topología de red logica puede ser útil para identificar los dispositivos y puertos que se deben monitorear. En la figura, el administrador de red ha sobresaltado los dispositivos y puertos de interés basado en la linea de base.
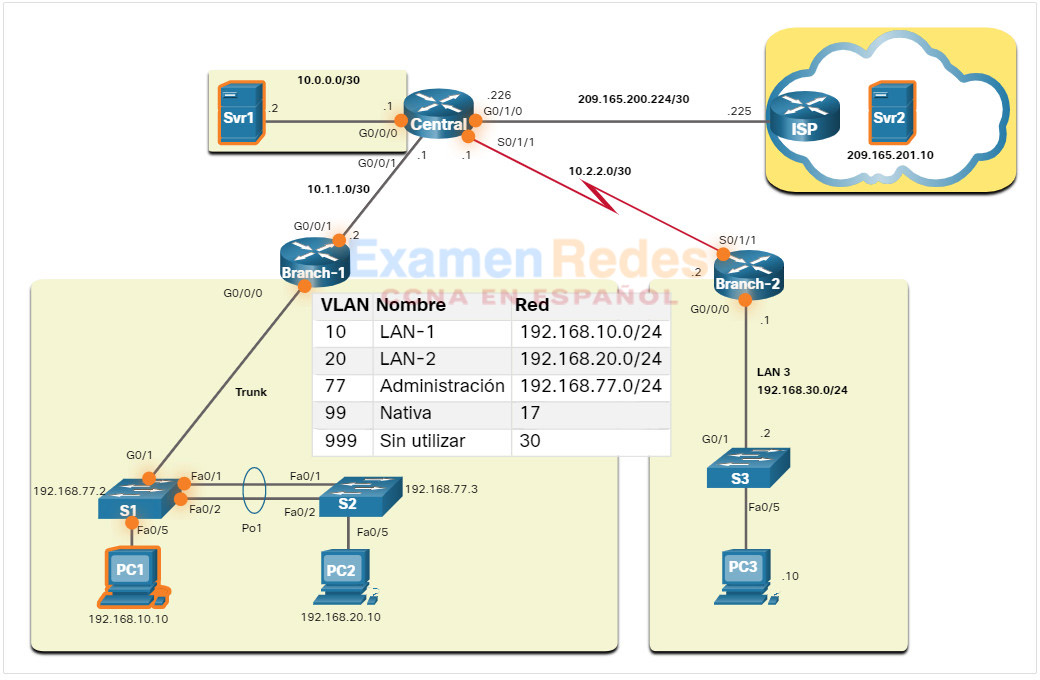
Los dispositivos de interés incluyen la PC1 (la terminal de administración) y los dos servidores (Svr1 y Svr2)el servidor web/TFTP). Los puertos de interés suelen incluir interfaces de router y puertos clave en switches.
Al reducir la lista de puertos que se sondean, los resultados son concisos, y se minimiza la carga de administración de la red. Recuerde que una interfaz en un router o un switch puede ser una interfaz virtual, como una interfaz virtual de switch (SVI).
12.1.7. Paso 3: Determine la duración de la línea de base
La duración y la información que se recolecta, debe ser lo suficientemente larga para determinar que se considera «normal» en la red. Es importante que se monitoreen las tendencias diarias del tráfico de la red. También es importante monitorear las tendencias que se producen durante un período más largo, como semanas o meses. Por este motivo, al capturar datos para su análisis, el período especificado debe tener, como mínimo, una duración de siete días.
En la figura, se muestran ejemplos de varias capturas de pantalla de las tendencias del uso de CPU obtenidas durante un día, una semana, un mes o un año.
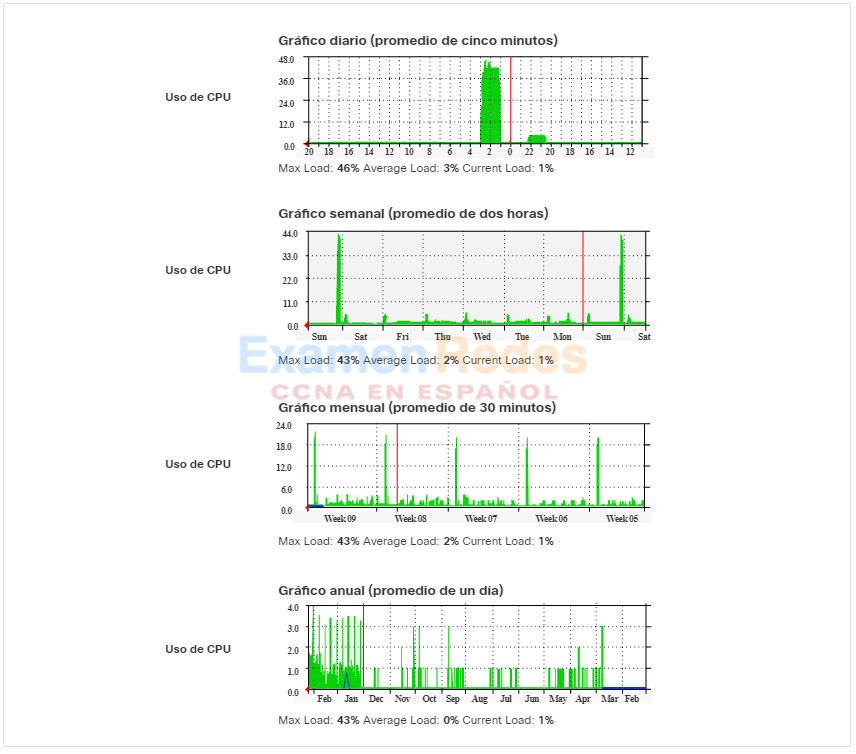
En este ejemplo, observe que las tendencias de la semana de trabajo son demasiado cortas para revelar el pico de uso recurrente que se produce el sábado por la noche, cada fin de semana, cuando una operación de copia de seguridad de la base de datos consume ancho de banda de la red. Este patrón recurrente se revela en la tendencia mensual. Una tendencia anual, como la que se muestra en el ejemplo, puede ser demasiado prolongada para proporcionar detalles significativos sobre el rendimiento de línea de base. Sin embargo, puede ayudar a identificar patrones a largo plazo que se deben analizar en profundidad.
Generalmente, las líneas de base no se deben extender durante más de seis semanas, salvo que se deban medir tendencias específicas a largo plazo. Por lo general, una línea de base de dos a cuatro semanas es adecuada.
Las mediciones de una línea de base no se deben realizar durante momentos de patrones de tráfico únicos, dado que los datos proporcionarían una representación imprecisa de las operaciones normales de la red. Realice un análisis anual de toda la red o bien analice la línea de base de diferentes secciones de la red, de manera rotativa. Para entender la forma en que el crecimiento y otros cambios afectan la red, el análisis se debe realizar periódicamente.
12.1.8. Medición de datos
Al documentar la red, con frecuencia es necesario reunir información directamente de los routers y los switches. Los comandos obvios y útiles para la documentación de red incluyen ping, traceroute, y telnet, así como los siguientes comandos show.
La tabla detalla algunos de los comandos más comunes de Cisco IOS para la recopilación de datos.
| Comando | Descripción |
|---|---|
show version |
Muestra el tiempo de actividad, información sobre la versión del software y del hardware del dispositivo. |
show ip interface [brief]
show ipv6 interface [brief] |
– Muestra todas las opciones de configuración establecidas en una interfaz. – Utilice brief para mostrar la dirección IP y el estado de cada interfaz. |
show interfaces |
– Muestra la salida detallada de cada interfaz. – Para mostrar una salida detallada para una única interfaz, incluya el tipo y el número de interfaz en el comando (por ejemplo, Gigabit Ethernet 0/0/0). |
show ip route |
– Muestra el de contenido de la tabla de enrutamiento de redes directamente conectadas y redes remotas aprendidas. – Agregar static, eigrp o ospf para mostrar sólo esas rutas. |
show cdp neighbors detail |
Muestre información detallada acerca del dispositivo Cisco conectado directamente. |
show arp |
Muestra el contenido de la tabla ARP (IPv4) y la tabla de vecinos (IPv6). |
show running-config |
Muestre la configuración actual. |
show vlan |
Muestra el estado de las VLAN en un switch. |
show port |
Muestra el estado de los puertos en un switch. |
show tech-support |
– Este comando es útil para recopilar una gran cantidad de información sobre el dispositivo para solucionar problemas. – Ejecuta múltiples comandos show que se pueden proporcionar a representantes de soporte técnico cuando se reporta un problema |
La recolección manual de datos mediante los show comandos en dispositivos de red individuales puede tomar muchísimo tiempo y no es una solución escalable. Por esa razón, la recolección manual de datos se debe reservar para las redes más pequeñas o aquellas que se limitan a los dispositivos de red esenciales. Para diseños de red más simples, en las tareas de línea de base por lo general se combinan la recolección manual de datos con protocolos inspección de red simples.
Suele usarse software sofisticado de administración de redes para establecer los valores de referencia de las redes grandes y complejas. Estos programas permiten que los administradores creen y revisen automáticamente los informes, comparen los niveles de rendimiento actuales con las observaciones históricas, identifiquen automáticamente los problemas de rendimiento y creen alertas para las aplicaciones que no proporcionan los niveles esperados de servicio.
Establecer una línea de base inicial o realizar un análisis de monitoreo del rendimiento puede requerir muchas horas o muchos días para reflejar el rendimiento de la red con precisión. Con frecuencia, el software de administración de red o los inspectores y analizadores de protocolos se ejecutan continuamente a lo largo del proceso de recolección de datos.
12.2. Proceso de resolución de problemas
12.2.1. Procedimientos generales de resolución de problemas
La resolución de problemas puede llevar mucho tiempo porque las redes difieren, los problemas difieren y la experiencia de solución de problemas varía. Sin embargo, los administradores experimentados saben que el uso de un método estructurado de resolución de problemas reducirá el tiempo general de resolución de problemas.
Por lo tanto, el proceso de resolución de problemas debe guiarse por métodos estructurados. Esto requiere procedimientos de resolución de problemas bien definidos y documentados, para minimizar el tiempo perdido asociado con la resolución de problemas erráticos. Sin embargo, estos métodos no son estáticos. Los pasos de resolución de problemas realizados para resolver un problema no siempre son los mismos o se ejecutan en el mismo orden.
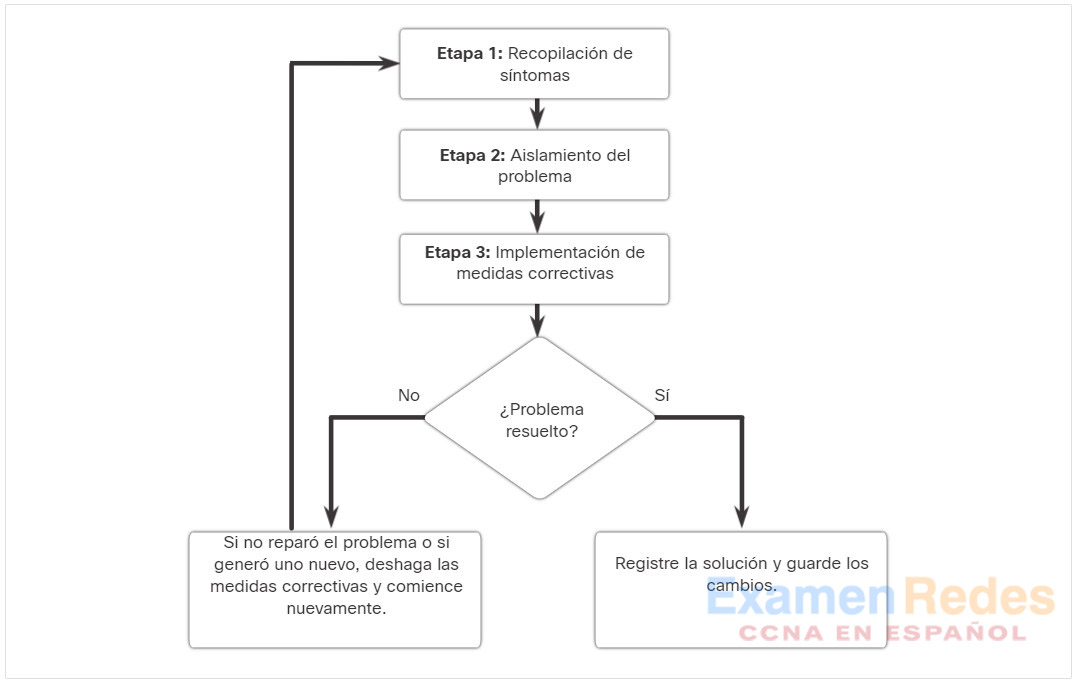
Existen varios procesos de resolución de problemas que se pueden usar para resolver un problema. La figura muestra el diagrama de flujo lógico de un proceso simplificado de resolución de problemas de tres etapas. Sin embargo, un proceso más detallado puede ser más útil para resolver un problema de red.
12.2.2. Proceso de Siete Pasos para la Resolución de Problemas
La figura muestra un proceso de solución de problemas de siete pasos más detallado. Observe cómo se interconectan algunos pasos. Esto se debe a que algunos técnicos pueden saltar entre pasos en función de su nivel de experiencia.
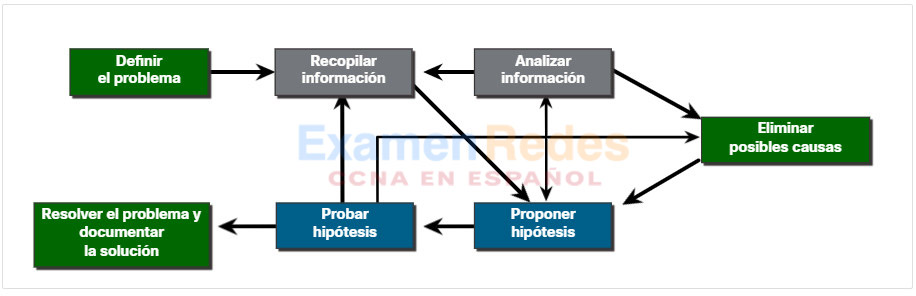
Haga clic en cada botón para obtener una descripción detallada de los pasos para resolver un problema de red.
- Definir el problema
- Recopilar información
- Analizar la información
- Eliminar posibles causas
- Proponer hipótesis
- Probar la hipótesis
- Resolver el problema
El objetivo de esta etapa es verificar que existe un problema y luego definir correctamente cuál es el problema. Los problemas generalmente se identifican por un síntoma (por ejemplo, la red es lenta o ha dejado de funcionar). Los síntomas pueden aparecer de distintas maneras, que incluyen alertas del sistema de administración de red, mensajes de la consola y quejas de los usuarios.
Mientras se recolectan los síntomas, es importante que el administrador de red realice preguntas e investigue el problema para restringirlo a una variedad de posibilidades más reducida. Por ejemplo, ¿el problema se limita a un único dispositivo, un grupo de dispositivos, una subred completa o una red de dispositivos?
En una organización, los problemas suelen asignarse a los técnicos de red mediante tickets de problemas. Estos tickets se crean utilizando software de tickets de problemas que permiten realizar un seguimiento del progreso de cada ticket. El software de creación de tickets de problemas también puede incluir un portal de usuario de autoservicio para enviar tickets, acceso a una base de conocimientos de tickets de problemas, los cuales se pueda buscar, brinda capacidades de control remoto para resolver problemas de los usuarios finales, y mucho más.
En este paso, se deben identificar los dispositivos que se van a investigar, se debe obtener acceso a los dispositivos y se debe recopilar información. En esta etapa, el administrador de red puede recopilar y registrar más síntomas, según las características que se identifiquen.
Si el problema está fuera del límite de control de la organización (por ejemplo, pérdida de conectividad a Internet fuera del sistema autónomo), comuníquese con un administrador del sistema externo antes de recolectar más síntomas de la red.
Las posibles causas deben ser identificadas. La información recopilada se interpreta y analiza utilizando documentación de red, líneas de base de red, búsquedas en bases de conocimiento organizacionales, búsquedas en Internet y conversaciones con otros técnicos.
Si se identifican múltiples causas, entonces la lista debe reducirse eliminando progresivamente las causas posibles, para finalmente identificar la causa más probable La experiencia es extremadamente valiosa para eliminar rápidamente las causas e identificar la causa más probable.
Cuando se ha identificado la causa más probable, se debe formular una solución. En esta etapa, la experiencia de solución de problemas es muy valiosa a la hora de proponer un plan.
Antes de probar la solución, es importante evaluar el impacto y la urgencia del problema. Por ejemplo, ¿podría la solución tener un efecto adverso en otros sistemas o procesos? La gravedad del problema se debe contrastar con el impacto de la solución. Por ejemplo, si un servidor o un router fundamentales deben permanecer sin conexión durante una cantidad significativa de tiempo, tal vez sea mejor esperar hasta el final del día de trabajo para implementar la solución. A veces, se puede crear una solución alternativa hasta que se resuelva el problema real.
Cree un plan de respaldo que identifique cómo invertir rápidamente una solución. Esto puede resultar necesario si la solución falla.
Implementar la solución y verificar que haya resuelto el problema. A veces, una solución introduce un problema inesperado. Por lo tanto, es importante que una solución se verifique a fondo antes de pasar al siguiente paso.
Si la solución falla, se documenta la solución intentada y se eliminan los cambios. Ahora, el técnico debe volver al paso de «recopilar información y eliminar posibles causas».
Comunique a los usuarios y a todos los involucrados en el proceso de resolución que el problema ya está resuelto. La solución se debe informar a los otros miembros del equipo de TI. La documentación adecuada acerca de la causa y la solución ayudan a otros técnicos de soporte a prevenir y resolver problemas similares en el futuro.
12.2.3. Hacer preguntas a usuarios finales.
Muchos problemas de red son notificados inicialmente por un usuario final. Sin embargo, la información facilitada suele ser vaga o engañosa. Por ejemplo, los usuarios suelen informar de problemas como «la red no funciona», «No puedo acceder a mi correo electrónico» o «mi equipo esta lento».
En la mayoría de los casos, se requiere información adicional para comprender completamente un problema. Esto generalmente implica interactuar con el usuario afectado para descubrir el «quién», «qué» y «cuándo» del problema.
Las siguientes recomendaciones deben emplearse al comunicarse con el usuario:
- Hablar a un nivel técnico que puedan entender y evitar el uso de terminología compleja.
- Siempre escuche o lea atentamente lo que el usuario está diciendo. Tomar notas puede ser útil a la hora de documentar un problema complejo.
- Sea siempre considerado y empatice con los usuarios mientras les hace saber que les ayudará a resolver su problema. Los usuarios que informan de un problema pueden estar sometidos a estrés y ansiosos por resolver el problema lo antes posible.
Al entrevistar al usuario, guíe la conversación y use técnicas de cuestionamiento efectivas para determinar rápidamente el problema. Por ejemplo, use preguntas abiertas (es decir, requiere una respuesta detallada) y preguntas cerradas (es decir, sí, no, o respuestas de una sola palabra) para descubrir hechos importantes sobre el problema de la red.
La tabla proporciona algunas directrices/pautas y ejemplos de preguntas para los usuarios finales.
Cuando termine de entrevistar al usuario, repítale lo que usted ha entendido, para asegurarse de que ambos están de acuerdo en el problema que se informa.
| Directrices | Preguntas de ejemplo para los usuarios finales |
|---|---|
| Hacerpreguntas pertinentes. | ¿Qué no esta funcionando? ¿Cuál es exactamente el problema? ¿Qué intenta lograr? |
| Determinar el alcance del problema. | ¿A quién afecta este problema? ¿Solo a usted u otros también? ¿En qué dispositivo está pasando esto? |
| Determine cuándo y con qué frecuencia ocurre u ocurrió el problema. | ¿Cuándo se produjo exactamente el problema? ¿Cuándo notó el problema por primera vez? ¿Se han mostrado mensajes de error? |
| Determine si el problema es constante o intermitente. | ¿Puede reproducir el problema? ¿Puedes enviarme una captura de pantalla o un video del problema? |
| Determine si algo ha cambiado. | ¿Qué se ha modificado desde la última vez que funcionó? |
| Utilizar cada pregunta como un medio para eliminar o descubrir posibles problemas. | ¿Que está funcionando? ¿Qué no está funcionando? |
12.2.4. Recopilar información
Para recopilar los síntomas de un dispositivo de red sospechoso, use los comandos de Cisco IOS y otras herramientas como capturas de paquetes y registros de los dispositivos.
La tabla describe los comandos de Cisco IOS más comunes que se usan para recopilar los síntomas de un problema de red.
| Comando | Descripción |
|---|---|
ping {host | ip-address} |
Envía un paquete de solicitud de eco a una dirección y espera una respuesta. La variable host o ip-address es el alias o la dirección IP del sistema objetivo. |
traceroute destination |
Identifica la ruta que recorre un paquete a través de las redes. La variable destination es el nombre de host o la dirección IP del sistema objetivo. |
telnet {host | ip-address} |
Se conecta con una dirección IP usando la aplicación Telnet. Utilice SSH siempre que sea posible en lugar de Telnet. |
ssh -l user-id ip-address |
Se conecta a una dirección IP con SSH. SSH es más seguro que Telnet. |
show ip interface brief |
Muestra un resumen del estado de todas las interfaces en un dispositivo. Útil para identificar rápidamente el direccionamiento IP en todas las interfaces. |
show ip route |
Muestra las tablas de routing IPv4 e IPv6 actuales, que contienen las rutas a todos los destinos de red conocidos |
show protocols |
Muestra los protocolos configurados y muestra los valores globales y estado específico de la interfaz de cualquier protocolo configurado de Capa 3 |
debug |
Muestra una lista de opciones para habilitar o deshabilitar eventos de depuración. |
Nota: El comando debug es una herramienta importante para recopilar síntomas, pero genera tráfico (mensajes de consola) y puede afectar notablemente el rendimiento del dispositivo de red. Si el comando debug debe ejecutarse en el horario de trabajo normal, avise a los usuarios de la red que se está ejecutando una medida de resolución de problemas y que el rendimiento de la red puede verse afectado. Al terminar, recuerde deshabilitar la depuración.
12.2.5. Solución de problemas con modelos en capas
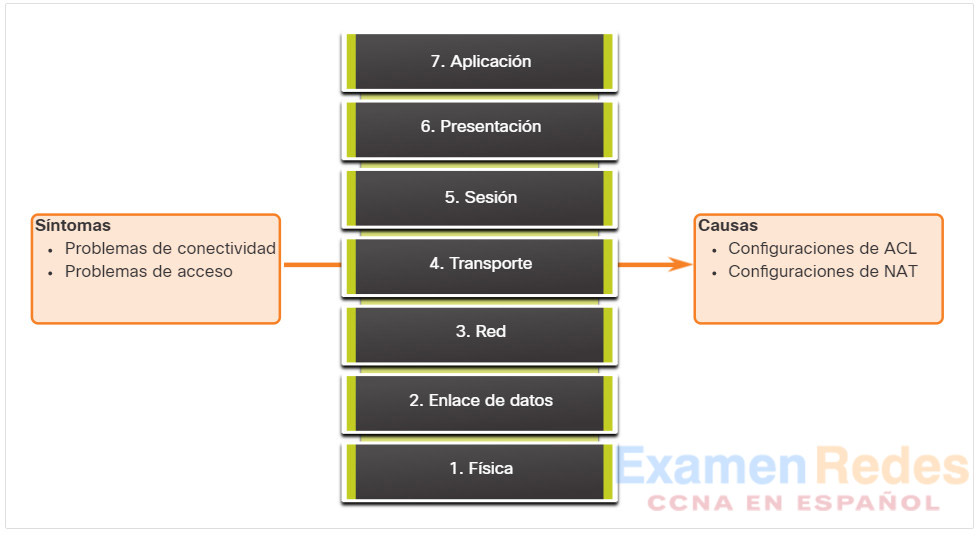
Cuando se realiza la resolución de problemas, se pueden aplicar los modelos OSI y TCP/IP para aislar los problemas de la red. Por ejemplo, si los síntomas sugieren un problema de conexión física, el técnico de red puede concentrarse en la resolución de problemas del circuito que funciona en la capa física.
La figura muestra algunos dispositivos comunes y las capas del modelo OSI que se deben examinar durante el proceso de resolución de problemas de cada dispositivo.
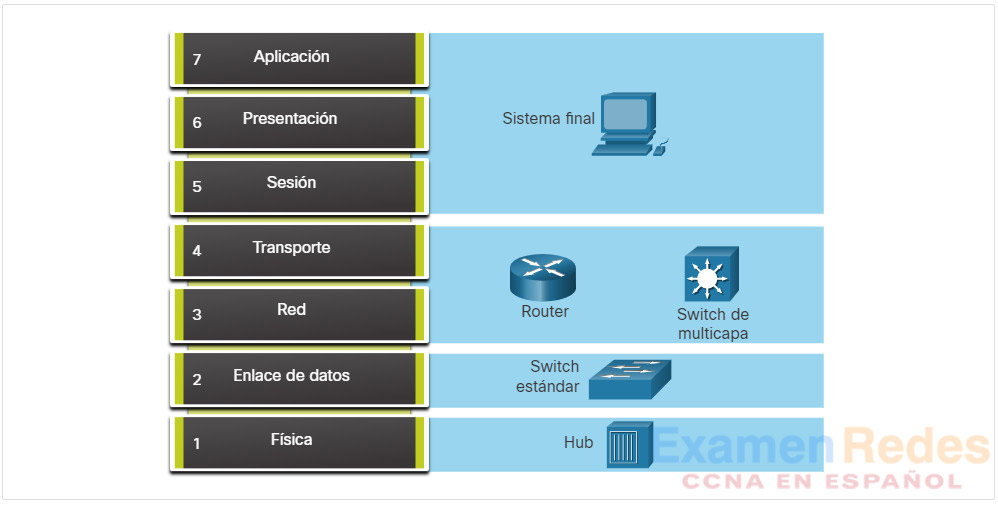
Observe que los routers y los switches multicapa se muestran en la capa 4, la capa de Transporte. Si bien los routers y los switches multicapa generalmente toman decisiones de reenvío en la capa 3, se pueden usar ACL en los mismos para tomar decisiones de filtrado con la información de la capa 4.
12.2.6. Métodos Estructurados de Resolución de problemas
Existen varios enfoques estructurados de resolución de problemas que se pueden utilizar. Cuál usar dependerá de la situación. Cada método tiene sus ventajas y desventajas. En este tema, se describen los tres métodos y se proporcionan pautas para elegir el mejor método para una situación específica.
Haga clic en cada botón para obtener una descripción de los diferentes enfoques de solución de problemas que se pueden utilizar.
- Ascendente
- Descendente
- Divide y vencerás
- Seguimiento de la ruta
- Sustitución
- Comparación
- Deducción informada
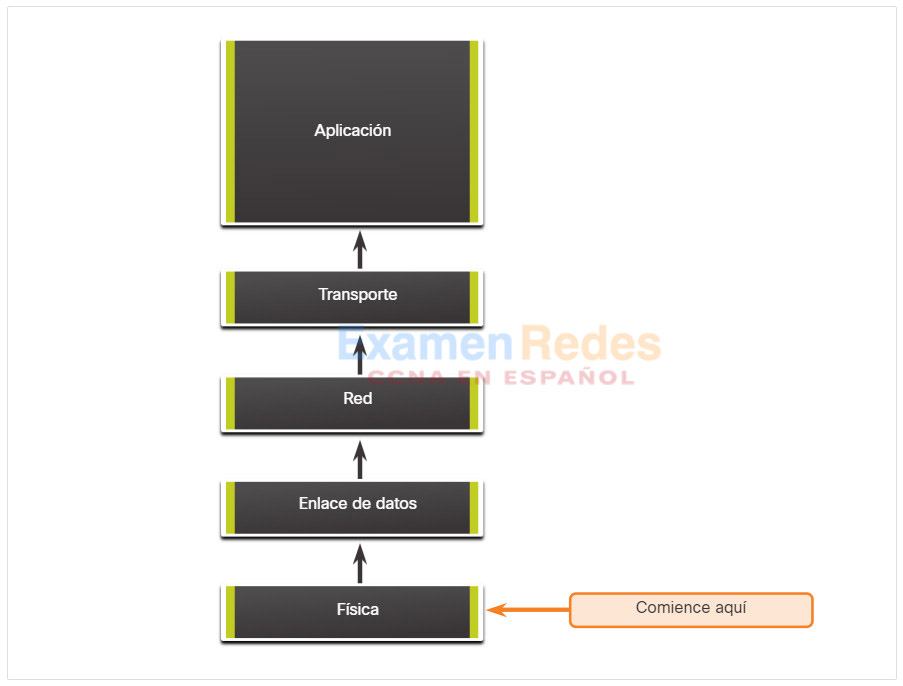
En la resolución de problemas ascendente, se comienza por los componentes físicos de la red y se atraviesan las capas del modelo OSI de manera ascendente hasta que se identifica la causa del problema, como se muestra en la figura.
La resolución de problemas ascendente es un buen método para usar cuando se sospecha que el problema es físico. La mayoría de los problemas de red residen en los niveles inferiores, de modo que, con frecuencia, la implementación del método ascendente es eficaz.
La desventaja del método de resolución de problemas ascendente es que requiere que revise cada dispositivo e interfaz en la red hasta que detecte la posible causa del problema. Recuerde que se debe registrar cada conclusión y cada posibilidad, de modo que es posible que haya mucho papeleo asociado a este enfoque. Otro desafío es determinar qué dispositivos se deben examinar primero.
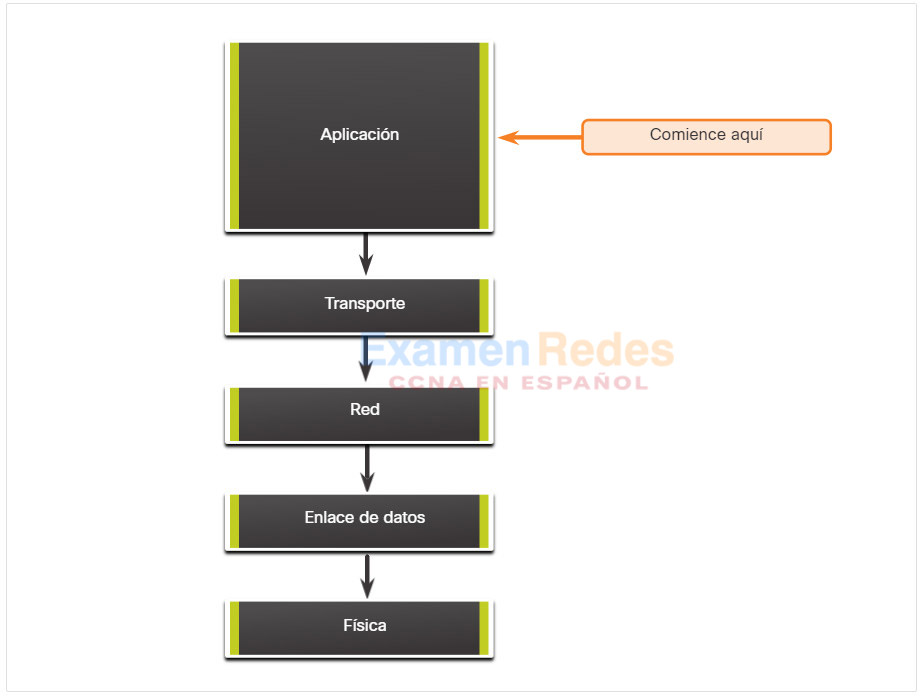
En la figura, la resolución de problemas descendente comienza por las aplicaciones de usuario final y atraviesa las capas del modelo OSI de manera descendente hasta que se identifica la causa del problema.
Antes de abordar las partes más específicas de la red, se prueban las aplicaciones de usuario final. Use este método para los problemas más simples o cuando crea que el problema está en un software.
La desventaja del enfoque descendente es que requiere que se revise cada aplicación de red hasta que se detecte la posible causa del problema. Se debe registrar cada conclusión y cada posibilidad. El desafío es determinar qué aplicación se debe examinar primero.
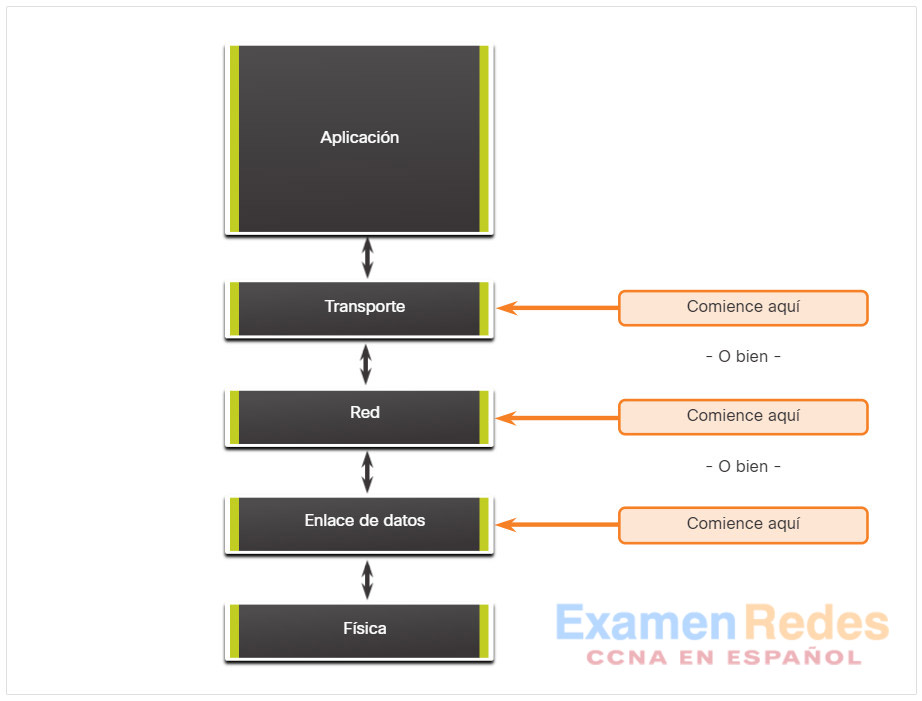
En la figura, se muestra el enfoque divide y vencerás para resolver un problema de red.
El administrador de red selecciona una capa y hace pruebas en ambos sentidos desde esa capa.
En el método de resolución de problemas divide y vencerás, comienza por reunir las experiencias que el usuario tiene del problema, documenta los síntomas y, después, con esa información, hace una deducción fundamentada sobre la capa del modelo OSI en la que se debe comenzar la investigación. Cuando se verifica que una capa funciona correctamente, se puede suponer que las capas por debajo de ella funcionan. El administrador puede trabajar en las capas del modelo OSI en sentido ascendente. Si una capa de OSI no funciona correctamente, el administrador puede descender las capas de OSI.
Por ejemplo, si los usuarios no pueden acceder al servidor web, pero pueden hacer ping al servidor, entonces el problema se encuentra por encima de la capa 3. Si el ping al servidor falla, es probable que el problema esté en una capa inferior del modelo OSI.
Esta es una de las técnicas de solución de problemas más básicas. El enfoque descubre primero la ruta de tráfico real desde el origen hasta el destino. El alcance de la solución de problemas se reduce solo a los enlaces y dispositivos que se encuentran en la ruta de reenvío. El objetivo es eliminar los enlaces y dispositivos que son irrelevantes para la tarea de resolución de problemas. Este enfoque generalmente complementa uno de los otros enfoques.
Este enfoque también se denomina intercambio del componente porque se cambia físicamente el dispositivo problemático por uno conocido y funcional. Si se corrige el problema, el administrador de red sabe que el problema está en el dispositivo que quitó. Si el problema permanece, la causa puede estar en cualquier otro lugar.
En situaciones específicas, este puede ser un método ideal para la resolución rápida de un problema, por ejemplo, cuando queda inactivo un único punto de error crítico. Por ejemplo, un router de borde que falla. En vez de resolver el problema, puede resultar más beneficioso reemplazar el dispositivo y restaurar el servicio.
Si el problema se encuentra en varios dispositivos, es posible que no sea posible aislar correctamente el problema.
Este enfoque también se denomina Encontrar las diferencias e intenta resolver el problema modificando los elementos que no funcionan, para que sean coherentes con los que si funcionan. Puede comparar configuraciones, versiones de software, hardware u otras propiedades de dispositivos, vínculos o procesos entre situaciones que funcionan y no funcionan y detectar diferencias significativas entre ellas.
Si bien este método puede proporcionar una solución que funcione, no revela con claridad la causa del problema.
Este enfoque también se denomina enfoque de resolución de problemas de disparo desde la cadera. Este es un método de solución de problemas menos estructurado que utiliza una conjetura educada basada en los síntomas del problema. El éxito de este método varía en función de su experiencia y capacidad de solución de problemas. Los técnicos experimentados tienen más éxito porque pueden confiar en su amplio conocimiento y experiencia para aislar y resolver problemas de red de manera decisiva. En el caso de un administrador de red menos experimentado, es muy posible que este método sea más parecido a una resolución de problemas al azar.
12.2.7. Pautas para seleccionar un método de resolución de problemas
Para resolver rápidamente los problemas de una red, tómese el tiempo para seleccionar el método más eficaz de resolución de problemas de red.
La figura ilustra qué método se podría utilizar cuando se descubre un cierto tipo de problema.
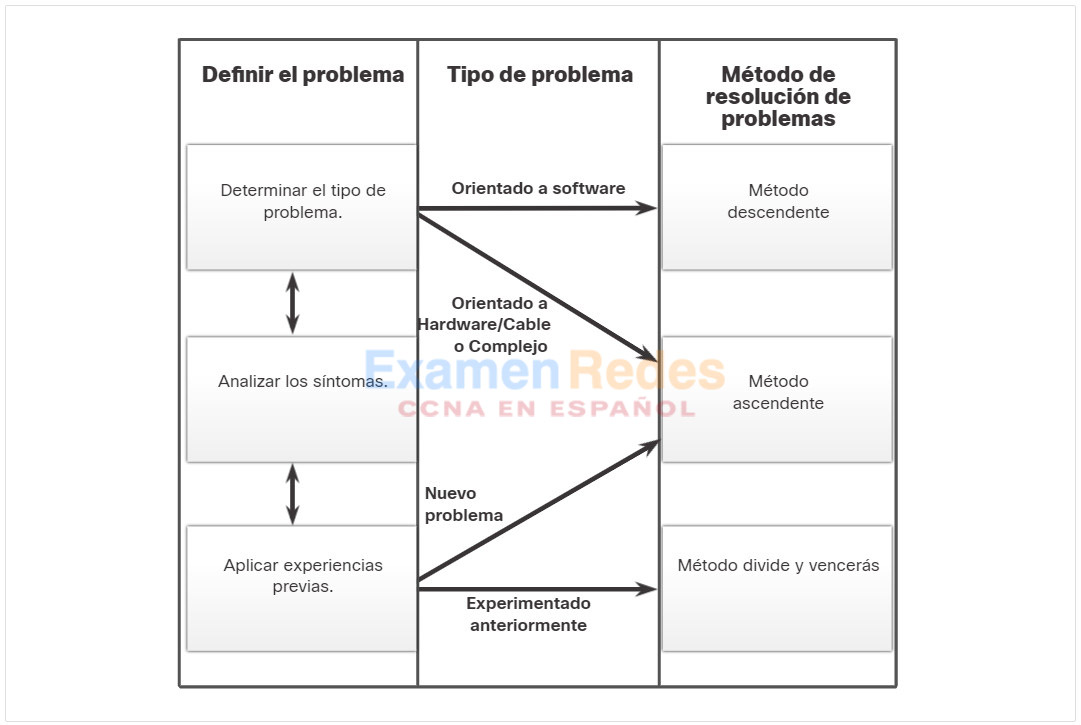
Por ejemplo, los problemas de software a menudo se resuelven utilizando un enfoque descendente mientras que los problemas basados en hardware se resuelven utilizando el enfoque ascendente. Los nuevos problemas pueden ser resueltos por un técnico experimentado utilizando el método de divide y vencerás. De lo contrario, se puede utilizar el enfoque ascendente.
La resolución de problemas es una habilidad que se desarrolla al hacerlo. Cada problema de red que identifique y resuelva se añade a sus habilidades.
12.3. Herramientas para la resolución de problemas
12.3.1. Software de resolución de problemas
Como usted sabe, las redes están formadas por software y hardware. Por lo tanto, tanto el software como el hardware tienen sus respectivas herramientas para la resolución de problemas. En este tema se describen las herramientas de resolución de problemas disponibles para ambas.
Para facilitar la resolución de problemas, hay disponible una amplia variedad de herramientas de hardware y software. Estas herramientas se pueden usar para recolectar y analizar los síntomas de los problemas de red. Con frecuencia, proporcionan funciones de monitoreo y generación de informes que se pueden usar para establecer la línea de base de red.
Haga clic en cada botón para obtener una descripción detallada de las herramientas comunes de solución de problemas de software.
- Herramientas del sistema de administración de red (NMS)
- Bases de conocimientos
- Herramientas de línea de base
Las herramientas de administración de sistemas de red (NMS) incluyen herramientas de monitoreo a nivel de los dispositivos, de configuración y de administración de fallas. Estas herramientas se pueden usar para investigar y corregir los problemas de red. El software de monitoreo de redes ofrece una vista gráfica de los dispositivos de red, lo que permite que los administradores de red monitoreen los dispositivos remotos de manera continua y automática. El sofftware de administración de dispositivos proporciona información dinámica sobre el estado del dispositivo, las estadísticas y la configuración de los principales dispositivos de red. Busque en Internet «Herramientas NMS» para obtener más información.
Las bases de conocimientos en línea de los proveedores de dispositivos de red se volvieron fuentes de información indispensables. Cuando las bases de conocimientos de los proveedores se combinan con motores de búsqueda de Internet, los administradores de red tienen acceso a una vasta fuente de información fundada en la experiencia.
Por ejemplo, la página Cisco Tools & Resources se puede encontrar en http://www.cisco.com bajo el menú Support . Esta página proporciona herramientas que se pueden utilizar para el hardware y el software de Cisco.
Hay numerosas herramientas disponibles para automatizar la documentación de red y el proceso de línea de base. Las herramientas de establecimiento de línea de base ayudan con las tareas de registro frecuentes. Por ejemplo, pueden generar diagramas de red, ayudar a conservar actualizado el registro del software y el hardware de una red y ayudar a medir de forma rentable la línea de base de uso de ancho de banda de la red. Busque en Internet «Herramientas de supervisión de rendimiento de red» para obtener más información.
12.3.2. Analizador de protocolos
Los analizadores de protocolos sirven para examinar el contenido de los paquetes que atraviesan la red. Un analizador de protocolos decodifica las diversas capas del protocolo en una trama registrada y presenta esa información en un formato relativamente fácil de usar. En la ilustración, se muestra una captura de pantalla del analizador de protocolos Wireshark.
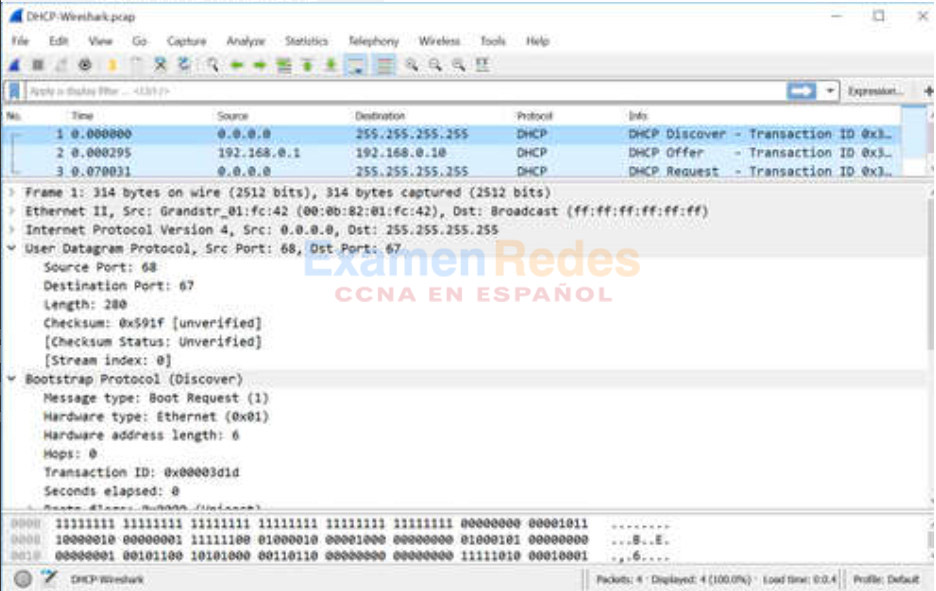
Los analizadores de protocolos muestran información sobre los datos bit físicos, la información de enlaces de datos, protocolos, así como descripciones para cada trama. La mayoría de los analizadores de protocolos pueden filtrar el tráfico que cumple con ciertos criterios, por ejemplo, se puede captar todo el tráfico hacia y desde un dispositivo determinado. Los analizadores de protocolos como Wireshark pueden ayudar a resolver problemas de rendimiento de la red. Es importante tener un buen manejo de TCP/IP y del uso de un analizador de protocolos para examinar la información en cada capa de TCP/IP.
12.3.3. Herramientas de solución de problemas de hardware
Hay varios tipos de herramientas de solución de problemas de hardware.
Haga clic en cada botón para obtener una descripción detallada de las herramientas comunes de solución de problemas de hardware.
- Multímetro digital
- Comprobadores de cables
- Analizador de cables
- Analizadores de red portátiles
- Cisco Prime NAM
Los multímetros digitales, como el Fluke 179, son instrumentos de prueba que se usan para medir directamente los valores eléctricos de voltaje, corriente y resistencia.
En la resolución de problemas de red, la mayoría de las pruebas que conllevan el uso de un multímetro implican el control de los niveles de voltaje de la fuente de alimentación y la verificación de recepción de energia por parte de los dispositivos de red.
Los comprobadores de cables son dispositivos portátiles especializados que están diseñados para probar los diversos tipos de cables de comunicación de datos. La figura muestra el probador automático de redes Fluke LinkRunner AT Network Auto-Tester.
Los comprobadores de cables se pueden utilizar para detectar cables rotos, cables cruzados, conexiones cortas y conexiones incorrectas. Estos dispositivos pueden ser comprobadores de continuidad (económicos), comprobadores de cables de datos (moderados) o bien reflectómetros de dominio de tiempo (TDR – costosos). Los TDR se usan para identificar la distancia a una ruptura en un cable. Estos dispositivos envían señales a lo largo del cable y esperan a que estas se reflejen. El tiempo entre el envío y la recepción de la señal se convierte en una medida de distancia. Normalmente, la función de TDR viene incluida en los comprobadores de cables de datos. Los TDR que se usan para probar los cables de fibra óptica se conocen como “reflectómetros ópticos de dominio de tiempo” (OTDR).
Los analizadores de cables, como el Fluke DTX Cable Analyzer, son dispositivos portátiles con varias funciones que se usan para probar y certificar los cables de cobre y de fibra para los diferentes servicios y estándares.
Las herramientas más sofisticadas incluyen diagnósticos avanzados de solución de problemas que miden la distancia a un defecto de rendimiento como paradiafonía (NEXT) o pérdida de retorno (RL), identifican las medidas correctivas y muestran gráficamente los estados de diafonía e impedancia. Los analizadores de cables también suelen incluir software basado en computadora. Una vez recopilados los datos de campo, los datos del dispositivo portátil pueden cargarse para que el administrador de red genere informes actualizados.
Los dispositivos portátiles, como Fluke OptiView, sirven para solucionar problemas en redes conmutadas y VLAN.
Al conectar el analizador de red en cualquier parte de la red, un ingeniero de red puede ver el puerto de switch al que se conecta el dispositivo, así como el uso promedio y el uso pico. El analizador también se puede usar para conocer la configuración de la VLAN, identificar los participantes principales de la red, analizar el tráfico de la red y ver los detalles de la interfaz. Para un análisis y una resolución de problemas más profundos, el dispositivo debe conectarse a una computadora que tenga instalado un software de supervisión de red.
La cartera de Módulo de análisis de red Cisco Prime (CISCO Prime NAM) (NAM), que se muestra en la figura, incluye hardware y software para el análisis del rendimiento en entornos de switches y routers. Proporciona una interfaz integrada basada en navegador que genera informes sobre el tráfico que consume recursos de red críticos. Además, NAM puede capturar y decodificar paquetes, y medir los tiempos de respuesta para identificar en qué red o servidor en particular se genera el problema de aplicaciones.

12.3.4. Servidor Syslog como herramienta de resolución de problemas
Syslog es un protocolo simple usado por cualquier dispositivo IP, conocido como “cliente syslog”, para enviar mensajes de registro basados en texto a otro dispositivo IP, el servidor de syslog. Actualmente, Syslog se define en RFC 5424.
Implementar una instalación de registro es una parte importante de la seguridad y la resolución de problemas de red. Los dispositivos de Cisco pueden registrar información relacionada con cambios de configuración, infracciones de ACL, estado de interfaces y muchos otros tipos de eventos. Los dispositivos de Cisco pueden enviar mensajes de registro a varias instalaciones. Los mensajes de eventos se pueden enviar a uno o varios de los siguientes componentes:
- Consola – el registro de la consola está activado de manera predeterminada. Los mensajes se registran en la consola y pueden verse al modificar o probar el router o switch con el software de emulación de terminales, conectado al puerto de consolas del dispositivo de red.
- Líneas de las terminales – las sesiones de EXEC habilitadas se pueden configurar para recibir mensajes de registro en cualquiera de las líneas de las terminales. Al igual que el registro de consolas, este tipo de registros no se almacena en el dispositivo de red, por lo que solo sirve al usuario en esa línea.
- El registro con búfer – es un poco más útil como herramienta de solución de problemas porque los mensajes de registro se almacenan en la memoria por un tiempo. Sin embargo, cuando se reinicia el dispositivo, se borran los mensajes de registro.
- Traps de SNMP – ciertos umbrales se pueden configurar previamente en los routers y otros dispositivos. Los eventos de router, que superen el umbral, se pueden procesar en el router y reenviar como notificaciones de SNMP a una estación de administración de redes SNMP externa. Las traps de SNMP son una instalación de registro de seguridad viable, pero requieren la configuración y el mantenimiento de un sistema SNMP.
- Syslog – los routers y los switches Cisco se pueden configurar para reenviar mensajes de registro a un servicio de syslog externo. Este servicio puede residir en cualquier número de servidores o estaciones de trabajo, incluidos los sistemas basados en Microsoft Windows y Linux. Syslog es la instalación de registro de mensajes más popular, ya que proporciona capacidades de almacenamiento de registro a largo plazo y una ubicación central para todos los mensajes del router.
Los mensajes de registro del IOS de Cisco se clasifican en uno de ocho niveles, como se muestra en la tabla.
| Nivel | Palabra clave | Descripción | Definición | |
|---|---|---|---|---|
| Nivel más alto | 0 | Emergencias | No se puede utilizar el sistema | LOG_EMERG |
| 1 | Alertas | Se necesita una acción inmediata. | LOG_ALERT | |
| 2 | Crítico | Existen condiciones críticas. | LOG_CRIT | |
| 3 | Errores | Existen condiciones de error. | LOG_ERR | |
| 4 | Advertencias | Existen condiciones de advertencia. | LOG_WARNING | |
| Nivel más bajo | 5 | Notificaciones | Condición normal (pero importante). | LOG_NOTICE |
| 6 | Informativos | Solo mensajes informativos. | LOG_INFO | |
| 7 | Depuración | Mensajes de depuración | LOG_DEBUG |
Cuanto menor es el número del nivel, mayor es el nivel de gravedad. De manera predeterminada, todos los mensajes del nivel 0 al 7 se registran en la consola. Si bien la capacidad para ver los registros en un servidor central de syslog es útil para resolver problemas, examinar una gran cantidad de datos puede ser una tarea abrumadora. El comando logging trap level se usa para limitar los mensajes registrados en el servidor syslog según la gravedad. El nivel es el nombre o número de nivel de la severidad. Solo se registran los mensajes de número igual o menor que el nivel de especificado.
En el comando de salida, los mensajes de sistema del nivel 0 (emergencias) al 5 (notificaciones) se envían al servidor de syslog en 209.165.200.225.
R1(config)# logging host 209.165.200.225 R1(config)# logging trap notifications R1(config)# logging on R1(config)#
12.4. Síntomas y causas de los problemas de red
12.4.1. Resolución de problemas de la capa física
Ahora que tiene su documentación, algunos conocimientos sobre los métodos de resolución de problemas y las herramientas de software y hardware para diagnosticar problemas, ¡está listo para comenzar a solucionar problemas! En este tema se tratan los problemas más comunes que encontrará al solucionar problemas de una red.
Los problemas en una red con frecuencia se presentan como problemas de rendimiento. Los problemas de rendimiento indican que existe una diferencia entre el comportamiento esperado y el comportamiento observado y que el sistema no funciona como se espera. Las fallas y las condiciones por debajo del nivel óptimo en la capa física no solo presentan inconvenientes para los usuarios sino que pueden afectar la productividad de toda la empresa. Las redes en las que se dan estos tipos de condiciones por lo general se desactivan. Dado que las capas superiores del modelo OSI dependen de la capa física para funcionar, el administrador de red debe tener la capacidad de aislar y corregir los problemas en esta capa de manera eficaz.
La figura resume los síntomas y las causas de los problemas de red en la capa física.
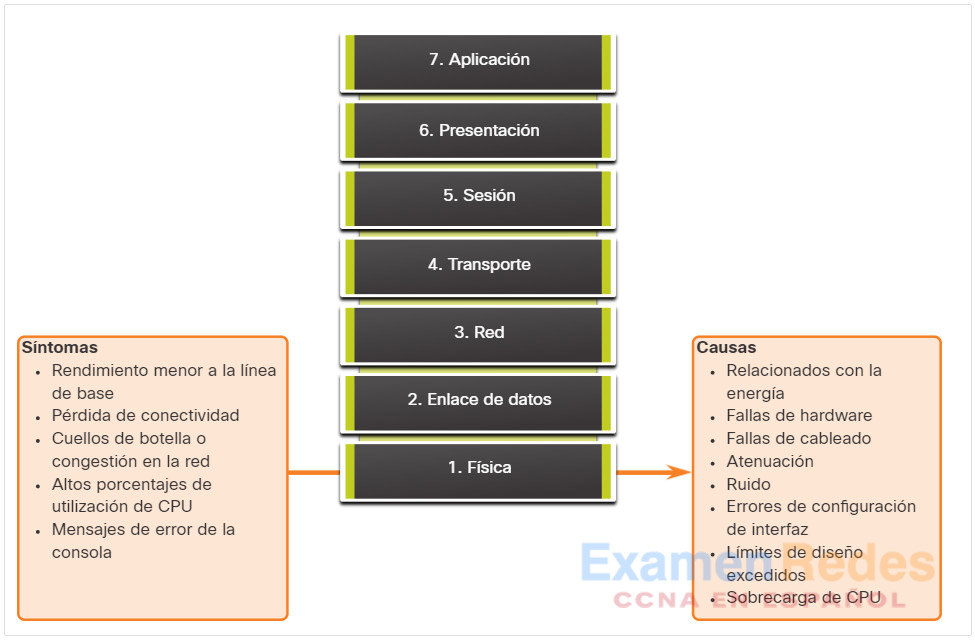
La tabla enumera los síntomas comunes de los problemas de capa física.
| Síntoma | Descripción |
|---|---|
| Rendimiento menor a la línea de base | – Requiere líneas base anteriores para la comparación. – Las razones más comunes para un rendimiento lento o deficiente incluyen servidores sobrecargados o con bajo suministro de energía, switches o routers con configuraciones inadecuadas, congestión del tráfico en un enlace de baja capacidad y pérdida crónica de tramas. |
| Pérdida de conectividad | – La pérdida de conectividad podría deberse a un cable fallido o desconectado. – Se puede verificar mediante una simple prueba de ping. – La pérdida intermitente de la conectividad puede indicar una conexión floja u oxidada. |
| Cuellos de botella o congestión en la red | – Si falla un router, interfaz o cable, los protocolos de enrutamiento pueden redirigir el tráfico a otras rutas que no están diseñadas para transportar la capacidad adicional. – Esto puede provocar congestión o cuellos de botella en partes de la red. |
| Altos porcentajes de utilización de CPU | – Las altas tasas de utilización de la CPU son un síntoma de que un dispositivo, como un router, switch o servidor, está operando a o sobreexcediendo sus limites de diseño. – Si no se aborda rápidamente, la sobrecarga de CPU puede ocasionar que un dispositivo falle o se desactive. |
| Mensajes de error de la consola | – Los mensajes de error notificados en la consola del dispositivo podrían indicar un problema de capa física. – Los mensajes de la consola deben registrarse en un servidor syslog central. |
La tabla enumera los incidentes que comúnmente causan problemas de red en la capa física incluyen los siguientes:
| Causa del problema | Descripción |
|---|---|
| Relacionadas con la alimentación | – Esta es la razón más básica para la falla de la red. – Además, debe revisarse el funcionamiento de los ventiladores y asegurarse de que los orificios de entrada y salida de ventilación del bastidor no estén obstruidos. – Si en otras unidades cercanas también se produce una pérdida de energía, considere la posibilidad de que haya un corte de energía en la fuente de alimentación principal. |
| Fallas de hardware | – Las tarjetas de interfaz de red (NIC) defectuosas pueden ser la causa de que en la red se observen errores de transmisión debidos a colisiones tardías, tramas cortas y jabber. – Jabber a menudo se define como la condición en la que un dispositivo de red transmite continuamente datos aleatorios y sin sentido a la red. – Otras causas probables de jabber son controladores de NIC defectuosos o dañados, cables defectuosos o problemas de conexión a tierra. |
| Fallas de cableado | – Muchos problemas se pueden corregir simplemente volviendo a colocar los cables que están parcialmente desconectados. – Al realizar una inspección física, busque cables dañados, cables incorrectos y conectores RJ-45 mal rizados. – Los cables sospechosos se deben probar o cambiar por un cable que se sepa que funcione. |
| Atenuación | – La atenuación puede producirse si la longitud de un cable supera el límite de diseño o cuando hay una conexión deficiente como resultado de un cable suelto o contactos sucios u oxidados. – Si la atenuación es grave, el dispositivo receptor no siempre puede distinguir correctamente un bit en el flujo de datos de otro bit. |
| Ruido | – La interferencia electromagnética local (EMI) se conoce comúnmente como “ruido”. – El ruido puede ser generado por muchas fuentes, como estaciones de radio FM, la radio policial, la seguridad de los edificios y la aviónica para el aterrizaje automático, crosstalk (ruido inducido por otros cables en la misma vía o cables adyacentes), cables eléctricos cercanos, dispositivos con grandes motores eléctricos, o cualquier cosa que incluya un transmisor más potente que un teléfono celular. |
| Errores de configuración de interfaz | – Muchas cosas pueden estar mal configuradas en una interfaz que hacen que esta deje de funcionar, como por ejemplo frecuencia de reloj incorrecta, fuente de reloj incorrecta y que la interfaz no está activada. – Esto provoca la pérdida de la conectividad a los segmentos de red conectados. |
| Límites de diseño excedidos | – Un componente puede estar operando de manera subóptima en la capa física porque se utiliza más allá de las especificaciones o su capacidad configurada. – Al solucionar este tipo de problema, se hace evidente que los recursos del dispositivo están funcionando en o cerca de la capacidad máxima y hay un aumento en el número de errores en la interfaz. |
| Sobrecarga de CPU | – Los síntomas incluyen procesos con altos porcentajes de utilización de la CPU, caídas de cola de entrada, rendimiento lento, sin acceso remoto o servicios como DHCP, Telnet y ping son lentos o fallan en responder. – En un switch podría ocurrir lo siguiente: reconversión del árbol de extensión, Enlaces EtherChannel que rebotan, intermitencia UDLD, fallos de IP SLAs. – En los routers, se puede producir una interrupción de actualizaciones de routing, o intermitencia de rutas o intermitencia de HSRP. – Una de las causas de la sobrecarga de CPU en un router o switch es el alto nivel de tráfico. – Si una o más interfaces están sobrecargadas regularmente de tráfico, considerar rediseñar el flujo de tráfico en la red o actualizar el hardware. |
12.4.2. Resolución de problemas de la capa de Enlace de datos
La resolución de problemas de capa 2 puede ser un proceso desafiante. La configuración y el funcionamiento de estos protocolos son fundamentales para crear redes con ajustes precisos y funcionales. Los problemas de capa 2 causan síntomas específicos que, al reconocerse, ayudan a identificar el problema rápidamente.
La figura resume los síntomas y las causas de los problemas de red de capa de enlace de datos.
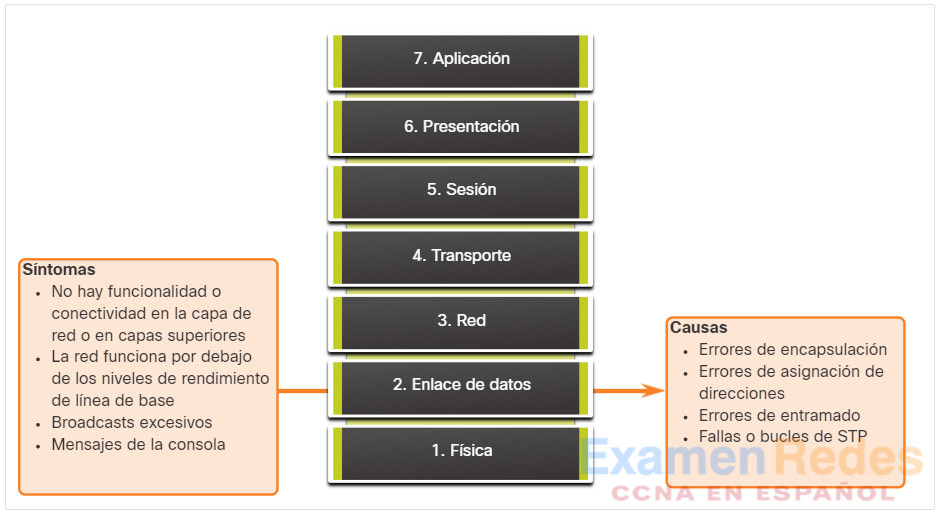
La tabla enumera los síntomas comunes de los problemas de red de capa de enlace de datos.
| Síntoma | Descripción |
|---|---|
| Falta de funcionalidad o conectividad en la capa de red o en capas superiores | Algunos problemas de la capa 2 pueden detener el intercambio de tramas a través de un enlace, mientras que otros solo causan que el rendimiento de la red se deteriore. |
| La red funciona por debajo de los niveles de rendimiento de línea de base | – Hay dos tipos distintos de operaciones subóptimas de capa 2 que puede ocurrir en una red. – En primer lugar, que las tramas elijan una ruta deficiente al destino, pero llegan, haciendo que la red experimente un uso de ancho de banda alto e inesperado en esos enlaces. – En segundo lugar, algunas tramas se eliminan, debido a los contadores de errores y mensajes de error de consola que aparecen en el switch o router. – Un ping extendido o continuo puede ayudar a revelar si las tramas están siendo descartadas. |
| Broadcast excesivos | – Los sistemas operativos utilizan ampliamente broadcast y multicast para descubrir servicios de red y otros hosts. – En general, las emisiones excesivas son el resultado de una mal configuración o programación de las aplicaciones, un gran dominio broadcast de Capa 2 o un problema de red subyacente (por ejemplo, bucles STP o ruta inestable). |
| Mensajes de la consola | – Un router reconoce que se ha producido un problema de Capa 2 y envía mensajes de alerta a la consola. – Normalmente, un router hace esto cuando detecta un problema al interpretar tramas entrantes (problemas de encapsulación) o cuando se esperan keepalives pero no llegan. – El mensaje de la consola más común que indica que existe un problema de Capa 2 es un mensaje que indica que el protocolo de línea está desactivado. |
La tabla enumera los problemas que suelen causar problemas de red en la capa de Enlace de datos.
| Causa del problema | Descripción |
|---|---|
| Errores de encapsulación | – Se produce un error de encapsulación porque los bits colocados en un campo por el remitente no es lo que el receptor espera ver. – Esta condición se produce cuando la encapsulación en un extremo de una WAN se configura de manera diferente a la encapsulación utilizada en el otro extremo. |
| Errores de asignación de direcciones | – En topologías, como punto a multipunto o broadcast Ethernet, es esencial que una dirección de destino de Capa 2 sea asignada a una trama. Esto asegura su llegada de manera correcta al destino. – Para lograr esto, debe coincidir la direccion de destino de capa 3 con la dirección de destino correcta de la capa 2, ya sea usando mapeo estático o dinámico. – En un entorno dinámico, la asignación de capa 2 y capa 3 puede fallar porque los dispositivos pueden haber sido específicamente configurado para no responder a las solicitudes ARP, la información de capa 2 o la de capa 3 almacenada en caché puede haber cambiado físicamente, o respuesta inválidas de ARP se reciben debido a una configuración incorrecta o a un ataque. |
| Errores de entramado | – Las tramas generalmente operan en grupos de bytes de 8-bit. – Un error de entramado se produce cuando una trama no respeta los 8-bit byte como límite. – Cuando sucede esto, el receptor puede tener problemas para determinar donde termina una trama y donde comienza otra trama. – Un número excesivo de tramas no válidas puede impedir a los keepalives válidos ser entregados. – Los errores de entramado pueden ser causados por una línea de serie ruidosa, el diseño incorrecto de un cable (demasiado largo o no blindado adecuadamente), una NIC defectuosa, discordancia dúplex, o un reloj de línea configurado incorrectamente en la unidad de servicio de canal (CSU) |
| Fallas o bucles de STP | – El propósito de STP es resolver una topología física redundante de manera similar a un árbol, mediante el bloqueo de puertos redundantes. – La mayoría de los problemas STP están relacionados con bucles de reenvío que se producen cuando no se bloquean puertos redundantes, por ende el tráfico se reenvía en círculos indefinidamente. Esto causa inundaciones debido a una alta tasa de cambios de topología STP. – Un cambio de topología debería ser un evento inusual, si se configuró de manera correcta la red. – Cuando un enlace entre dos switches se habilita o deshabilita, hay eventualmente un cambio de topología cuando el estado STP del puerto está cambiando hacia o desde Forwarding. – Sin embargo, cuando el estado de un puerto es intermitente esto provoca cambios repetitivos de topología e inundaciones, o una convergencia lenta de STP. – Esto puede ser causado por un diferencia entre la realidad y la documentación de la topología, un error de configuración, como inconsistencia en la configuración de temporizadores STP, una CPU de switch sobrecargada durante la convergencia, o un defecto de software. |
12.4.3. Resolución de problemas de capa de red
Los problemas de capa de red incluyen cualquier problema que implique un protocolo de capa 3, como IPv4, IPv6, EIGRP, OSPF, etc. La figura resume los síntomas y las causas de los problemas de la capa de red.
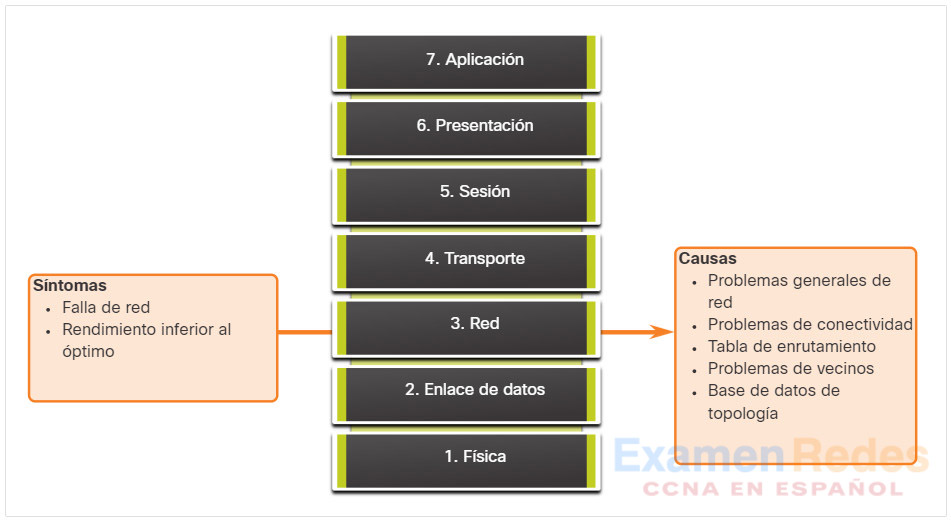
La tabla enumera los síntomas comunes de los problemas la capa de red .
| Síntoma | Descripción |
|---|---|
| Falla de red | – Error de red es cuando la red está casi o completamente no funcional, que afecta a todos los usuarios y aplicaciones de la red. – Estos fallos suelen ser detectados rápidamente por los usuarios y administradores, y obviamente son críticos para la productividad de una empresa. |
| Rendimiento inferior al óptimo | – Los problemas de optimización de red suelen involucrar un subconjunto de usuarios, aplicaciones, destinos o un tipo de tráfico. – Es difícil detectar los problemas de optimización, y son incluso más difíciles de aislar y diagnosticar. – Esto se debe a que varias capas suelen verse involucradas o incluso una única computadora host. – Determinar que el problema se encuentra en la capa de red puede llevar tiempo. |
En la mayoría de las redes, se usan rutas estáticas junto con protocolos de enrutamiento dinámico. La configuración incorrecta de las rutas estáticas puede provocar un enrutamiento deficiente. En algunos casos, las rutas estáticas configuradas incorrectamente pueden generar bucles de enrutamiento, que hacen que algunas partes de la red se vuelvan inalcanzables.
La resolución de problemas de protocolos de enrutamiento dinámico requiere una comprensión profunda de cómo funciona el protocolo de enrutamiento específico. Algunos problemas son comunes a todos los protocolos de enrutamiento, mientras que otros son específicos de un protocolo.
No existe una única plantilla para resolver problemas de capa 3. Los problemas de enrutamiento se resuelven con un proceso metódico, por medio de una serie de comandos para aislar y diagnosticar el problema.
La tabla muestra areas a explorar cuando se diagnostica un posible problema que involucra protocolos de enrutamiento.
| Causa del problema | Descripción |
|---|---|
| Problemas generales de red | – A menudo, un cambio en la topología, como un enlace que falla, puede tener efectos en otras áreas de la red que podrían no ser obvios en el momento. – Esto puede implicar instalar nuevas rutas, estáticas o dinámicas, o la eliminación de otras rutas. – Determine si algo en la red ha cambiado recientemente y si hay alguien trabajando actualmente en la infraestructura de red. |
| Problemas de conectividad | – Compruebe si hay problemas de equipo y conectividad, incluida la alimentación, problemas como cortes de energia y problemas ambientales (por ejemplo, sobrecalentamiento). – También revise si hay problemas de capa 1, como problemas de cableado, daño de puertos y problemas de ISP. |
| Tabla de enrutamiento | – Compruebe si hay algo inesperado en la tabla de enrutamiento, como rutas faltantes o rutas no identificadas. – Use los comandos debug para ver las actualizaciones de enrutamiento y dar mantenimiento a la tabla de enrutamiento. |
| Problemas de vecinos | Si el protocolo de enrutamiento establece una adyacencia con un vecino, marque para ver si hay algún problema con los routers que forman esa adyacencia. |
| Base de datos de topología | Si el protocolo de enrutamiento utiliza una tabla de topología o una base de datos, revise la tabla por cualquier cosa inesperada, como entradas faltantes o inesperadas entradas. |
12.4.4. Resolución de problemas de la capa de transporte: ACL
Los problemas de red pueden surgir a partir de problemas de la capa de transporte en el router, especialmente en el borde de la red, donde se examina y se modifica el tráfico. Por ejemplo, tanto las listas de control de acceso (ACL) como la traducción de direcciones de red (NAT) funcionan en la capa de red y pueden implicar operaciones en la capa de transporte, como se muestra en la figura.
La mayoría de los problemas frecuentes con ACL se debe a una configuración incorrecta, como se muestra en la figura.

Los problemas con las ACL pueden provocar fallas en sistemas que, por lo demás, funcionan correctamente. Comúnmente, las configuraciones incorrectas ocurren en varias áreas:
| Configuraciones incorrectas | Descripción |
|---|---|
| Selección del flujo de tráfico | – El tráfico se define tanto por la interfaz del router a través de la cual el el tráfico está viajando y la dirección en la que este tráfico se mueve. – Se debe aplicar una ACL a la interfaz correcta y la direccion correcta debe seleccionarse para que funcione correctamente. |
| Orden de las entradas de control de acceso | – El orden de las entradas en una ACL debe ir de lo específico a lo general. – Aunque una ACL puede tener una entrada para permitir específicamente un tipo de trafico, los paquetes nunca coinciden con esa entrada si están siendo denegado por otra entrada anterior en la lista. – Si el router está ejecutando ACL y NAT, el orden en que cada una de estas tecnologías se aplica es importante. – La ACL de entrada procesa el tráfico entrante antes de que lo procese la NAT de afuera hacia dentro. – El trafico saliente es procesado por el ACL de salida luego de ser procesados por NAT adentro hacia afuera. |
| Deny any implícito | Cuando no se requiere alta seguridad en la ACL, esta accesp implícito puede ser la causa de una configuración incorrecta de ACL. |
| Dirección y máscaras wildcard IPv4 | – Las máscaras complejas wildcard IPv4 proporcionan mejoras significativas en eficiencia, pero están más sujetos a errores de configuración. – Un ejemplo de una máscara wildcard compleja es el uso de la dirección IPv4 10.0.32.0 y máscara wildcard 0.0.32.15 para seleccionar las primeras 15 direcciones en la red 10.0.0.0 o en la red 10.0.32.0. |
| Selección del protocolo de la capa de transporte | – Al configurar ACLs, es importante selecciona de manera correcta el protocolos de capa de transporte. – Muchos administradores de red, cuando no están seguros de si un tipo de tráfico usa un puerto TCP o un puerto UDP, configure ambos. – Especificar ambos provoca una abertura a través del firewall, lo que posibilita a los intrusos un ingreso la red. – También introduce un elemento adicional en la ACL, por lo que la ACL toma más tiempo en procesar, introduciendo más latencia en la red de comunicaciones. |
| Puertos de origen y destino | – Controlar correctamente el tráfico entre dos hosts requiere elementos de control de acceso simétricos para ACL entrantes y salientes. – Información de dirección y puerto para el tráfico generado por una respuesta de un host es la imagen reflejada de la información de dirección y puerto para el tráfico generado por el host iniciador. |
| Uso de la palabra clave established | – La palabra clave establecida aumenta la seguridad proporcionado por una ACL. – Sin embargo, si la palabra clave se aplica incorrectamente, resultados imprevistos. pueden surgir. |
| Protocolos poco frecuentes | – Las ACL configuradas incorrectamente suelen causar problemas en protocolos distintos a TCP y UDP. – Los protocolos poco frecuentes que están ganando popularidad son VPN y protocolos de encriptación. |
La palabra clave log es un comando útil para ver la operación de las ACL en las entradas de ACL. Esta palabra clave le ordena al router que coloque una entrada en el registro del sistema cada vez que haya una coincidencia con esa condición de entrada. El evento registrado incluye los detalles del paquete que coincidió con el elemento de la ACL. La palabra clave log es especialmente útil para resolver problemas y también proporciona información sobre los intentos de intrusión que la ACL bloquea.
12.4.5. Resolución de problemas de la capa de transporte: NAT para IPv4
Existen varios problemas con NAT, como la falta de interacción con servicios como DHCP y tunneling. Estos pueden incluir la configuración incorrecta de NAT interno, NAT externo o la ACL. Otros problemas incluyen interoperabilidad con otras tecnologías de red, especialmente con aquellas que contienen o derivan información de direccionamiento de red del host en el paquete.
La figura resume areas frecuentes de interoperabilidad con NAT

La tabla enumera áreas frecuentes de interoperabilidad con NAT.
| Síntoma | Descripción |
|---|---|
| BOOTP y DHCP | – Ambos protocolos administran la asignación automática de direcciones IPv4 a clientes. – Recuerde,el primer paquete que un nuevo cliente envía es un paquete IPv4 de broadcast de solicitud de DHCP.. – El paquete de solicitud de DHCP tiene la dirección IPv4 de origen 0.0.0.0. – Debido a que NAT requiere tanto un destino válido como un IPv4 de origen BOOTP y DHCP pueden tener dificultades para operar a través de un router ejecutando NAT estático o dinámico. – La configuración de ip-helper IPv4 puede contribuir a la resolución de este problema. |
| DNS | – Debido a que un router que ejecuta NAT dinámico está cambiando la relación entre direcciones internas y externas regularmente, ya que las entradas de tabla caducan y se vuelven a crear, un servidor DNS fuera del router NAT no tienen una representación precisa de la red dentro del router. – La configuración de ip-helper IPv4 puede contribuir a la resolución de este problema. |
| SNMP | – Al igual que los paquetes DNS, NAT no puede alterar la información de direccionamiento almacenados en los datos del paquete. – Debido a esto, una estación de administración SNMP en un lado de una NAT podria presentar problemas para ponerse en contacto con los agentes SNMP del otro lado de el router NAT. – La configuración deip-helper IPv4 puede contribuir a la resolución de este problema. |
| Protocolos de tunneling y cifrado | – Los protocolos de cifrado y túnel a menudo requieren que el tráfico sea procedente de un puerto UDP o TCP específico, o utilice un protocolo en el capa de transporte que NAT no puede procesar. – Por ejemplo, los protocolos de túnel IPSec y los protocolos enrutamiento de encapsulacion genéricos utilizados por las implementaciones VPN no pueden ser procesado por NAT. |
12.4.6. Resolución de problemas de capa de Aplicación
La mayoría de los protocolos de la capa de aplicación proporcionan servicios para los usuarios. Los protocolos de la capa de aplicación normalmente se usan para la administración de red, la transferencia de archivos, los servicios de archivos distribuidos, la emulación de terminal y el correo electrónico. Con frecuencia, se agregan nuevos servicios para usuarios, como VPN y VoIP.
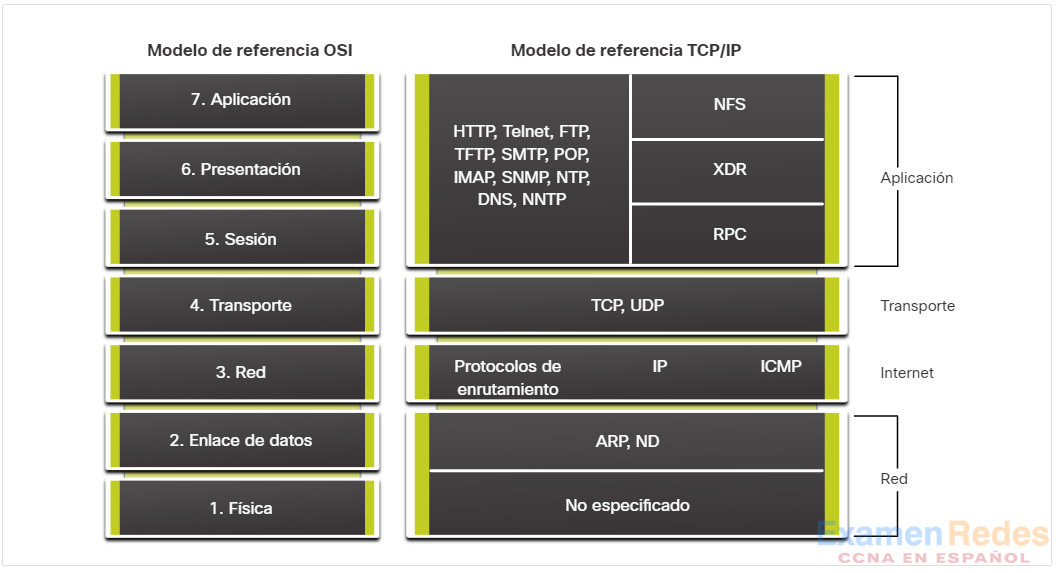
En la ilustración, se muestran los protocolos de capa de aplicación de TCP/IP más conocidos e implementados.
12.5. Resolución de problemas de conectividad IP
12.5.1. Componentes de la resolución de problemas de conectividad de extremo a extremo
En este tema se presenta una topología única y las herramientas para diagnosticar y, en algunos casos, resolver un problema de conectividad de extremo a extremo. Diagnosticar y resolver problemas es una aptitud esencial para los administradores de red. No existe una única receta para la resolución de problemas, y un problema en particular se puede diagnosticar de muchas maneras diferentes. Sin embargo, al emplear un enfoque estructurado para el proceso de resolución de problemas, un administrador puede reducir el tiempo que tarda en diagnosticar y resolver un problema.
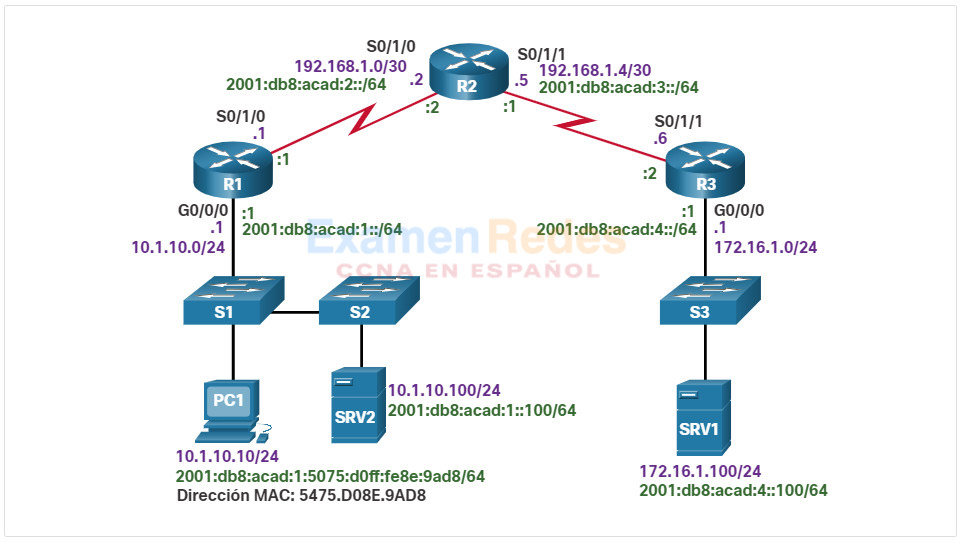
En este tema, se usa la siguiente situación. El host cliente PC1 no puede acceder a las aplicaciones en el servidor SRV1 o el servidor SRV2. En la ilustración, se muestra la topología de esta red. Para crear su dirección IPv6 unicast global, la PC1 usa SLAAC con EUI-64. Para crear la ID de interfaz, EUI-64 usa la dirección MAC de Ethernet, inserta FFFE en el medio e invierte el séptimo bit.
Cuando no hay conectividad de extremo a extremo y el administrador elige resolver problemas con un enfoque ascendente, estos son los pasos frecuentes que el administrador puede seguir:
Paso 1. Revisar la conectividad física en el punto donde se detiene la comunicación de red. Esto incluye los cables y el hardware. El problema podría estar relacionado con un cable o una interfaz defectuosos o con un componente de hardware defectuoso o configurado incorrectamente.
Paso 2. Revisar las incompatibilidades de dúplex.
Paso 3. Revisar el direccionamiento de las capas de enlace de datos y de red en la red local. Esto incluye las tablas ARP de IPv4, las tablas de vecinos IPv6, las tablas de direcciones MAC y las asignaciones de VLAN.
Paso 4. Verificar que el gateway predeterminado sea correcto.
Paso 5. Asegurarse de que los dispositivos determinen la ruta correcta del origen al destino. Si es necesario, se debe manipular la información de enrutamiento.
Paso 6. Verificar que la capa de transporte funcione correctamente. También se puede usar Telnet desde la línea de comandos para probar las conexiones de la capa de transporte.
Paso 7. Verificar que no haya ACL que bloqueen el tráfico.
Paso 8. Asegurarse de que la configuración del DNS sea correcta. Debe haber un servidor DNS accesible.
El resultado de este proceso es deberia proveer conectividad de extremo a extremo. Si se siguieron todos los pasos sin obtener resolución alguna, es posible que el administrador de red desee repetir los pasos anteriores o elevar el problema a un administrador más experimentado.
12.5.2. Problema de conectividad de extremo a extremo inicio de la resolución de problemas
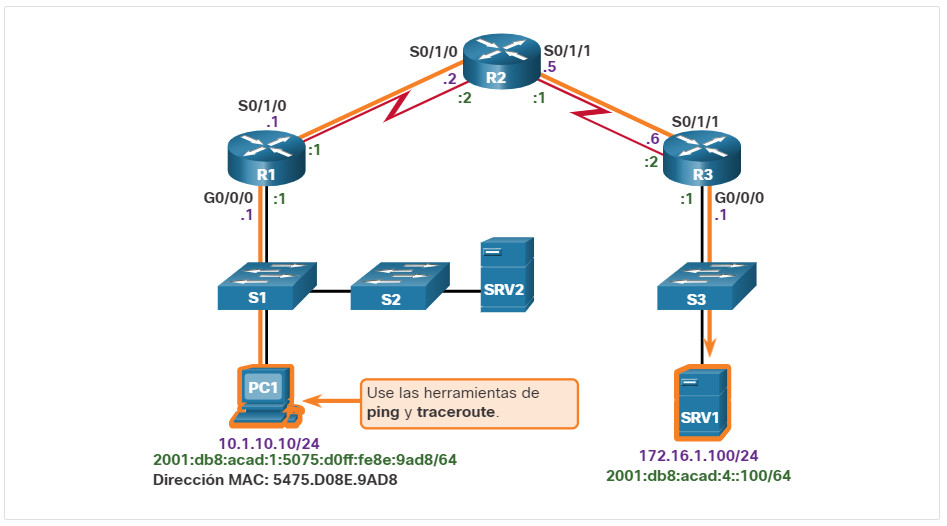
Generalmente, lo que da inicio a un esfuerzo de resolución de problemas es la detección de un problema con la conectividad de extremo a extremo. Dos de las utilidades más comunes que se utilizan para verificar un problema con la conectividad de extremo a extremo son ping y traceroute, que se muestran en la figura.
Haga clic en cada botón para revisar las utilidades ping, traceroute y tracert.
- Ping IPv4
- IPv4 traceroute
- IPv6 ping y traceroute
Es probable que ping sea la utilidad de prueba de conectividad más popular en el ámbito de la tecnología de redes y siempre formó parte del software IOS de Cisco. Esta herramienta envía solicitudes de respuesta desde una dirección host especificada. El comando ping usa un protocolo de capa 3 que forma parte de la suite TCP/IP llamado ICMP. Ping usa la solicitud de eco ICMP y los paquetes de respuesta de eco ICMP. Si el host en la dirección especificada recibe la solicitud de eco ICMP, responde con un paquete de respuesta de eco ICMP. Se puede usar ping para verificar la conectividad de extremo a extremo tanto en IPv4 como en IPv6. Se muestra un ping satisfactorio de la PC1 al SRV1, en la dirección 172.16.1.100.
C:\ > ping 172.16.1.100
Pinging 172.16.1.100 with 32 bytes of data:
Reply from 172.16.1.100: bytes=32 time=199ms TTL=128
Reply from 172.16.1.100: bytes=32 time=193ms TTL=128
Reply from 172.16.1.100: bytes=32 time=194ms TTL=128
Reply from 172.16.1.100: bytes=32 time=196ms TTL=128
Ping statistics for 172.16.1.100:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 193ms, Maximum = 199ms, Average = 195ms
C:\ >
Al igual que el comando ping, el comando traceroute Cisco IOS se puede utilizar tanto para IPv4 como para IPv6. El comando tracert se usa con el sistema operativo Windows. El rastreo genera una lista de saltos, direcciones IP de router y la dirección IP de destino final a las que se llega correctamente a través de la ruta. Esta lista proporciona información importante sobre la verificación y la resolución de problemas. Si los datos llegan al destino, el rastreo indica la interfaz de cada router de la ruta. Si los datos fallan en algún salto de la ruta, se conoce la dirección del último router que respondió al rastreo. Esta dirección es un indicio de dónde se encuentran el problema o las restricciones de seguridad.
El ejemplo tracert muestra la ruta que los paquetes IPv4 toman para llegar al destino.
C:\ > tracert 172.16.1.100 Tracing route to 172.16.1.100 over a maximum of 30 hops: 1 1 ms <1 ms <1 ms 10.1.10.1 2 2 ms 2 ms 1 ms 192.168.1.2 3 2 ms 2 ms 1 ms 192.168.1.6 4 2 ms 2 ms 1 ms 172.16.1.100 Trace complete. C:\ >
Al usarlas, las utilidades del IOS de Cisco reconocen si la dirección en cuestión es IPv4 o IPv6 y usan el protocolo apropiado para probar la conectividad. El resultado del comando muestra los comandos ping y traceroute en el router R1 utilizados para probar la conectividad IPv6.
R1# ping 2001:db8:acad:4::100 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 2001:DB8:ACAD:4::100, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 56/56/56 ms R1# R1# traceroute 2001:db8:acad:4::100 Type escape sequence to abort. Tracing the route to 2001:DB8:ACAD:4::100 1. 2001:DB8:ACAD:2::2 20 mseg 20 mseg 20 mseg 20 mseg 2. 2001:DB8:ACAD:3::2 44 mseg 40 mseg R1#
Note: The El comando command is commonly performed when the traceroute se utiliza cuando el comando command fails. If the ping ha fallado. Si el succeeds, the ping fue exitoso, entonces el comando traceroute no es necesario porque el técnico ya sabe que existe conectividad.
Nota: El comando traceroute se realiza comúnmente cuando falla el comando ping. Si el ping tiene éxito, el comando traceroute generalmente no es necesario porque el técnico sabe que existe conectividad.
12.5.3. Paso 1: Verificar la capa física
Todos los dispositivos de red son sistemas de computación especializados. Como mínimo, estos dispositivos constan de una CPU, RAM y espacio de almacenamiento, que permiten que el dispositivo arranque y ejecute el sistema operativo y las interfaces. Esto permite la recepción y la transmisión del tráfico de la red. Cuando un administrador de red determina que existe un problema en un dispositivo determinado y que el problema puede estar relacionado con el hardware, vale la pena verificar el funcionamiento de estos componentes genéricos. Los comandos de Cisco IOS más utilizados para este propósito son show processes cpu, show memory, y show interfaces. En este tema, se analiza el comando show interfaces .
Cuando se trabajan en problemas relacionados al rendimiento y se sospecha del hardware, el comando show interfaces puede ser usado para revisar las interfaces por las que el trafico pasa.
Consulte el resultado del comando show interfaces .
R1# show interfaces GigabitEthernet 0/0/0 GigabitEthernet0/0/0 is up, line protocol is up Hardware is CN Gigabit Ethernet, address is d48c.b5ce.a0c0(bia d48c.b5ce.a0c0) Internet address is 10.1.10.1/24 (Output omitted) Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0 Queueing strategy: fifo Output queue: 0/40 (size/max) 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec 85 packets input, 7711 bytes, 0 no buffer Received 25 broadcasts (0 IP multicasts) 0 runts, 0 giants, 0 throttles 0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored 0 watchdog, 5 multicast, 0 pause input 10112 packets output, 922864 bytes, 0 underruns 0 output errors, 0 collisions, l interface resets 11 unknown protocol drops 0 babbles, 0 late collision, 0 deferred 0 lost carrier, 0 no carrier, 0 pause output 0 output buffer failures, 0 output buffers swapped out R1#
Haga clic en cada botón para obtener una explicación de la salida resaltada.
- Input queue drops
- Output queue drops
- Input errors
- Output errors
Input queue drops (y los ignored and throttle counters) indican que, en algún momento, se entregó al router más tráfico del que podía procesar. Esto no indica necesariamente un problema. Podría ser normal durante los picos de tráfico. Sin embargo, podría ser una indicación de que la CPU no puede procesar los paquetes a tiempo, por lo que, si este número es permanentemente alto, vale la pena tratar de detectar en qué momentos aumentan estos contadores y cómo se relaciona eso con el uso de CPU.
Output queue drops indican que se descartaron paquetes debido a la congestión en la interfaz. Es normal ver descartes de salida en cualquier punto donde la agregación de tráfico de entrada es superior al tráfico de salida. Durante los picos de tráfico, si el tráfico se entrega a la interfaz más rápidamente de que lo que se puede enviar, se descartan paquetes. Sin embargo, incluso si esto se considera un comportamiento normal, provoca el descarte de paquetes y retrasos en la cola, de modo que es posible que las aplicaciones sensibles a esas situaciones, como VoIP, tengan problemas de rendimiento. Output queue drops frecuentes pueden ser indicio de que se debe implementar un mecanismo de puesta en cola avanzado para aplicar o modificar QoS.
Input errors indican errores que se experimentan durante la recepción de la trama, como errores de CRC. Una cantidad elevada de errores de CRC podría indicar problemas de cableado, problemas de hardware de interfaz o incompatibilidades de dúplex.
Output errors indican errores, como colisiones, durante la transmisión de una trama. En la actualidad, en la mayoría de las redes basadas en Ethernet, la transmisión full-duplex es la norma y la transmisión half-duplex es la excepción. En la transmisión full-duplex, no pueden ocurrir colisiones en las operaciones; por lo tanto, las colisiones (especialmente las colisiones tardías) indican con frecuencia incompatibilidades de dúplex.
12.5.4. Paso 2: Revisar las incompatibilidades de dúplex
Otra causa común de los errores de interfaz es un modo de dúplex incompatible entre los dos extremos de un enlace Ethernet. Actualmente, en numerosas redes basadas en Ethernet, las conexiones punto a punto son la norma, y el uso de hubs y la operación half-duplex asociadas se están volviendo menos frecuentes. Esto significa que, en la actualidad, la mayoría de los enlaces Ethernet operan en modo full-duplex y que, si bien se consideraba que las colisiones eran normales en un enlace Ethernet, hoy en día las colisiones suelen indicar que la negociación de dúplex falló y que el enlace no opera en el modo de dúplex correcto.
El estándar Gigabit Ethernet IEEE 802.3ab exige el uso de la autonegociación para velocidad y dúplex. Además, si bien no es estrictamente obligatorio, casi todas las NIC Fast Ethernet también usan la autonegociación de manera predeterminada. En la actualidad, la práctica recomendada es la autonegociación para velocidad y dúplex.
Sin embargo, si la negociación de dúplex falla por algún motivo, podría ser necesario establecer la velocidad y el dúplex manualmente en ambos extremos. Por lo general, esto conllevaría configurar el modo dúplex en full-duplex en ambos extremos de la conexión. Si esto no funciona, es preferible ejecutar semidúplex en ambos extremos para evitar una diferencia entre dúplex.
Las pautas de configuración de dúplex incluyen:
- Se recomienda la autonegociación de velocidad y dúplex.
- Si la autonegociación falla, configure manualmente la velocidad y el dúplex en los extremos interconectados.
- Los enlaces Ethernet de punto a punto siempre se deben ejecutar en modo full-duplex.
- El semidúplex es inusual y solo suele encontrarse cuando se usan hubs.
Ejemplo de resolución de problemas
En el escenario anterior, el administrador de red tuvo que agregar usuarios adicionales a la red Para incorporar a estos nuevos usuarios, el administrador de red instaló un segundo switch y lo conectó al primero. Poco después de que se agregó el S2 a la red, los usuarios en ambos switches comenzaron a experimentar importantes problemas de rendimiento al conectarse con los dispositivos en el otro switch, como se muestra en la figura.
El administrador de red observa un mensaje de la consola en el switch S2:
*Mar 1 00:45:08.756: %CDP-4-DUPLEX_MISMATCH: duplex mismatch discovered on FastEthernet0/20 (not half duplex), with Switch FastEthernet0/20 (half duplex).
Mediante el comando show interfaces fa 0/20 , el administrador de red examina la interfaz en el S1 usada para conectarse al S2 y observa que está establecida en full-duplex, como se muestra en la figura
S1# show interface fa 0/20 FastEthernet0/20 is up, line protocol is up (connected) Hardware is Fast Ethernet, address is 0cd9.96e8.8a01 (bia 0cd9.96e8.8a01) MTU 1500 bytes, BW 10000 Kbit/sec, DLY 1000 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, loopback not set Keepalive set (10 sec) Full-duplex, Auto-speed, media type is 10/100BaseTX (Output omitted) S1#
Ahora, el administrador de red examina el otro lado de la conexión: el puerto en el S2. Se muestra que este lado de la conexión se configuró como half-duplex.
S2# show interface fa 0/20 FastEthernet0/20 is up, line protocol is up (connected) Hardware is Fast Ethernet, address is 0cd9.96d2.4001 (bia 0cd9.96d2.4001) MTU 1500 bytes, BW 100000 Kbit/sec, DLY 100 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, loopback not set Keepalive set (10 sec) Half-duplex, Auto-speed, media type is 10/100BaseTX (Output omitted) S2(config)# interface fa 0/20 S2(config-if)# duplex auto S2(config-if)#
El administrador de red corrige la configuración y la establece en duplex auto , para que el dúplex se negocie automáticamente. Debido a que el puerto en el S1 se establece en full-duplex, el S2 también usa full-duplex.
Los usuarios informan que ya no existe ningún problema de rendimiento.
12.5.5. Paso 3: Verificar el direccionamiento en la red local
Al resolver problemas de conectividad de extremo a extremo, es útil verificar las asignaciones entre las direcciones IP de destino y las direcciones Ethernet de capa 2 en segmentos individuales. En IPv4, ARP proporciona esta funcionalidad. En IPv6, la funcionalidad de ARP se reemplaza por el proceso de detección de vecinos e ICMPv6. La tabla de vecinos almacena en caché las direcciones IPv6 y sus direcciones físicas de Ethernet (MAC) resueltas.
Haga clic en cada botón para ver un ejemplo y una explicación del comando para verificar el direccionamiento de Capa 2 y Capa 3.
- Tabla ARP IPv4 de Windows
- Tabla de vecinos IPv6 de Windows
- Tabla de vecinos IPv6 de IOS
- Tabla de direcciones MAC del switch
El comando arp de Windows muestra y modifica las entradas en la caché ARP, que se usan para almacenar las direcciones IPv4 y sus direcciones físicas de Ethernet (MAC) resueltas. Como se muestra, el resultado del comando arp de Windows, enumera todos los dispositivos que actualmente están en la caché ARP.
La información que se muestra para cada dispositivo incluye la dirección IPv4, la dirección física (MAC) y el tipo de direccionamiento (estático o dinámico).
Si el administrador de red desea volver a llenar la caché con información actualizada, se puede borrar la caché mediante el comando arp -d de Windows.
Nota: Los comandos arp en Linux y MAC OS X tienen una sintaxis similar.
C:\> arp -a Interface: 10.1.10.100 --- 0xd Internet Address Physical Address Type 10.1.10.1 d4-8c-b5-ce-a0-c0 dynamic 224.0.0.22 01-00-5e-00-00-16 static 224.0.0.251 01-00-5e-00-00-fb static 239.255.255.250 01-00-5e-7f-ff-fa static 255.255.255.255 ff-ff-ff-ff-ff-ff static C:\>
El comando netsh interface ipv6 show neighbor de Windows enumera todos los dispositivos que están actualmente en el caché de la tabla de detección de vecinos.
La información que se muestra para cada dispositivo incluye la dirección IPv6, la dirección física (MAC) y el tipo de direccionamiento. Al examinar la tabla de vecinos, el administrador de red puede verificar que las direcciones IPv6 de destino se asignen a las direcciones Ethernet correctas. Las direcciones IPv6 link-local se configuraron manualmente en todas las interfaces del R1 como FE80::1. De manera similar, se configuró el R2 con la dirección link-local FE80::2 en sus interfaces, y se configuró el R3 con la dirección link-local FE80::3 en sus interfaces. Recuerde que una dirección link-local debe ser única solo en ese enlace o red.
Nota: en los sistemas operativos Linux y MAC OS X, se puede mostrar la tabla de vecinos mediante el comando ip neigh show .
C:\> netsh interface ipv6 show neighbor Internet Address Physical Address Type -------------------------------------------- ----------------- ----------- fe80::9657:a5ff:fe0c:5b02 94-57-a5-0c-5b-02 Stale fe80::1 d4-8c-b5-ce-a0-c0 Reachable (Router) ff02::1 33-33-00-00-00-01 Permanent ff02::2 33-33-00-00-00-02 Permanent ff02::16 33-33-00-00-00-16 Permanent ff02::1:2 33-33-00-01-00-02 Permanent ff02::1:3 33-33-00-01-00-03 Permanent ff02::1:ff0c:5b02 33-33-ff-0c-5b-02 Permanent ff02::1:ff2d:a75e 33-33-ff-2d-a7-5e Permanent
El comando show ipv6 neighbors muestra un ejemplo de la tabla de detección de vecinos en el router Cisco IOS.
Nota: Los estados de los vecinos en IPv6 son más complejos que los estados de la tabla ARP en IPv4. RFC 4861 contiene información adicional.
R1# show ipv6 neighbors IPv6 Address Age Link-layer Addr State Interface FE80::21E:7AFF:FE79:7A81 8 001e.7a79.7a81 STALE Gi0/0 2001:DB8:ACAD:1:5075:D0FF:FE8E:9AD8 0 5475.d08e.9ad8 REACH Gi0/0
Cuando se encuentra una dirección MAC de destino en la tabla de direcciones MAC del switch, el switch reenvía la trama solo al puerto con el dispositivo que tiene esa dirección MAC específica. Para hacer esto, el switch consulta su tabla de direcciones MAC. La tabla de direcciones MAC indica la dirección MAC conectada a cada puerto. Use el comando show mac address-table para visualizar la tabla de direcciones MAC en el switch. Se muestra un ejemplo de tabla de direcciones MAC de switch.
Vale notar que la dirección MAC de PC1, un dispositivo en VLAN 10, se detectó junto con el puerto de switch S1 al que se conecta PC1. Recuerde que la tabla de direcciones MAC de un switch solo contiene información de capa 2, que incluye la dirección MAC de Ethernet y el número de puerto. No se incluye información de dirección IP.
S1# show mac address-table
Mac Address Table
--------------------------------------------
Vlan Mac Address Type Ports
All 0100.0ccc.cccc STATIC CPU
All 0100.0ccc.cccd STATIC CPU
10 d48c.b5ce.a0c0 DYNAMIC Fa0/4
10 000f.34f9.9201 DYNAMIC Fa0/5
10 5475.d08e.9ad8 DYNAMIC Fa0/13
Total Mac Addresses for this criterion: 5
12.5.6. Ejemplo de resolución de problemas de Asignación de VLAN
Al resolver problemas de conectividad de extremo a extremo, otro problema que se debe considerar es la asignación de VLAN. En una red conmutada, cada puerto en un switch pertenece a una VLAN. Cada VLAN se considera una red lógica independiente, y los paquetes destinados a las estaciones que no pertenecen a la VLAN se deben reenviar a través de un dispositivo que admita el enrutamiento. Si el host de una VLAN envía una trama de Ethernet de transmisión, como una solicitud de ARP, todos los host de la misma VLAN recibirán la trama; los host de otras VLAN no la recibirán. Incluso si dos hosts están en la misma red IP, no se podrán comunicar si están conectados a puertos asignados a dos VLAN separadas. Además, si se elimina la VLAN a la que pertenece el puerto, este queda inactivo. Ninguno de los hosts conectados a los puertos que pertenecen a la VLAN que se eliminó se puede comunicar con el resto de la red. Los comandos como show vlan se pueden usar para validar las asignaciones de VLAN en un switch.
Supongamos, por ejemplo, que en un esfuerzo por mejorar la gestión de cables en el armario de cableado, su empresa ha reorganizado los cables que se conectan al switch S1. Casi inmediatamente después de hacerlo, los usuarios comenzaron a llamar al soporte técnico con el comentario de que ya no tenían posibilidad de conexión a los dispositivos fuera de su propia red.
Haga clic en cada botón para obtener una explicación del proceso utilizado para solucionar este problema.
- Revisar la Tabla ARP
- Compruebe la tabla MAC del switch
- Corrija la asignación de VLAN
Un examen de la tabla ARP de la PC1 mediante el comando arp de Windows muestra que la tabla ARP ya no contiene una entrada para el gateway predeterminado 10.1.10.1, como se muestra en la figura
C:\> arp -a Interfaz: 10.1.10.100 — 0xd Internet Address Physical Address Type 224.0.0.22 01-00-5e-00-00-16 static 224.0.0.251 01-00-5e-00-00-fb static 239.255.255.250 01-00-5e-7f-ff-fa static 255.255.255.255 ff-ff-ff-ff-ff-ff static C:\ >
No hubo cambios de configuración en el router, de modo que la resolución de problemas se centra en el S1.
La tabla de direcciones MAC para el S1, muestra que la dirección MAC del R1 está en una VLAN diferente que el resto de los dispositivos en 10.1.10.0/24, incluida la PC1.
S1# show mac address-table
Mac Address Table
--------------------------------------------
Vlan Mac Address Type Ports
All 0100.0ccc.cccc STATIC CPU
All 0100.0ccc.cccd STATIC CPU
1 d48c.b5ce.a0c0 DYNAMIC Fa0/1
10 000f.34f9.9201 DYNAMIC Fa0/5
10 5475.d08e.9ad8 DYNAMIC Fa0/13
Total Mac Addresses for this criterion: 5
S1#
Mientras se volvían a conectar los cables, se trasladó el cable de conexión del R1 de Fa0/4 en la VLAN10 a Fa0/1 en la VLAN 1. El problema se resolvió después de que el administrador de red configuró el puerto FA 0/1 del S1 para que estuviera en la VLAN, como se muestra en la figura. Ahora la tabla de direcciones MAC muestra la VLAN 10 para la dirección MAC del R1 en el puerto Fa 0/1.
S1(config)# interface fa0/1
S1(config-if)# switchport mode access
S1(config-if)# switchport access vlan 10
S1(config-if)# exit
S1#
S1# show mac address-table
Mac Address Table
--------------------------------------------
Vlan Mac Address Type Ports
All 0100.0ccc.cccc STATIC CPU
All 0100.0ccc.cccd STATIC CPU
10 d48c.b5ce.a0c0 DYNAMIC Fa0/1
10 000f.34f9.9201 DYNAMIC Fa0/5
10 5475.d08e.9ad8 DYNAMIC Fa0/13
Total Mac Addresses for this criterion: 5
S1#
12.5.7. Paso 4: Verificar la puerta de enlace predeterminada
Si no hay una ruta detallada en el router o si el host está configurado con la puerta de enlace predeterminada incorrecta, la comunicación entre dos terminales en redes distintas no funciona.
En la figura, se muestra que la PC1 usa el R1 como puerta de enlace predeterminada. De manera similar, el R1 usa al R2 como puerta de enlance predeterminada o como gateway de último recurso. Si un host necesita acceso a recursos que se encuentran más allá de la red local, se debe configurar la puerta de enlace predeterminada. La puerta de enlace predeterminada es el primer router en la ruta a los destinos que se encuentran más allá de la red local.
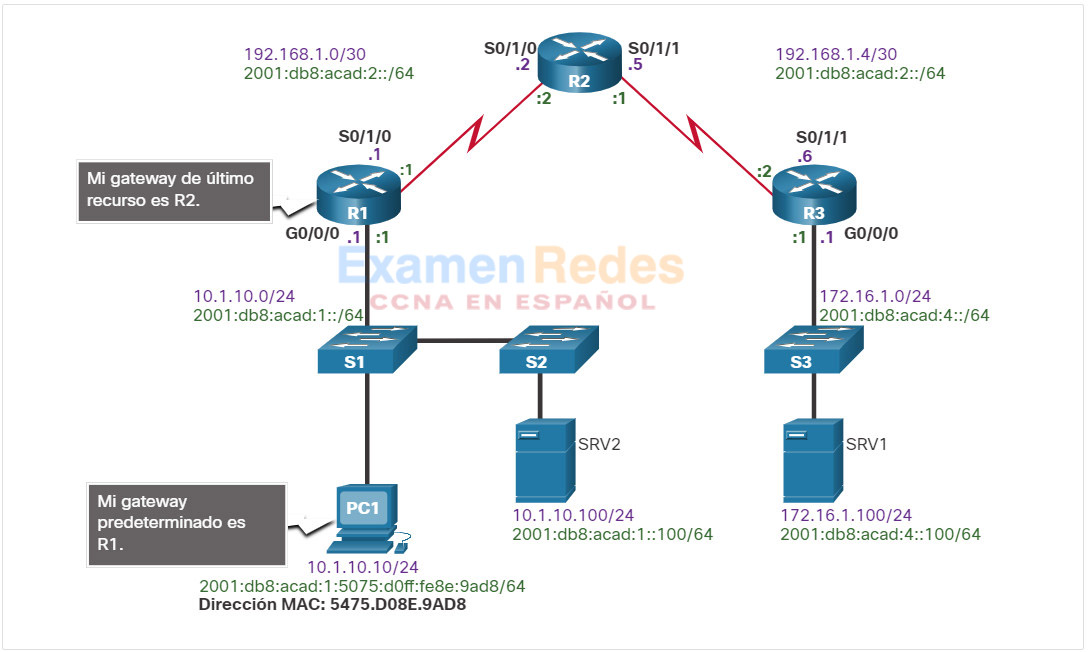
Ejemplo de Resolución de problemas de puerta de enlace predeterminada IPv4
En este ejemplo, R1 tiene la puerta de enlace predeterminada correcta, que es la dirección IPv4 de R2. Sin embargo, la PC1 tiene el gateway predeterminado incorrecto. La PC1 debería tener el gateway predeterminado 10.1.10.1 del router R1. Si la información de direccionamiento IPv4 se configuró en forma manual en la PC1, esto se debe configurar manualmente. Si la información de asignación de direcciones IPv4 se obtuvo automáticamente de un servidor DHCPv4, se deberá examinar la configuración del servidor DHCP. Los problemas de configuración de un servidor DHCP suelen afectar a varios clientes.
Haga clic en cada botón para ver la salida del comando para R1 y PC1.
- Tabla de enrutamiento de R1
- PC1 Tabla de enrutamiento
La salida del comando show ip route Cisco IOS se utiliza para verificar la puerta de enlace predeterminada de R1
R1# show ip route | include gateway|0.0.0.0 Gateway of last resort is 192.168.1.2 to network 0.0.0.0 S* 0.0.0.0/0 [1/0] via 192.168.1.2 R1#
En un host de Windows, el comando route print de Windows, se utiliza para verificar la presencia de la puerta de enlace predeterminada IPv4 como se muestra en la salida del comando.
C:\> route print
(Output omitted)
IPv4 Route Table
===========================================================================
Active Routes:
Network Destination Netmask Gateway Interface Metric
0.0.0.0 0.0.0.0 10.1.10.1 10.1.10.10 11
(Output omitted)
12.5.8. Ejemplo de solución de problemas de la puerta de enlace predeterminada de IPv6
En IPv6, el gateway predeterminado puede configurarse manualmente con la configuración automática independiente del estado (SLAAC) o con DHCPv6. Con SLAAC, el router anuncia el gateway predeterminado a los hosts mediante los mensajes de anuncio de router (RA) ICMPv6. El gateway predeterminado en el mensaje RA es la dirección IPv6 link-local de una interfaz del router. Si el gateway predeterminado se configura manualmente en el host, lo que es muy poco probable, se puede establecer el gateway predeterminado en la dirección IPv6 global o en la dirección IPv6 link-local.
Haga clic en cada botón para ver un ejemplo y una explicación de cómo solucionar un problema de puerta de enlace predeterminada IPv6.
- Tabla de enrutamiento del R1
- Direccionamiento PC1
- Revise la Configuración de interfaz de R1
- Enrutamiento IPv6 en R1 correcto
- Verifique que PC1 tiene un gateway predeterminado IPv6
Como se muestra en la salida del comando, el comando show ipv6 route Cisco IOS se utiliza para comprobar la ruta predeterminada IPv6 en R1. R1 tiene una ruta predeterminada a través de R2.
R1# show ipv6 route (Output omitted) S ::/0 [1/0] via 2001:DB8:ACAD:2::2 R1#
El comando ipconfig de Windows, se utiliza para comprobar que un PC1 tiene una puerta de enlace predeterminada IPv6. En el resultado del comando, a PC1 le falta una dirección unicast global IPv6 y una puerta de enlace predeterminada IPv6. La PC1 está habilitada para IPv6 debido a que tiene una dirección IPv6 link-local. El dispositivo crea automáticamente la dirección link-local. Al revisar la documentación de red, el administrador de red confirma que los hosts en esta LAN deberían recibir la información de dirección IPv6 del router que usa SLAAC.
Nota: En este ejemplo, otros dispositivos que usen SLAAC en la misma LAN también experimentarían el mismo problema al recibir la información de dirección IPv6.
C:\> ipconfig Windows IP Configuration Connection-specific DNS Suffix . : Link-local IPv6 Address . . . .: fe80::5075:d0ff:fe8e:9ad 8% 13 IPv4 Address . . . . . . . . . . : 10.1.10.10 Subnet Mask . . . . . . . . . . : 255.255.255.0 Default Gateway. . . . . . . . . : 10.1.10.1 C:\ >
La salida del comando show ipv6 interface GigabitEthernet 0/0/0 en R1 revela que aunque la interfaz tiene una dirección IPv6, no es miembro del grupo multicast All-IPv6-Routers FF02::2. Esto significa que el router no está habilitado como router IPv6. Por eso no envía RA de ICMPv6 en esta interfaz.
R1# show ipv6 interface GigabitEthernet 0/0/0
GigabitEthernet0/0/0 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::1
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:ACAD:1::1, subnet is 2001:DB8:ACAD:1::/64
Joined group address(es):
FF02:: 1
FF02::1:FF00:1
(Output omitted)
R1#
R1 está habilitado como un router IPv6 mediante el comando ipv6 unicast-routing . El comando show ipv6 interface GigabitEthernet 0/0/0 verifica que R1 sea miembro de ff02::2, el grupo multicast All-IPV6-Routers.
R1(config)# ipv6 unicast-routing
R1(config)# exit
R1# show ipv6 interface GigabitEthernet 0/0/0
GigabitEthernet0/0/0 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::1
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:ACAD:1::1, subnet is 2001:DB8:ACAD:1::/64
Joined group address(es):
FF02:: 1
FF02:: 2
FF02::1:FF00:1
(Output omitted)
R1#
Para verificar que la PC1 tenga configurado el gateway predeterminado, use el comando ipconfig en la PC con Microsoft Windows o el comando netstat -r o ip route en Linux y Mac OS X. La PC1 tiene una dirección IPv6 unicast global y un gateway predeterminado IPv6. El gateway predeterminado se configura en la dirección de enlace local del router R1, FE80::1.
C:\> ipconfig
Windows IP Configuration
Connection-specific DNS Suffix . :
IPv6 Address. . . . . . . . . . : 2001:db8:acad:1:5075:d0ff:fe8e:9ad8
Link-local IPv6 Address . . . .: fe80::5075:d0ff:fe8e:9ad8%13
IPv4 Address . . . . . . . . . . : 10.1.10.10
Subnet Mask . . . . . . . . . . : 255.255.255.0
Default Gateway. . . . . . . . . : fe80::1
10.1.10.1
C:\ >
12.5.9. Paso 5: Verificar la ruta correcta
Al resolver problemas, con frecuencia es necesario verificar la ruta hacia la red de destino. En la figura, se muestra la topología de referencia que indica la ruta deseada para los paquetes de la PC1 al SRV1.
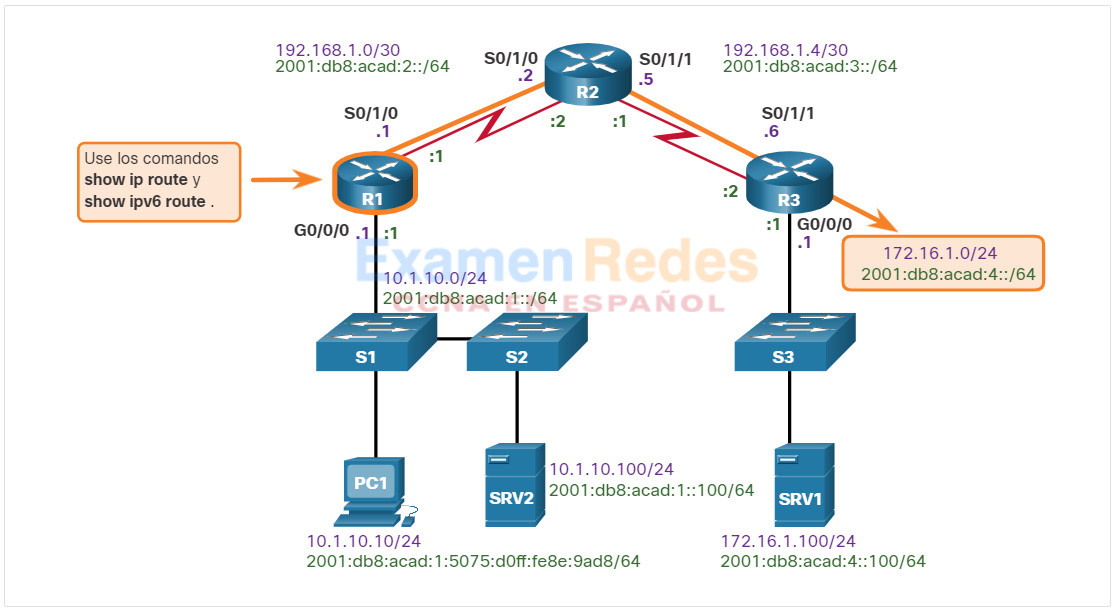
Los routers de la ruta toman la decisión de enrutamiento en función de la información de las tablas de enrutamiento. Haga clic en cada botón para ver las tablas de enrutamiento IPv4 e IPv6 para R1.
- Tabla de routing IPv4 del R1
- Tabla de routing IPv6 del R1
R1# show ip route | begin Gateway
Gateway of last resort is 192.168.1.2 to network 0.0.0.0
O*E2 0.0.0.0/0 [110/1] via 192.168.1.2, 00:00:13, Serial0/1/0
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 10.1.10.0/24 is directly connected, GigabitEthernet0/0/0
L 10.1.10.1/32 is directly connected, GigabitEthernet0/0/0
172.16.0.0/24 is subnetted, 1 subnets
O 172.16.1.0 [110/100] via 192.168.1.2, 00:01:59, Serial0/1/0
192.168.1.0/24 is variably subnetted, 3 subnets, 2 masks
C 192.168.1.0/30 is directly connected, Serial0/1/0
L 192.168.1.1/32 is directly connected, Serial0/1/0
O 192.168.1.4/30 [110/99] via 192.168.1.2, 00:06:25, Serial0/1/0
R1#
R1# show ipv6 route
IPv6 Routing Table - default - 8 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
a - Application
OE2 ::/0 [110/1], tag 1
via FE80::2, Serial0/1/0
C 2001:DB8:ACAD:1::/64 [0/0]
via GigabitEthernet0/0/0, directly connected
L 2001:DB8:ACAD:1::1/128 [0/0]
via GigabitEthernet0/0/0, receive
C 2001:DB8:ACAD:2::/64 [0/0]
via Serial0/1/0, directly connected
L 2001:DB8:ACAD:2::1/128 [0/0]
via Serial0/1/0, receive
O 2001:DB8:ACAD:3::/64 [110/99]
via FE80: :2, Serial0/1/0
O 2001:DB8:ACAD:4::/64 [110/100]
via FE80::2, Serial0/1/0
L FF00::/8 [0/0]
via Null0, receive
R1#
Las tablas de enrutamiento IPv4 e IPv6 se pueden llenar con los siguientes métodos:
- Redes conectadas directamente
- Host locales o rutas locales
- Rutas estáticas
- Rutas dinámicas
- Rutas predeterminadas
El proceso de reenvío de paquetes IPv4 e IPv6 se basa en la coincidencia más larga de bits o de prefijos. El proceso de la tabla de enrutamiento intenta reenviar el paquete mediante una entrada en la tabla de enrutamiento con el máximo número de bits coincidentes en el extremo izquierdo. La longitud de prefijo de la ruta indica el número de bits coincidentes.
La figura describe el proceso de las tablas de enrutamiento IPv4 e IPv6.
Examine los siguientes escenarios basados en el diagrama de flujo anterior. Si la dirección de destino en un paquete:
- No coincide con una entrada en la tabla de enrutamiento, se usa la ruta predeterminada. Si no hay una ruta predeterminada que esté configurada, se descarta el paquete.
- Coincide con una única entrada en la tabla de enrutamiento, el paquete se reenvía a través de la interfaz definida en esta ruta.
- Coincide con más de una entrada en la tabla de enrutamiento y las entradas de enrutamiento tienen la misma longitud de prefijo, los paquetes para este destino se pueden distribuir entre las rutas definidas en la tabla de enrutamiento.
- Coincide con más de una entrada en la tabla de enrutamientoy las entradas de enrutamiento tienen longitudes de prefijo diferentes, los paquetes para este destino se reenvían por la interfaz que está asociada a la ruta que tiene la coincidencia de prefijos más larga.
Ejemplo de resolución de problemas
Los dispositivos no se pueden conectar al servidor SRV1 en 172.16.1.100. Mediante el comando show ip route , el administrador debe revisar si existe una entrada de enrutamiento para la red 172.16.1.0/24. Si la tabla de enrutamiento no tiene una ruta específica a la red del SRV1, el administrador de red debe revisar la existencia de una entrada de red sumarizada o predeterminada en direccion de la red 172.16.1.0/24. Si no existe ninguna entrada, es posible que el problema esté relacionado con el enrutamiento y que el administrador deba verificar que la red esté incluida dentro de la configuración del protocolo de enrutamiento dinámico o que deba agregar una ruta estática
12.5.10. Paso 6: Verificar la capa de transporte
Si la capa de red parece funcionar como se esperaba, pero los usuarios aún no pueden acceder a los recursos, el administrador de red debe comenzar a resolver problemas en las capas superiores. Dos de los problemas más frecuentes que afectan la conectividad de la capa de transporte incluyen las configuraciones de ACL y de NAT. Una herramienta frecuente para probar la funcionalidad de la capa de transporte es la utilidad Telnet.
Precaución: Si bien se puede usar Telnet para probar la capa de transporte, por motivos de seguridad se debe usar SSH para administrar y configurar los dispositivos en forma remota.
Ejemplo de resolución de problemas
Un administrador de red está solucionando un problema en el que no puede conectarse a un router mediante HTTP. El administrador hace ping R2 como se muestra en la salida del comando.
R1# ping 2001:db8:acad:2::2 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 2001:DB8:ACAD:2::2, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 2/2/3 ms R1#
R2 responde y confirma que la capa de red y todas las capas debajo de la capa de red están operativas. El administrador sabe que el problema está en la capa 4 o en las capas superiores y que debe comenzar a resolver problemas en esas capas.
A continuación, el administrador verifica que pueden hacer Telnet a R2 como se muestra en el ejemplo
R1# telnet 2001:db8:acad:2::2 Trying 2001:DB8:ACAD:2::2 ... Open User Access Verification Password: R2> exit [Connection to 2001:db8:acad:2::2 closed by foreign host] R1#
El administrador ha confirmado que los servicios Telnet se ejecutan en R2. Aunque la aplicación de servidor Telnet se ejecute en su propio número de puerto 23 conocido y los clientes de Telnet se conecten a este puerto de manera predeterminada, se puede especificar un número de puerto diferente en el cliente para conectarse a cualquier puerto TCP que deba probarse. Usando un puerto diferente a TCP port 23 indica si la conexión es aceptada, rechazada o termina por falta de confirmación. A partir de cualquiera de estas respuestas, se pueden obtener otras conclusiones relacionadas con la conectividad. En ciertas aplicaciones, si usan un protocolo de sesión basado en ASCII (incluso pueden mostrar un aviso de la aplicación), es posible desencadenar algunas respuestas desde el servidor al escribir ciertas palabras clave, como con SMTP, FTP y HTTP.
Por ejemplo, el administrador intenta hacer Telnet a R2 usando el puerto 80.
R1# telnet 2001:db8:acad:2::2 80 Trying 2001:DB8:ACAD:2::2, 80 ... Open ^C HTTP/1.1 400 Bad Request Date: Mon, 04 Nov 2019 12:34:23 GMT Server: cisco-IOS Accept-Ranges: none 400 Bad Request [Connection to 2001:db8:acad:2::2 closed by foreign host] R1#
Una vez más, en el resultado se verifica una conexión correcta de la capa de transporte, pero R2 rechaza la conexión mediante el puerto 80.
12.5.11. Paso 7: Verificar las ACL
En los routers, puede haber ACL configuradas que prohíben a los protocolos atravesar la interfaz en sentido entrante o saliente.
Use el comando show ip access-lists para visualizar el contenido de todas las ACL de IPv4 y el comando show ipv6 access-list para visualizar el contenido de todas las ACL de IPv6 configuradas en un router. Se puede visualizar una ACL específica al introducir el nombre o el número de la ACL, como una opción de este comando. Los comandos show ip interfaces y show ipv6 interfaces muestran la información de interfaz IPv4 e IPv6 que indica si hay alguna ACL de IP establecida en la interfaz.
Ejemplo de resolución de problemas
Para prevenir los ataques de suplantación de identidad, el administrador de red decidió implementar una ACL para evitar que los dispositivos con la dirección de red de origen 172.16.1.0/24 ingresen a la interfaz de entrada S0/0/1 en el R3, como se muestra en la figura Se debe permitir el resto del tráfico IP.
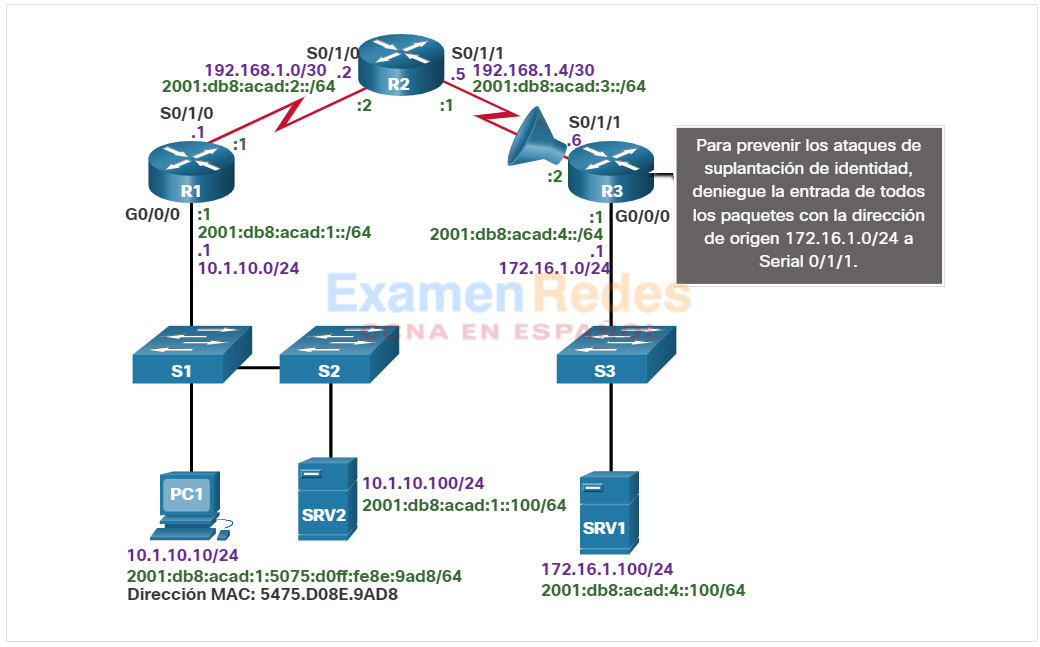
Sin embargo, poco después de implementar la ACL, los usuarios en la red 10.1.10.0/24 no podían conectarse a los dispositivos en la red 172.16.1.0/24, incluido el SRV1.
Haga clic en cada botón para ver un ejemplo de cómo solucionar este problema.
- show ip access-lists
- show ip interfaces
- Correjir el problema.
El comando show ip access-lists muestra que la ACL está configurada correctamente, como se muestra.
R3# show ip access-lists
Extended IP access list 100
10 deny ip 172.16.1.0 0.0.0.255 any (108 matches)
20 permit ip any any (28 matches)
R3#
Podemos verificar qué interfaz tiene la ACL aplicada usando el comando show ip interfaces serial 0/1/1 y el comando show ip interfaces gig 0/0/0. Una investigación más profunda revela que la ACL nunca se aplico a la interfaz de entrada Serial 0/0/1, si no que se aplicó accidentalmente a la interfaz G0/0, lo que bloqueó todo el tráfico saliente de la red 172.16.1.0/24.
R3# show ip interface serial 0/1/1 | include access list Outgoing Common access list is not set Outgoing access list is not set Inbound Common access list is not set Inbound access list is not set R3# R3# show ip interface gig 0/0/0 | include access list Outgoing Common access list is not set Outgoing access list is not set Inbound Common access list is not set Inbound access list is 100 R3#
Una vez ubicada correctamente la ACL IPv4 en la interfaz entrante del puerto Serial 0/1/1, como se muestra en la figura, los dispositivos podrán conectarse con éxito al servidor.
R3(config)# interface GigabitEthernet 0/0/0 R3(config-if)# no ip access-group 100 in R3(config-if)# exit R3(config)# R3(config)# interface serial 0/1/1 R3(config-if)# ip access-group 100 in R3(config-if)# end R3#
12.5.12. Paso 8: Verificar DNS
El protocolo DNS controla el DNS, una base de datos distribuida mediante la cual se pueden asignar nombres de host a las direcciones IP. Cuando configura el DNS en el dispositivo, puede reemplazar el nombre de host por la dirección IP con todos los comandos IP, como ping o telnet.
Para visualizar la información de configuración de DNS en el switch o el router, utilice el comando show running-config . Cuando no hay instalado un servidor DNS, es posible introducir asignaciones de nombres a direcciones IP directamente en la configuración del switch o del router. Utilice el comando ip host para introducir un nombre que se utilizará en lugar de la dirección IPv4 del switch o router, como se muestra en el ejemplo.
R1(config)# ip host ipv4-server 172.16.1.100 R1(config)# exit R1#
Ahora se puede utilizar el nombre asignado en lugar de utilizar la dirección IP, como se muestra en el ejemplo.
R1# ping ipv4-server Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.1.100, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 4/5/7 ms R1#
Para visualizar la información de asignación de nombre a dirección IP en una computadora con Windows, use el comando nslookup .
12.5.13. Packet Tracer – Resolución de problemas de redes empresariales
Esta actividad aplica una variedad de tecnologías que ha visto durante sus estudios de CCNA, incluido el enrutamiento, la seguridad de puertos, EtherChannel, DHCP, NAT, Su tarea consiste en revisar los requisitos, aislar y resolver cualquier problema, y después registrar los pasos que siguió para verificar los requisitos.
12.6. Práctica del Módulo y Cuestionario
12.6.1. Packet Tracer – Desafío de resolución de problemas – Documentación de la red
En esta actividad Packet Tracer, documentará una red desconocida para usted.
- Probará la conectividad de red.
- Compilará la información de direccionamiento del host.
- Accederá de forma remota a los dispositivos de puerta de enlace predeterminados.
- Documentará las configuraciones de dispositivos de puerta de enlace predeterminadas.
- Descubrirá dispositivos en la red.
- Dibujará la topología de la red.
12.6.2. Packet Tracer – Desafío de resolución de problemas – Uso de la documentación para resolver problemas
En esta actividad Packet Tracer, utilizará documentación de red para identificar y solucionar problemas de comunicaciones de red.
- Utilice diversas técnicas y herramientas para identificar problemas de conectividad.
- Utilice la documentación para guiar los esfuerzos de solución de problemas.
- Identificará problemas específicos de red.
- Implementará soluciones a problemas de comunicación de red.
- Verificará el funcionamiento.
12.6.3. Qué aprendí en este módulo?
Documentación de red
La documentación de red común incluye: topologías de red físicas y lógicas, documentación de dispositivos de red que registra toda la información pertinente del dispositivo y documentación de referencia del rendimiento de la red. La información que se encuentra en una topología física suele incluir el nombre del dispositivo, la ubicación del dispositivo (dirección, número de habitación, ubicación del rack, etc.), la interfaz y los puertos utilizados y el tipo de cable. La documentación del dispositivo de red para un router puede incluir la interfaz, la dirección IPv4, la dirección IPv6, la dirección MAC y el protocolo de enrutamiento. La documentación del dispositivo de red para un switch puede incluir el puerto, acceso, VLAN, troncal, EtherChannel, nativo y habilitado. La documentación de dispositivos de red para sistemas finales puede incluir nombre del dispositivo, SO, servicios, dirección MAC, direcciones IPv4 e IPv6, puerta de enlace predeterminada y DNS. Una línea de base inicial debería poder responder las siguiente preguntas:
- ¿Cómo funciona la red durante un día normal o promedio?
- ¿Dónde ocurre la mayoría de los errores?
- ¿Qué parte de la red se usa con más frecuencia?
- ¿Qué parte de la red se usa con menos frecuencia?
- ¿Qué dispositivos deben monitorearse? ¿Qué umbrales de alerta deben establecerse?
- ¿Puede la red cumplir con las políticas identificadas?
Al establecer la línea de base inicial, comience por seleccionar algunas variables que representen a las políticas definidas, como la utilización de las interfaces y el CPU. Un diagrama de topología lógica de la red puede ser útil en la identificación de los dispositivos y los puertos principales que se van a supervisar. La duración y la información que se recolecta, debe ser lo suficientemente larga para determinar que se considera «normal» en la red. Al documentar la red, con frecuencia es necesario recopilar información directamente de los routers y los switches. show, ping, traceroute, y los comandos telnet.
Proceso de resolución de problemas
El proceso de resolución de problemas debe guiarse por métodos estructurados. Un método es el proceso de resolución de problemas de siete pasos: 1. Defina el problema, 2. Recopile información, 3. Analice información, 4. Eliminar posibles causas, 5. Proponga una hipótesis, 6. Pruebe la hipótesis, and 7. Resuelva el problema Cuando hable con los usuarios finales sobre sus problemas de red, haga preguntas abiertas y cerradas. Utilice los comandos show,ping, traceroute, telnet para recopilar información de los dispositivos. Utilice los modelos en capas para la resolución de problemas ascendente, descendente o divide y vencerás. Otros modelos incluyen seguir la ruta, sustitución, comparación y deducciones informadas. Los problemas de software a menudo se resuelven utilizando un enfoque descendente, mientras que los problemas basados en hardware se resuelven utilizando el enfoque ascendente. Los nuevos problemas pueden ser resueltos por un técnico experimentado utilizando el método de divide y vencerás.
Herramientas para la resolución de problemas
Las herramientas comunes de solución de problemas de software incluyen herramientas NMS, bases de conocimiento y herramientas de base de linea. Un analizador de protocolos decodifica las diversas capas del protocolo en una trama registrada y presenta esa información en un formato relativamente fácil de usar. Las herramientas para la solución de problemas de hardware incluyen NAM, multímetros digitales, comprobadores de cables, analizadores de cables y analizadores de red portátiles. El servidor Syslog también se puede utilizar como una herramienta de solución de problemas. Implementar una instalación de registro es una parte importante de la seguridad y la resolución de problemas de red. Los dispositivos de Cisco pueden registrar información relacionada con cambios de configuración, infracciones de ACL, estado de interfaces y muchos otros tipos de eventos. Los mensajes de evento se pueden enviar a una o varias de las siguientes opciones: consola, líneas de terminal, registro en búfer, capturas SNMP y syslog. Cuanto menor es el número del nivel, mayor es el nivel de gravedad. El comando logging trap level se usa para limitar los mensajes registrados en el servidor syslog según la gravedad. El nivel es el nombre o número de nivel de la severidad. Solo se registran los mensajes de número igual o menor que el nivel de especificado.
Síntomas y causas de problemas de red
Las fallas y las condiciones subóptimas en la capa física suelen provocar que las redes fallen. Los administradores de red deben tener la capacidad de aislar y corregir eficazmente los problemas en esta capa. Los síntomas incluyen un rendimiento inferior al previsto, pérdida de conectividad, congestión, alta utilización de CPU y mensajes de error de consola. Las causas suelen estar relacionadas con la alimentación, fallas de hardware, fallas de cableado, atenuación, ruido, errores de configuración de interfaz, excediendo los límites de diseño de componentes y sobrecarga de CPU.
Los problemas de capa 2 causan síntomas específicos que, al reconocerse, ayudan a identificar el problema rápidamente. Los síntomas incluyen la ausencia de funcionalidad/conectividad en la capa 2 o superior, la red que opera por debajo de los niveles de línea base, broadcast excesivos y los mensajes de consola. Las causas suelen ser errores de encapsulación, errores de asignación de direcciones, errores de trama y fallos o bucles STP.
Los problemas de la capa de red incluyen cualquier problema que comprenda a un protocolo de capa3, ya sea un protocolo de enrutado (como IPv4 o IPv6) o un protocolo de enrutamiento (como EIGRP, OSPF, entre otros). Los síntomas incluyen un fallo de red y un rendimiento inferior al óptimo. Las causas suelen ser problemas generales de red, problemas de conectividad, problemas de tabla de enrutamiento, problemas de vecinos y la base de datos de topología.
Los problemas de red pueden surgir a partir de problemas de la capa de transporte en el router, especialmente en el borde de la red, donde se examina y se modifica el tráfico. Los síntomas incluyen problemas de conectividad y acceso. Es probable que las causas sean NAT o ACL mal configuradas. Las configuraciones incorrectas de ACL suelen ocurrir en la selección del flujo de tráfico, el orden de las entradas de control de acceso, la denegación implícita, las direcciones y las máscaras wildcard IPv4, la selección del protocolo de capa de transporte, los puertos de origen y destino, el uso de la palabra clave establecida y los protocolos poco comunes. Hay varios problemas con NAT, incluyendo NAT mal configurado dentro, NAT fuera o ACL. Las áreas de interoperabilidad comunes con NAT incluyen BOOTP y DHCP, DNS, SNMP y protocolos de túnel y encripción.
Cuando la capa física, la capa de enlace de datos, la capa de red y la capa de transporte funcionan, un problema en la capa de aplicación puede tener como consecuencia recursos inalcanzables o inutilizables. Es posible que, teniendo una conectividad de red plena, la aplicación simplemente no pueda proporcionar datos. Otro tipo de problema en la capa de aplicación ocurre cuando las capas física, de enlace de datos, de red y de transporte funcionan, pero la transferencia de datos y las solicitudes de servicios de red de un único servicio o aplicación de red no cumplen con las expectativas normales de un usuario.
Solucionar problemas de conectividad IP
Diagnosticar y resolver problemas es una aptitud esencial para los administradores de red. No existe una única receta para la resolución de problemas, y un problema en particular se puede diagnosticar de muchas maneras diferentes. Sin embargo, al emplear un enfoque estructurado para el proceso de resolución de problemas, un administrador puede reducir el tiempo que tarda en diagnosticar y resolver un problema.
Generalmente, lo que da inicio a un esfuerzo de resolución de problemas es la detección de un problema con la conectividad de extremo a extremo. Dos de las utilidades comunes utilizadas para verificar un problema con la conectividad de extremo a extremo son ping y traceroute. El comando ping utiliza un protocolo de capa 3 que forma parte del conjunto TCP/IP denominado ICMP. El comando traceroute suele ejecutarse cuando falla el comando ping .
Paso 1. Verificar la capa física Los comandos de Cisco IOS más utilizados para este propósito son show processes cpu, show memory, y show interfaces.
Paso 2. Revisar las incompatibilidades de dúplex. Otra causa común de los errores de interfaz es un modo de dúplex incompatible entre los dos extremos de un enlace Ethernet. Actualmente, en numerosas redes basadas en Ethernet, las conexiones punto a punto son la norma, y el uso de hubs y la operación half-duplex asociadas se están volviendo menos frecuentes. Utilice el comando show interfaces interface para diagnosticar este problema.
Paso 3. Verifique el direccionamiento en la red local. Al resolver problemas de conectividad integral, es útil verificar las asignaciones entre las direcciones IP de destino y las direcciones Ethernet de la capa 2 en los segmentos individuales. El comando arp de Windows muestra y modifica las entradas en la caché ARP, que se usan para almacenar las direcciones IPv4 y sus direcciones físicas de Ethernet (MAC) resueltas. El comando netsh interface ipv6 show neighbor de Windows enumera todos los dispositivos que están actualmente en el caché de la tabla de detección de vecinos. El comando show ipv6 neighbors muestra un ejemplo de la tabla de detección de vecinos en el router Cisco IOS. Use el comando show mac address-table para visualizar la tabla de direcciones MAC en el switch.
Al resolver problemas de conectividad de extremo a extremo, otro problema que se debe considerar es la asignación de VLAN. Utilice el comando arp de Windows para ver la entrada de una puerta de enlace predeterminada. Utilice el comando show mac address-table para comprobar la tabla MAC switch. Esto puede mostrar que las asignaciones de VLAN no son correctas.
Paso 4. Verificar la puerta de enlace predeterminado. La salida del comando show ip route Cisco IOS se utiliza para verificar la puerta de enlace predeterminada de un router. En un host de Windows, el comando route print de Windows se utiliza para verificar la presencia de la puerta de enlace predeterminada IPv4.
En IPv6, el gateway predeterminado puede configurarse manualmente con la configuración automática independiente del estado (SLAAC) o con DHCPv6. El comando show ipv6 route Cisco IOS se utiliza para comprobar la ruta predeterminada IPv6 en un router. El comando ipconfig de Windows se utiliza para comprobar si un PC1 tiene una puerta de enlace predeterminada IPv6. El resultado del comando show ipv6 interface interface le indicará si un router está o no habilitado como router IPv6. Habilite un router como router IPv6 mediante el comando ipv6 unicast-routing . Para comprobar que un host tiene la puerta de enlace predeterminada establecida, utilice el comando ipconfig en el PC de Microsoft Windows o el comando netstat -r o ip route en Linux y Mac OS X.
Paso 5. Verificar la ruta correcta Los routers de la ruta toman la decisión de enrutamiento en función de la información de las tablas de enrutamiento. Utilice el comando show ip route | begin Gateway para una tabla de enrutamiento IPv4. Utilice el comando show ipv6 route para una tabla de enrutamiento IPv6.
Paso 6. Verificar la capa de transporte. Dos de los problemas más frecuentes que afectan la conectividad de la capa de transporte incluyen las configuraciones de ACL y de NAT. Una herramienta frecuente para probar la funcionalidad de la capa de transporte es la utilidad Telnet.
Paso 7. Verificar las ACL Use el comando show ip access-lists para visualizar el contenido de todas las ACL de IPv4 y el comando show ipv6 access-list para visualizar el contenido de todas las ACL de IPv6 configuradas en un router. Compruebe qué interfaz tiene aplicada la ACL mediante el comando show ip interfaces .
Paso 8. Verifique el DNS. Para visualizar la información de configuración de DNS en el switch o el router, utilice el comando show running-config . Utilice el comando ip host para introducir un nombre que se utilizará en lugar de la dirección IPv4 del switch o router, como se muestra en el ejemplo.