Última actualización: abril 1, 2022
10.0. Introducción
10.0.1. ¿Por qué debería tomar este módulo?
En este módulo aprenderá acerca de los servicios de red que incluyen DHCP, NAT, PAT, FTP, TFTP, protocolos de correo electrónico y DNS. En un análisis reciente de las amenazas de seguridad de red, se observó que más del 90% del software malicioso que se usa para atacar redes utiliza el sistema DNS para realizar campañas de ataque. Ahora lea más sobre la seguridad de estos protocolos.
10.0.2. ¿Qué aprenderé en este módulo?
Título del módulo: Servicios de red
Objetivos del módulo: Explicar cómo los servicios de red habilitan la funcionalidad de la red.
| Objetivo | Objetivo del tema |
|---|---|
| DHCP | Explique cómo los servicios de DHCP habilitan la funcionalidad de la red. |
| DNS | Explique cómo los servicios de DNS habilitan la funcionalidad de la red. |
| NAT | Explique cómo los servicios de NAT habilitan la funcionalidad de la red. |
| Servicios de transferencia de archivos y uso compartido | Explique cómo los servicios de transferencia de archivos habilitan la funcionalidad de la red. |
| Correo electrónico | Explique cómo los servicios de correo electrónico habilitan la funcionalidad de la red. |
| HTTP | Explique cómo los servicios de HTTP habilitan la funcionalidad de la red. |
10.1. DHCP
10.1.1. Protocolo de configuración dinámica de host
El protocolo DHCP del servicio IPv4 automatiza la asignación de direcciones IPv4, máscaras de subred, puertas de enlace (gateways) y otros parámetros de redes IPv4. Esto se denomina “direccionamiento dinámico”. La alternativa al direccionamiento dinámico es el direccionamiento estático. Al utilizar el direccionamiento estático, el administrador de redes introduce manualmente la información de la dirección IP en los hosts.
Cuando un host se conecta a la red, se realiza el contacto con el servidor de DHCP y se solicita una dirección. El servidor de DHCP elige una dirección de un rango de direcciones configurado llamado grupo y la asigna (concede) al host.
En redes más grandes, o donde los usuarios cambian con frecuencia, se prefiere asignar direcciones con DHCP. Es posible que los nuevos usuarios necesiten conexiones; otros pueden tener PC nuevas que deben estar conectadas. En lugar de usar asignación de direcciones estáticas para cada conexión, es más eficaz que las direcciones IPv4 se asignen automáticamente mediante DHCP.
DHCP puede asignar direcciones IP durante un período de tiempo configurable, denominado período de concesión. El período de concesión es una configuración DHCP importante. Cuando caduca el período de concesión o el servidor DHCP recibe un mensaje DHCPRELASE, la dirección se devuelve al grupo DHCP para su reutilización. Los usuarios pueden moverse libremente desde una ubicación a otra y volver a establecer con facilidad las conexiones de red por medio de DHCP.
Como lo muestra la figura, varios tipos de dispositivos pueden ser servidores DHCP. En la mayoría de las redes medianas a grandes, el servidor DHCP suele ser un servidor local y dedicado con base en una PC. En las redes domésticas, el servidor de DHCP suele estar ubicado en el router local que conecta la red doméstica al provedor de servicio de internet (ISP).
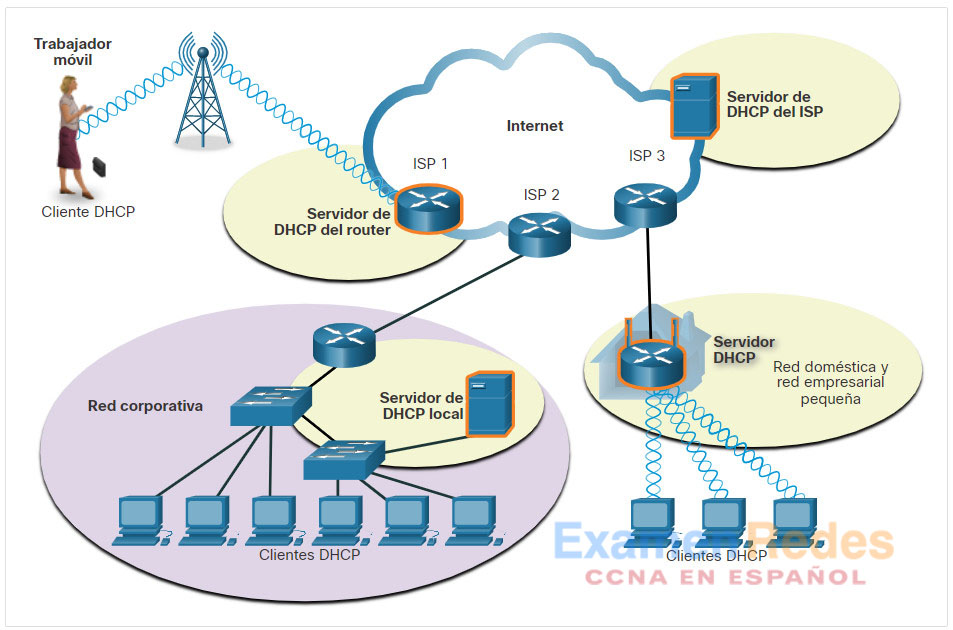
Muchas redes utilizan tanto el direccionamiento estático como DHCP. DHCP se utiliza para hosts de propósito general, tales como los dispositivos de usuario final. El direccionamiento estático se utiliza para los dispositivos de red, tales como (puertas de enlace )gateways, switches, servidores e impresoras.
DHCPv6 (DHCP para IPv6) proporciona servicios similares para los clientes IPv6. Una diferencia importante es que DHCPv6 no brinda una dirección de puerta de enlace predeterminada (default gateway). Esto sólo se puede obtener de forma dinámica a partir del anuncio de router del propio router.
10.1.2. Funcionamiento de DHCP
Como se muestra en la ilustración, cuando un dispositivo configurado con DHCP e IPv4 se inicia o se conecta a la red, el cliente transmite un mensaje de detección de DHCP (DHCPDISCOVER) para identificar cualquier servidor de DHCP disponible en la red. Un servidor de DHCP responde con un mensaje de oferta de DHCP (DHCPOFFER), que ofrece una concesión al cliente. El mensaje de oferta contiene la dirección IPv4 y la máscara de subred que se deben asignar, la dirección IPv4 del servidor DNS y la dirección IPv4 de la puerta de enlace predeterminada (default gateway). La oferta de concesión también incluye la duración de esta.
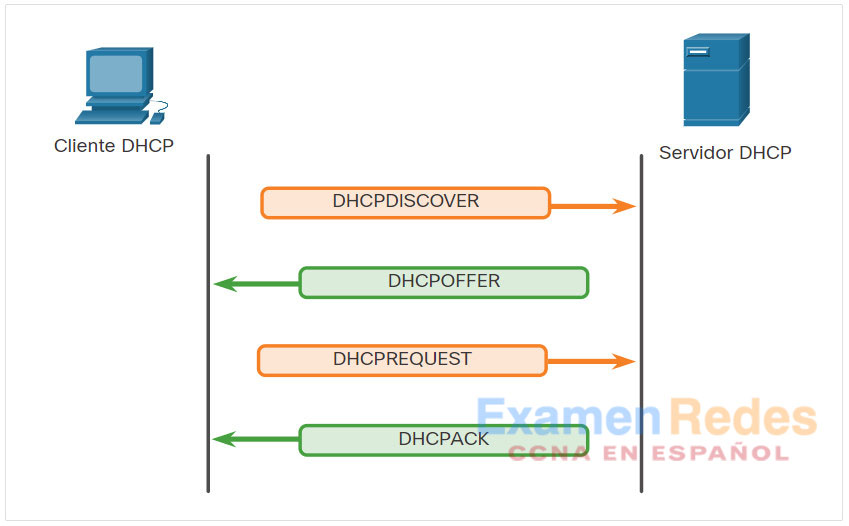
El cliente puede recibir varios mensajes DHCPOFFER si hay más de un servidor de DHCP en la red local. Por lo tanto, debe elegir entre ellos y enviar un mensaje de solicitud de DHCP (DHCPREQUEST) que identifique el servidor explícito y la oferta de concesión que el cliente acepta. Un cliente también puede optar por solicitar una dirección previamente asignada por el servidor.
Suponiendo que la dirección IPv4 solicitada por el cliente, u ofrecida por el servidor, aún está disponible, el servidor devuelve un mensaje de reconocimiento de DHCP (DHCPACK) que le informa al cliente que finalizó la concesión. Si la oferta ya no es válida, el servidor seleccionado responde con un mensaje de reconocimiento negativo de DHCP (DHCPNAK). Si se devuelve un mensaje DHCPNAK, entonces el proceso de selección debe volver a comenzar con la transmisión de un nuevo mensaje DHCPDISCOVER. Una vez que el cliente tiene la concesión, se debe renovar mediante otro mensaje DHCPREQUEST antes de que expire.
El servidor DHCP asegura que todas las direcciones IP sean únicas (no se puede asignar la misma dirección IP a dos dispositivos de red diferentes de forma simultánea). La mayoría de los proveedores de Internet utilizan DHCP para asignar direcciones a los clientes.
DHCPv6 tiene un conjunto similar de mensajes a los de DHCP para IPv4. Los mensajes de DHCPv6 son SOLICIT, ADVERTISE, INFORMATION REQUEST y REPLY.
10.1.3. Formato de mensaje DHCP
El formato del mensaje DHCPv4 se utiliza para todas las transacciones DHCPv4. Los mensajes DHCPv4 se encapsulan dentro del protocolo de transporte UDP. Los mensajes DHCPv4 que se envían desde el cliente utilizan el puerto de origen UDP 68 y el puerto de destino 67. Los mensajes DHCPv4 que se envían del servidor al cliente utilizan el puerto de origen UDP 67 y el puerto de destino 68. La estructura del mensaje DHCPv4 se muestra a continuación.
| 8 Código OP. (1) |
16 Tipo de hardware (1) |
24 Longitud de dirección de hardware (1) |
32 Saltos (1) |
|---|---|---|---|
| Identificador de transacción | |||
| Segundos: 2 bytes | Indicadores: 2 bytes | ||
| Dirección IP del cliente (CIADDR): 4 bytes | |||
| Su dirección IP (YIADDR): 4 bytes | |||
| Dirección IP del servidor (SIADDR): 4 bytes | |||
| Dirección IP del gateway (GIADDR): 4 bytes | |||
| Dirección de hardware del cliente (CHADDR): 16 bytes | |||
| Nombre del servidor (SNAME): 64 bytes | |||
| Nombre del archivo de arranque: 128 bytes | |||
| Opciones de DHCP: variable | |||
Estos campos se explican aquí:
- Código de funcionamiento – Especifica el tipo general de mensaje. El valor 1 indica un mensaje de solicitud y el valor 2 es un mensaje de respuesta.
- Tipo de hardware – Identifica el tipo de hardware que se utiliza en la red. Por ejemplo, 1 es Ethernet, 15 es retransmisión de tramas y 20 es una línea serial. Estos son los mismos códigos que se utilizan en mensajes ARP.
- Longitud de dirección de hardware – Especifica la longitud de la dirección.
- Saltos – Controla el reenvío de mensajes. Un cliente lo establece en 0 antes de transmitir una solicitud.
- Identificador de transacción – Lo utiliza el cliente para hacer coincidir la solicitud con las respuestas recibidas de los servidores DHCPv4.
- Segundos – Identifica la cantidad de segundos transcurridos desde que un cliente comenzó a intentar adquirir o renovar un arrendamiento. Lo utilizan los servidores de DHCPv4 para priorizar respuestas cuando hay varias solicitudes del cliente pendientes.
- Marcadores – Los utiliza un cliente que no conoce su dirección IPv4 cuando envía una solicitud. Se utiliza solo uno de los 16 bits, que es el indicador de difusión. El valor 1 en este campo le indica al servidor de DHCPv4 o al agente de retransmisión que recibe la solicitud que la respuesta se debe enviar como una difusión.
- Dirección IP del cliente – La utiliza un cliente durante la renovación del arrendamiento cuando la dirección del cliente es válida y utilizable, no durante el proceso de adquisición de una dirección. El cliente coloca su propia dirección IPv4 en este campo solamente si tiene una dirección IPv4 válida mientras se encuentra en el estado vinculado. De lo contrario, establece el campo en 0.
- Su dirección IP – La utiliza el servidor para asignar una dirección IPv4 al cliente.
- Dirección IP del servidor – La utiliza el servidor para identificar la dirección del servidor que debe utilizar el cliente para el próximo paso en el proceso bootstrap, que puede ser, o no, el servidor que envía esta respuesta. El servidor emisor siempre incluye su propia dirección IPv4 en un campo especial llamado opción DHCPv4 Server Identifier (Identificador de servidores DHCPv4).
- Dirección IP de la puerta de enlace (gateway) – Enruta los mensajes DHCPv4 cuando intervienen los agentes de retransmisión DHCPv4. La dirección de la puerta de enlace (gateway) facilita las comunicaciones de las solicitudes y respuestas de DHCPv4 entre el cliente y un servidor que se encuentran en distintas subredes o redes.
- Dirección de hardware del cliente – Especifica la capa física del cliente.
- Nombre del servidor – Lo utiliza el servidor que envía un mensaje DHCPOFFER o DHCPACK. El servidor puede, de manera optativa, colocar su nombre en este campo. Puede tratarse de un simple apodo de texto o un nombre de dominio DNS, como dhcpserver.netacad.net.
- Nombre del archivo de arranque – Lo utiliza un cliente de manera optativa para solicitar un determinado tipo de archivo de arranque en un mensaje DHCPDISCOVER. Lo utiliza un servidor en un DHCPOFFER para especificar completamente un directorio de archivos y un nombre de archivo de arranque.
- Opciones de DHCP – Contiene las opciones de DHCP, incluidos varios parámetros requeridos para el funcionamiento básico de DHCP. Este campo es de longitud variable. Tanto el cliente como el servidor pueden utilizarlo.
10.2. DNS
10.2.1. Descripción general de DNS
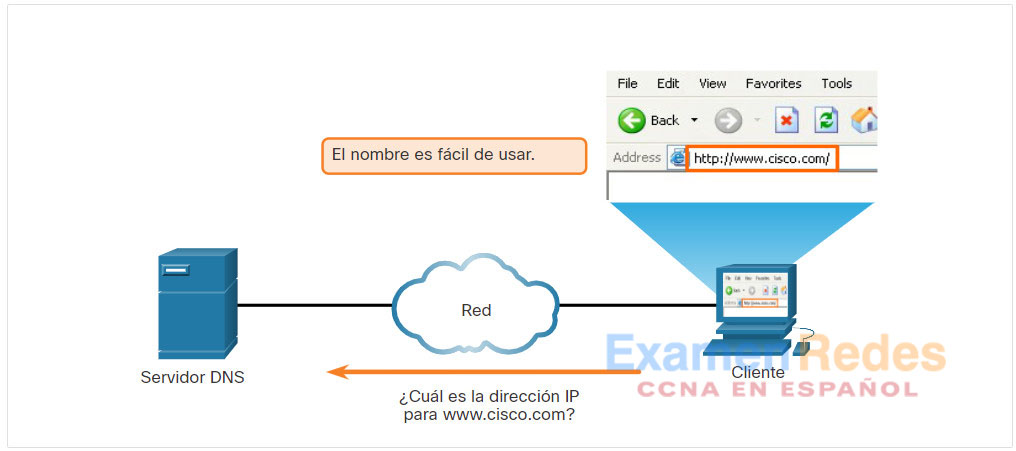
Cuando tan a menudo nos conectamos a servidores web usando nombres como www.cisco.com, esto ocurre mediante la asignación de direcciones IP a los paquetes. En Internet, estos nombres de dominio son mucho más fáciles de recordar para las personas que una dirección IP como 74.163.4.161. Si Cisco decide cambiar la dirección numérica de www.cisco.com, esto no afecta al usuario, porque el nombre de dominio se mantiene. Simplemente se une la nueva dirección al nombre de dominio existente y se mantiene la conectividad.
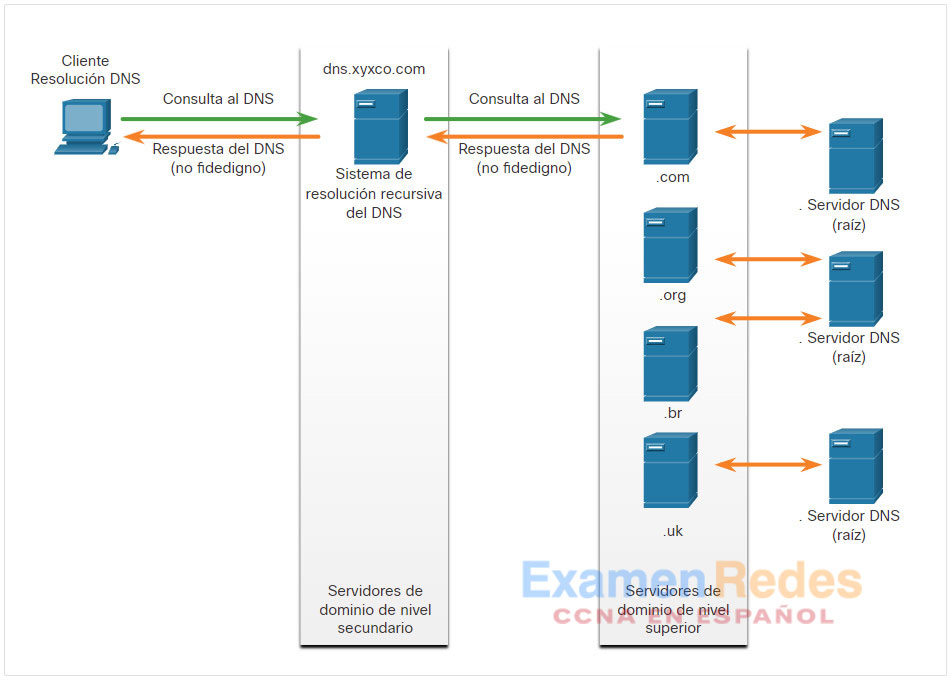
El sistema de nombres de dominio (DNS) se desarrolló para proporcionar un medio confiable de administrar y proporcionar los nombres de dominio y sus direcciones IP asociadas. El sistema de DNS se compone de una jerarquía global de servidores distribuidos que contienen bases de datos con asignaciones de nombre para las direcciones IP. En la figura, el cliente envía una solicitud al servidor DNS para obtener la dirección IP para www.cisco.com y así puede direccionar paquetes al servidor.
En un análisis reciente de las amenazas de seguridad de la red se descubrió que más del 90% de los software maliciosos se aprovechan del uso del sistema DNS para realizar campañas de ataques de red. Un analista de ciberseguridad debe tener un conocimiento profundo del sistema DNS y las maneras en que se puede detectar el tráfico malicioso de DNS mediante análisis de protocolo e inspección de información de monitoreo del DNS. Además, el malware suele ponerse en contacto con los servidores de comando y control mediante DNS. Esto hace que las URL del servidor sean indicadores de compromiso para vulnerabilidades específicas.
DNS resuelve nombres en direcciones IP
10.2.2. La jerarquía del dominio del DNS
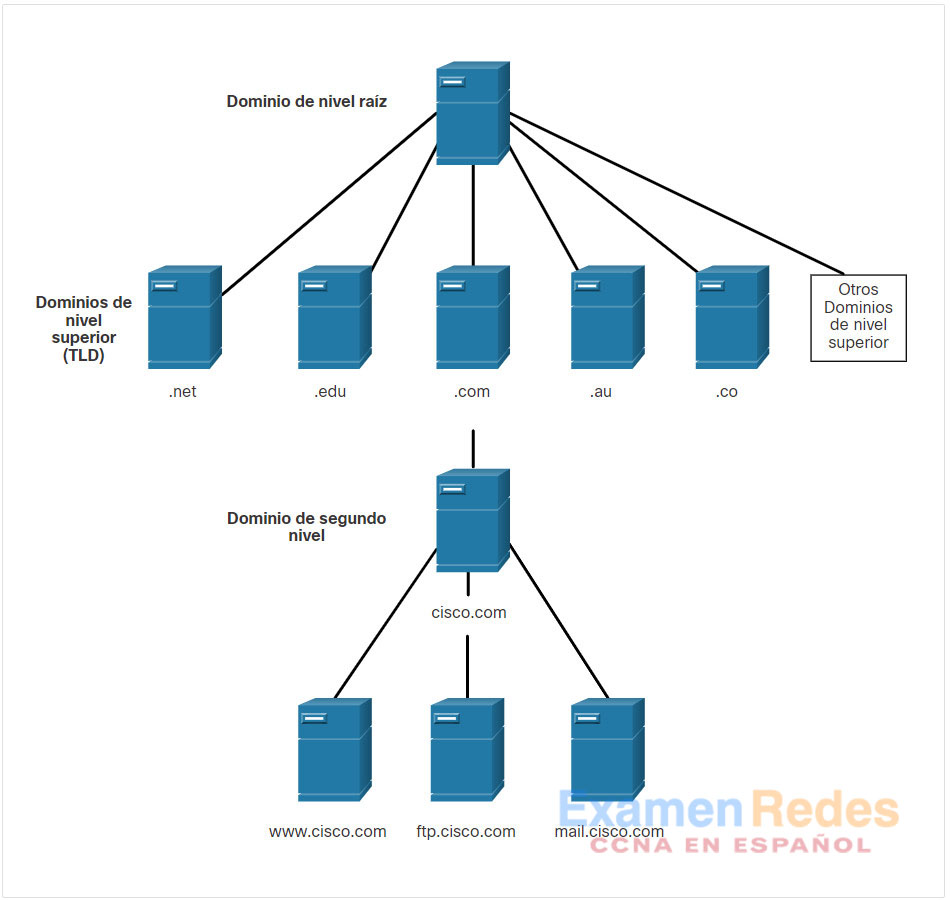
El DNS se compone de una jerarquía de dominios genéricos de nivel superior (gTLD) que consta de .com, .net, .org, .gov, .edu y numerosos dominios de país, como .es (España), .uk (Reino Unido), .br (Brasil), etc. En el siguiente nivel de la jerarquía de DNS, están los dominios de segundo nivel. Estos están representados por un nombre de dominio seguido de un dominio de nivel superior. Los subdominios se encuentran en el siguiente nivel de la jerarquía de DNS y representan una división del dominio de segundo nivel. Por último, un cuarto nivel puede representar un host en un subdominio. Cada elemento de una especificación de dominio suele denominarse etiqueta. Las etiquetas se mueven desde la parte superior de la jerarquía hacia abajo, de derecha a izquierda. Un punto (.) al final de un nombre de dominio representa el servidor de raíz de la parte superior de la jerarquía. En la figura, se ejemplifica esta jerarquía de dominio de DNS.
Los diferentes dominios de primer nivel representan el tipo de organización o el país de origen. Algunos ejemplos de dominios de nivel superior son los siguientes:
- .com: una empresa o industria
- .org: una organización sin fines de lucro
- .au: Australia
- .co: Colombia
10.2.3. El proceso de búsqueda de DNS
Para entender el DNS, los analistas de ciberseguridad deben estar familiarizados con los siguientes términos:
- Resolución – Un cliente de DNS que envía mensajes de DNS para obtener información sobre el espacio de nombre de dominio solicitado.
- Recursión – Las medidas adoptadas cuando se le pide a un servidor DNS que realice una consulta en nombre de una resolución de DNS.
- Servidor autorizado – Un servidor de DNS que responde a los mensajes de consulta con información almacenada en los registros de recursos (RR) para un espacio de nombres de dominio almacenado en el servidor.
- Resolución recursiva – Un servidor de DNS que realiza consultas de manera recursiva para obtener la información solicitada en la consulta de DNS.
- FQDN – Un nombre de dominio totalmente calificado ( Fully Qualified Domain Name) es el nombre absoluto de un dispositivo dentro de la base de datos distribuida de DNS.
- RR – A Resource Record is a format used in DNS messages that is composed of the following fields: NOMBRE, TIPO, CLASE, TTL, RDLENGTH y RDATA.
- Zona – Una base de datos que contiene información sobre el espacio de nombres de dominio almacenado en un servidor autorizado.
Al intentar resolver la dirección IP de un nombre, un host del usuario, conocido en el sistema como una resolución, primero comprobará su caché de DNS local. Si la asignación no se encuentra allí, se emitirá una consulta al servidor o a los servidores DNS que estén configurados en las propiedades de direccionamiento de red de la resolución. Estos servidores pueden estar presentes en una empresa o ISP. Si la asignación no se encuentra allí, el servidor DNS realiza la consulta en otros servidores DNS de mayor nivel autorizados para el dominio de nivel superior a fin de encontrar la asignación. Este proceso se denomina consulta recursiva.
Debido a la posible carga en los servidores de dominio de nivel superior autorizados, algunos servidores DNS en la jerarquía mantienen cachés de todos los registros de DNS que han resuelto durante un período específico. Estos servidores DNS de caché pueden resolver consultas recursivas sin reenviarlas a servidores de nivel superior. Si un servidor requiere datos para una zona, solicitará una transferencia de datos de un servidor autorizado para esa zona. El proceso de transferir bloques de datos de DNS entre servidores se conoce como transferencia de zona.
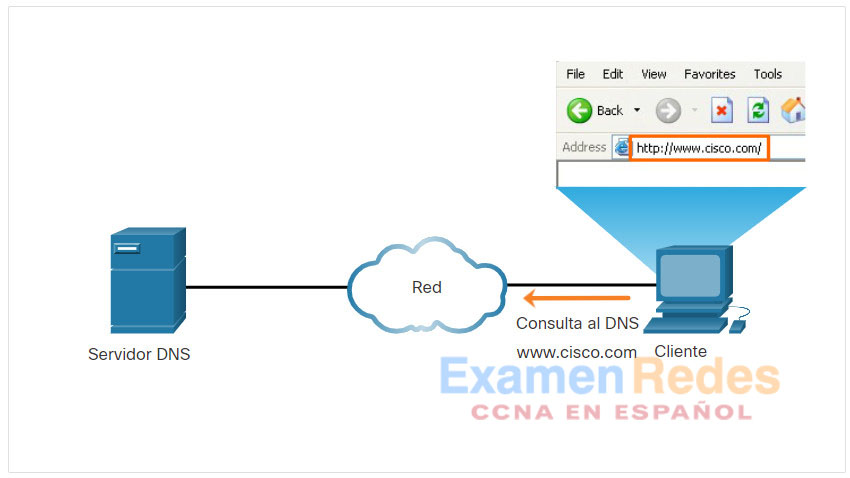
Haga clic en cada botón para revisar los pasos relacionados con la resolución DNS.
Haga clic en cada botón para obtener más información.
- Paso 1
- Paso 2
- Paso 3
- Paso 4
- Paso 5
El usuario escribe un FQDN en un campo Dirección de aplicación del explorador.
Se envía una consulta DNS al servidor DNS designado para el equipo cliente.
El servidor DNS coincide con el FQDN con su dirección IP.
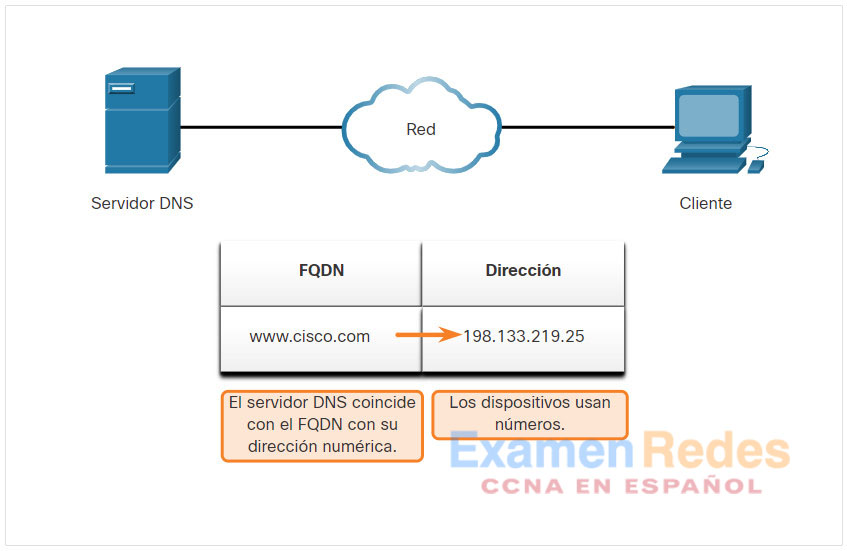
La respuesta de consulta DNS se envía de nuevo al cliente con la dirección IP del FQDN.
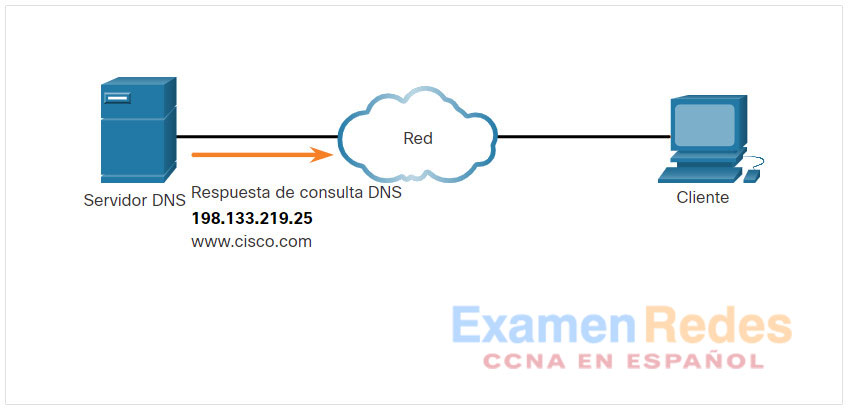
El equipo cliente utiliza la dirección IP para realizar solicitudes del servidor.
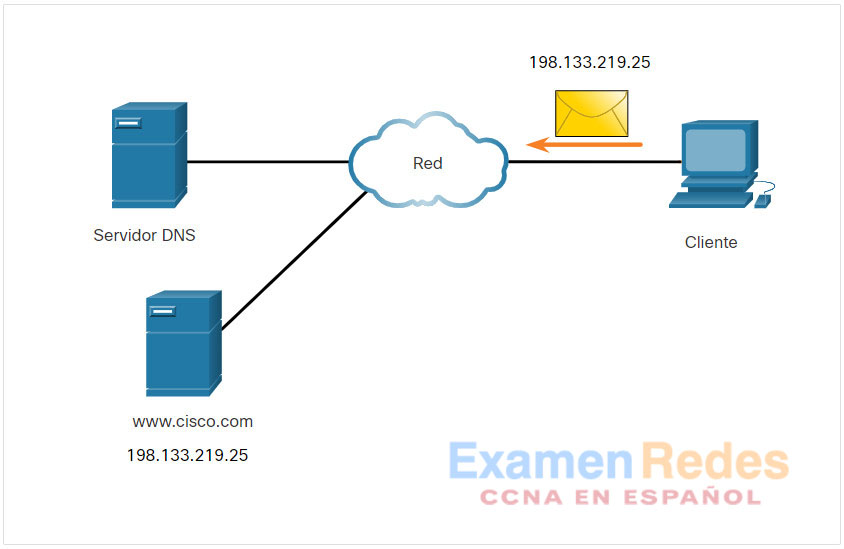
10.2.4. Formato de mensaje DNS
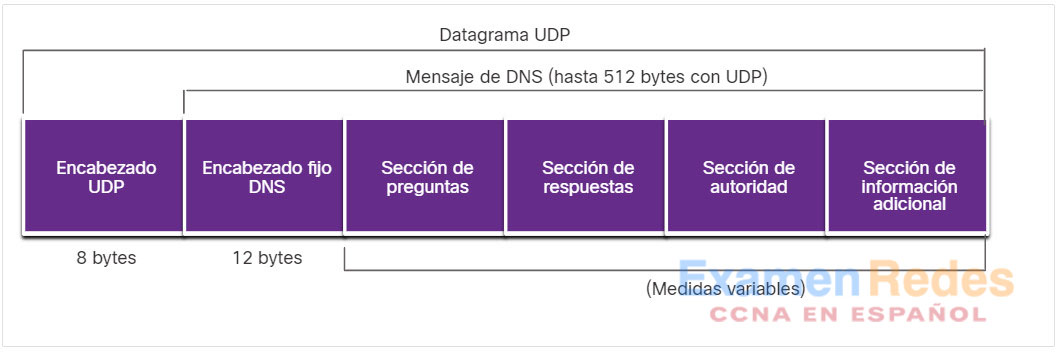
DNS utiliza el puerto UDP 53 para las consultas y respuestas de DNS. Las consultas de DNS se originan en un cliente y las respuestas se emiten desde servidores DNS. Si una respuesta de DNS excede los 512 bytes, como por ejemplo cuando se usa DNS dinámico (DDNS), el mensaje se manipula a través del puerto TCP 53. Incluye el formato de consultas, respuestas y datos. Las comunicaciones del protocolo DNS utilizan un único formato llamado “mensaje”. Este formato de mensaje que se ve en la figura se utiliza para todos los tipos de solicitudes de clientes y respuestas del servidor, para los mensajes de error y para la transferencia de información de registro de recursos entre servidores.
El servidor DNS almacena los diferentes tipos de RR utilizados para resolver nombres. Estos registros contienen el nombre, la dirección y el tipo de registro. Esta es una lista de algunos de estos tipos de registros:
- A – Una dirección IPv4 de terminal
- NS – un servidor de nombre autoritativo
- AAAA – una dirección IPv6 de terminal (pronunciada quad-A)
- MX – un registro de intercambio de correo
Cuando un cliente realiza una consulta, el proceso DNS del servidor observa primero sus propios registros para resolver el nombre. Si no puede resolverlo con los registros almacenados, contacta a otros servidores para hacerlo. Una vez que se encuentra una coincidencia y se la devuelve al servidor solicitante original, este almacena temporalmente la dirección numerada por si se vuelve a solicitar el mismo nombre.
El servicio del cliente DNS en los equipos Windows también almacena los nombres resueltos previamente en la memoria. El comando ipconfig /displaydns muestra todas las entradas de DNS en caché.
DNS utiliza el mismo mensaje para
- Todo tipo de consultas de clientes y respuestas del servidor
- Mensajes de error
- La transferencia de recursos de registro entre servidores
Como se muestra en la figura, este formato de mensaje se utiliza para todos los tipos de solicitudes de clientes y respuestas del servidor, para los mensajes de error y para la transferencia de información de registro de recursos entre servidores. La tabla describe cada sección.
| Sección de mensajes DNS | Descripción |
|---|---|
| Pregunta | La pregunta para el servidor. Contiene el nombre de dominio que se resolverá, la clase de dominio, y el tipo de solicitud. |
| Respuesta | El registro de recursos de DNS, o RR, para la consulta incluida la resolución de la dirección IP depende del tipo de RR. |
| Autoridad | Contiene los RRs para la autoridad del dominio. |
| Adicional | Relevante únicamente para las respuestas de consulta. Consiste en RRs que contienen información adicional que hará que la resolución de consultas sea más eficiente |
10.2.5. DNS dinámico
DNS requiere que los registradores acepten y distribuyan las asignaciones de DNS de las organizaciones que deseen registrar asignaciones de nombre de dominio y dirección IP. Después de crear la asignación inicial (un proceso que puede demorar 24 horas o más), es posible realizar cambios en la dirección IP que se asigna al nombre de dominio poniéndose en contacto con el registrador o usando un formulario en línea para efectuar el cambio. Sin embargo, debido al tiempo que demora este proceso y la distribución de la nueva asignación en el sistema de nombres de dominio, pueden transcurrir horas hasta que la nueva asignación esté disponible para las resoluciones. En situaciones en las que un ISP utiliza DHCP para proporcionar direcciones a un dominio, es posible que la dirección que se asigna al dominio caduque y el ISP otorgue una nueva. Esto daría lugar a una interrupción de conectividad al dominio mediante DNS. Un nuevo enfoque era necesario para permitir que las organizaciones realicen cambios rápidos en la dirección IP asignada a un dominio.
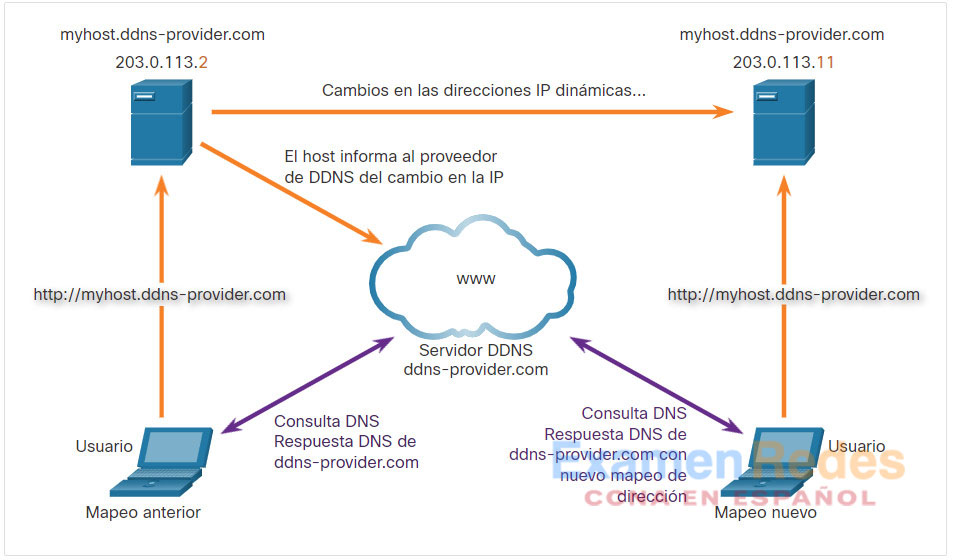
DNS dinámico (DDNS) le permite a un usuario u organización registrar una dirección IP con un nombre de dominio, al igual que en DNS. Sin embargo, cuando cambia la dirección IP de la asignación, la nueva asignación puede propagarse en el DNS casi instantáneamente. Para que esto ocurra, un usuario obtiene un subdominio de un proveedor de DDNS. Ese subdominio se asigna a la dirección IP del servidor o la conexión doméstica de router a Internet del usuario. El software cliente se ejecuta en el router o en una computadora host que detecta un cambio en la dirección IP de Internet del usuario. Cuando se detecta un cambio, se informa al proveedor de DDNS inmediatamente y la asignación entre el subdominio del usuario y la dirección IP de Internet se actualiza inmediatamente, como se ve en la figura. DDNS no utiliza una verdadera entrada de DNS para la dirección IP de un usuario. En cambio, actúa como intermediario. El dominio del proveedor de DDNS está registrado con el DNS, pero el subdominio se asigna a una dirección IP completamente distinta. El servicio del proveedor de DDNS suministra esa dirección IP al servidor DNS de segundo nivel de la resolución. Ese servidor DNS, ya sea en la organización o en el ISP, proporciona la dirección IP de DDNS para la resolución.
Los atacantes pueden abusar de DNS dinámico de varias maneras. Los servicios gratuitos de DDNS son especialmente útiles para los atacantes. DDNS se puede utilizar para facilitar el cambio rápido de la dirección IP de los servidores de comando y control de malware después de que la dirección IP actual se haya bloqueado ampliamente. De esta manera, el malware se puede codificar con una URL en lugar de una dirección IP estática. DDNS también se puede utilizar como una forma de ex-filtrar datos desde dentro de una red porque el tráfico DNS es muy común y con frecuencia se considera benigno. DDNS en sí mismo no es maligno, sin embargo, monitorear el tráfico DNS que va a servicios DDNS conocidos, especialmente los gratuitos, es muy útil para la detección de vulnerabilidades.
10.2.6. El protocolo WHOIS
WHOIS es un protocolo basado en TCP que se usa para identificar a los propietarios de dominios de Internet a través del sistema de DNS. Cuando un dominio en Internet se registra y asigna a una dirección IP para el sistema de DNS, el registrante debe proporcionar información sobre quién registra el dominio. La aplicación de WHOIS utiliza una consulta en forma de FQDN. La consulta se emite a través de un servicio o una aplicación de WHOIS. El registro oficial de propiedad se le devuelve al usuario mediante el servicio de WHOIS. Esto puede resultar útil para la identificación de los destinos a los que han tenido acceso los hosts en una red. WHOIS tiene limitaciones y los hackers tienen maneras de ocultar su identidad. Sin embargo, WHOIS es un punto de partida para la identificación de ubicaciones de Internet potencialmente peligrosas a las que se puede haber llegado mediante la red. Un servicio WHOIS basado en Internet se denomina ICANN Lookup se puede utilizar para obtener el registro de registro una URL. Otros servicios de WHOIS son mantenidos por registros regionales de Internet como RIPE y APNIC.
10.2.7. Práctica de laboratorio: Utilizar Wireshark para examinar una captura DNS de UDP
En esta práctica de laboratorio, establecerá comunicación con un servidor DNS enviando una consulta de DNS mediante el protocolo de transporte UDP. Utilizará Wireshark para examinar los intercambios de consulta y respuesta de DNS con el mismo servidor.
10.3. NAT
10.3.1. Espacio de direcciones IPv4 privadas
Como sabe, no hay suficientes direcciones IPv4 públicas para asignar una dirección única a cada dispositivo conectado a Internet. Las redes suelen implementarse mediante el uso de direcciones IPv4 privadas, según se definen en RFC 1918. El rango de direcciones incluido en RFC 1918 se incluye en la siguiente tabla. Es muy probable que la computadora que utiliza para ver este curso tenga asignada una dirección privada.
| Clase | Rango de direcciones internas RFC 1918 | Prefijo |
|---|---|---|
| A | 10.0.0.0 a 10.255.255.255 | 10.0.0.0/8 |
| B | 172.16.0.0 a 172.31.255.255 | 172.16.0.0/12 |
| C | 192.168.0.0 a 192.168.255.255 | 192.168.0.0/16 |
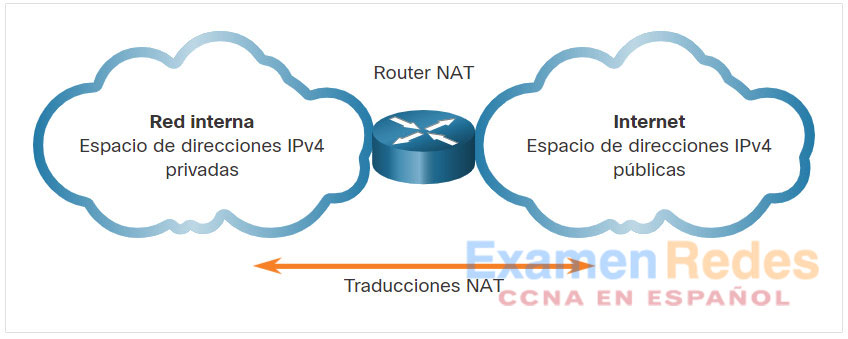
Estas direcciones privadas se utilizan dentro de una organización o un sitio para permitir que los dispositivos se comuniquen localmente. Sin embargo, debido a que estas direcciones no identifican a una sola empresa u organización, las direcciones IPv4 privadas no se pueden enrutar a través de Internet. Para permitir que un dispositivo con una dirección IPv4 privada acceda a recursos y dispositivos fuera de la red local, primero se debe traducir la dirección privada a una dirección pública.
NAT proporciona la traducción de direcciones privadas a direcciones públicas, como se muestra en la figura. Esto permite que un dispositivo con una dirección IPv4 privada acceda a recursos fuera de su red privada, como los que se encuentran en Internet. NAT, combinado con direcciones IPv4 privadas, ha sido el método principal para preservar las direcciones IPv4 públicas. Se puede compartir una única dirección IPv4 pública entre cientos o incluso miles de dispositivos, cada uno configurado con una dirección IPv4 privada exclusiva.
Sin NAT, el agotamiento del espacio de direcciones IPv4 habría ocurrido mucho antes del año 2000. Sin embargo, NAT tiene limitaciones y desventajas, que se explorarán más adelante en este módulo. La solución al agotamiento del espacio de direcciones IPv4 y a las limitaciones de NAT es la transición final a IPv6.
10.3.2. ¿Qué es NAT?
NAT tiene muchos usos, pero el principal es conservar las direcciones IPv4 públicas. Esto se logra al permitir que las redes utilicen direcciones IPv4 privadas internamente y al proporcionar la traducción a una dirección pública solo cuando sea necesario. NAT tiene el beneficio percibido de agregar un grado de privacidad y seguridad a una red, ya que oculta las direcciones IPv4 internas de redes externas.
Los routers con NAT habilitada se pueden configurar con una o más direcciones IPv4 públicas válidas. Estas direcciones públicas se conocen como “conjunto de NAT”. Cuando un dispositivo interno envía tráfico fuera de la red, el router con NAT habilitada traduce la dirección IPv4 interna del dispositivo a una dirección pública de la piscina NAT. Para los dispositivos externos, todo el tráfico entrante y saliente de la red parece tener una dirección IPv4 pública del conjunto de direcciones proporcionado.
En general, los routers NAT funcionan en la frontera de una red de rutas internas. Una red de código auxiliar es una o más redes con una única conexión a su red vecina, una entrada y una salida de la red. En el ejemplo de la ilustración, el R2 es un router de frontera. Visto desde el ISP, el R2 forma una red de rutas internas.
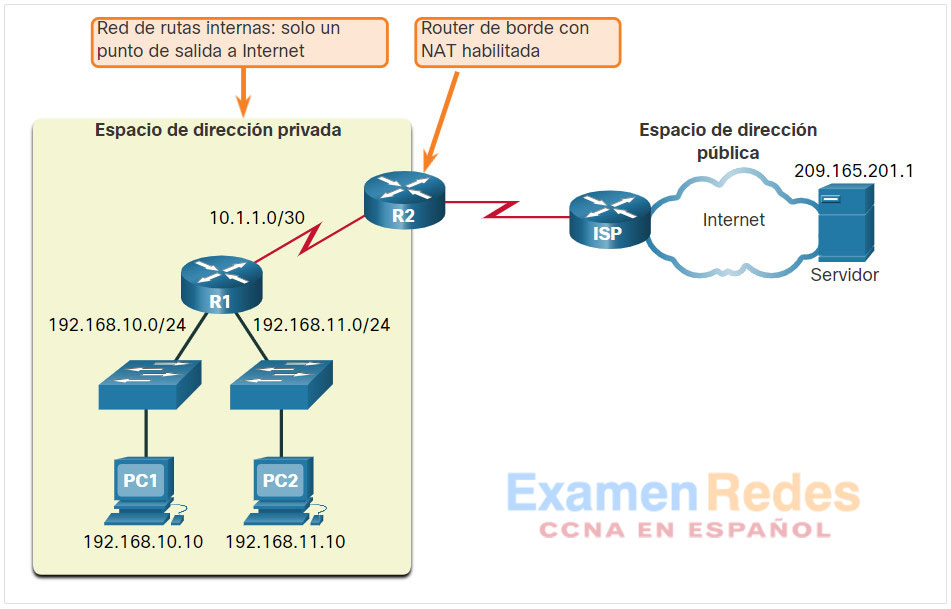
Cuando un dispositivo dentro de la red de rutas internas desea comunicarse con un dispositivo fuera de su red, el paquete se reenvía al router de frontera. El router de frontera realiza el proceso de NAT, es decir, traduce la dirección privada interna del dispositivo a una dirección pública, externa y enrutable.
Nota: La conexión al ISP puede utilizar dirección privada o dirección pública que es compartida entre los consumidores. Para los propósitos de este módulo, se muestra una dirección pública.
10.3.3. ¿Cómo funciona NAT?
En este ejemplo, la PC1 con la dirección privada 192.168.10.10 desea comunicarse con un servidor web externo con la dirección pública 209.165.201.1.
Haga clic en el botón Reproducir de la figura para iniciar la animación.
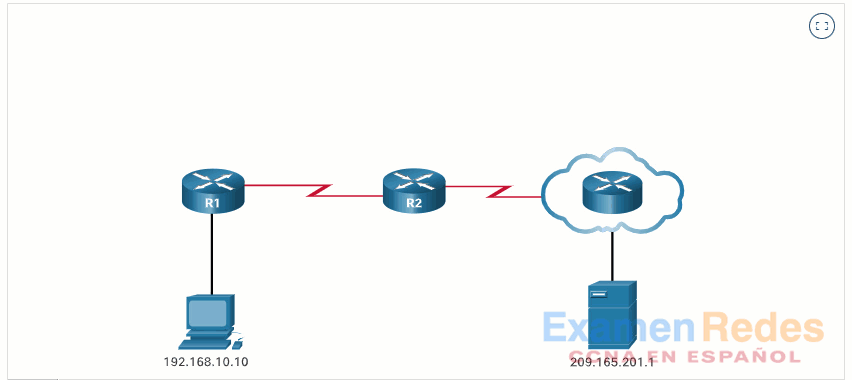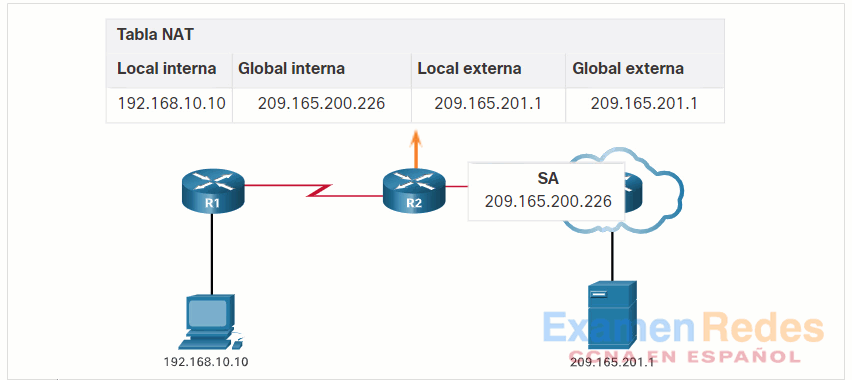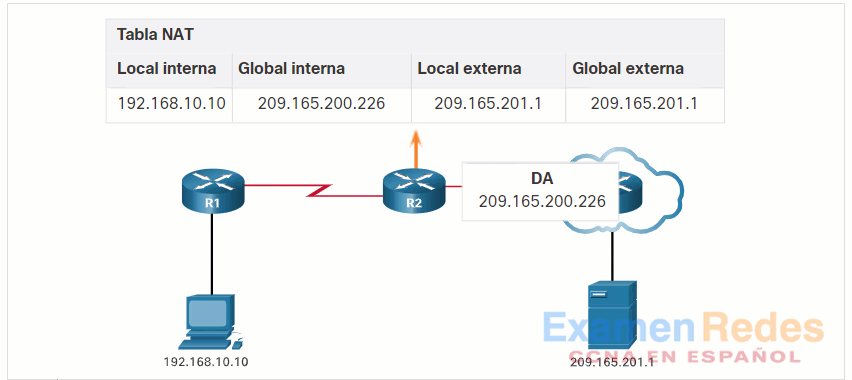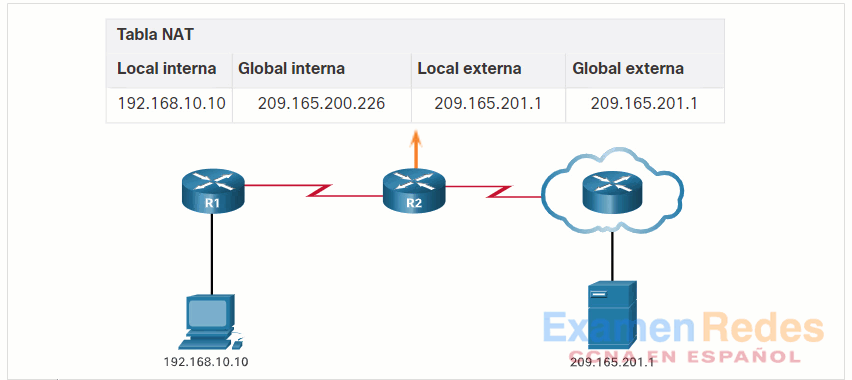
10.3.4. Traducción de la dirección del puerto
La traducción de la dirección del puerto (PAT), también conocida como “NAT con sobrecarga”, asigna varias direcciones IPv4 privadas a una única dirección IPv4 pública o a algunas direcciones. Esto es lo que hacen la mayoría de los enrutadores domésticos. El ISP asigna una dirección al enrutador, sin embargo, varios miembros del hogar pueden acceder simultáneamente a Internet. Esta es la forma más común de NAT tanto para el hogar como para la empresa.
Con PAT, se pueden asignar varias direcciones a una o más direcciones, debido a que cada dirección privada también se rastrea con un número de puerto. Cuando un dispositivo inicia una sesión TCP / IP, genera un valor de puerto de origen TCP o UDP, o un ID de consulta especialmente asignado para ICMP, para identificar de forma única la sesión. Cuando el router NAT recibe un paquete del cliente, utiliza su número de puerto de origen para identificar de forma exclusiva la traducción NAT específica.
PAT garantiza que los dispositivos usen un número de puerto TCP diferente para cada sesión con un servidor en Internet. Cuando llega una respuesta del servidor, el número de puerto de origen, que se convierte en el número de puerto de destino en la devolución, determina a qué dispositivo el router reenvía los paquetes. El proceso de PAT también valida los paquetes entrantes que han solicitado, lo que agrega un grado de seguridad a la sesión.
Haga clic en Reproducir en la figura para ver una animación del proceso PAT. PAT agrega números de puerto de origen únicos a la dirección global interna para distinguir las traducciones.
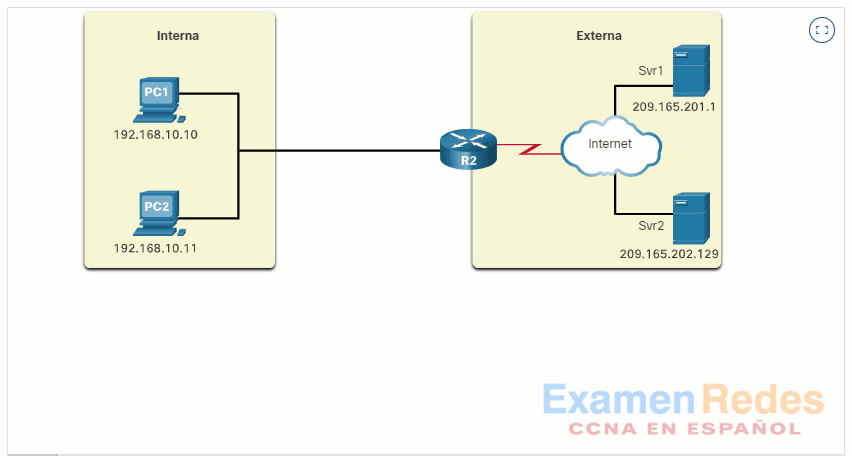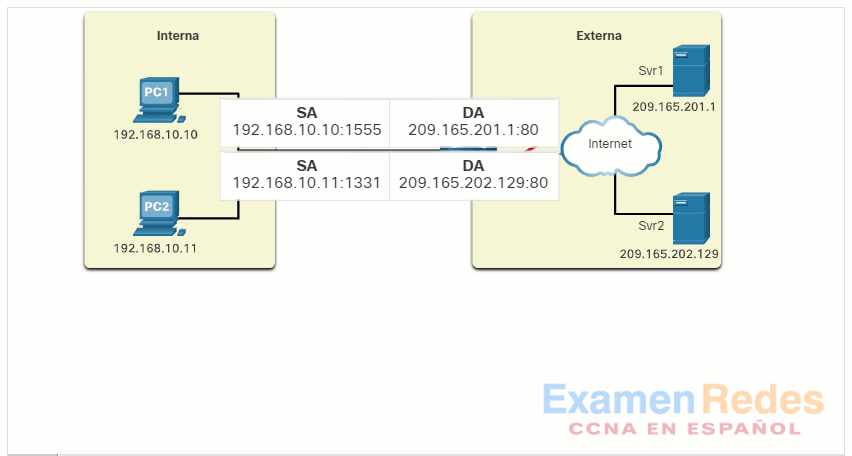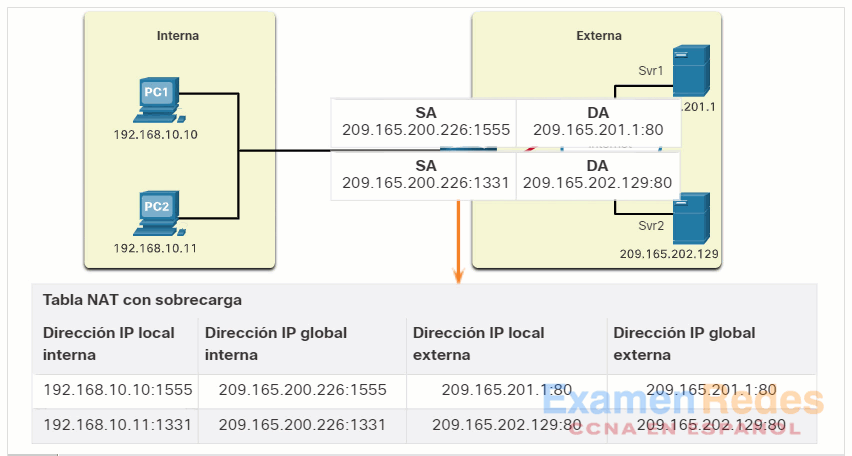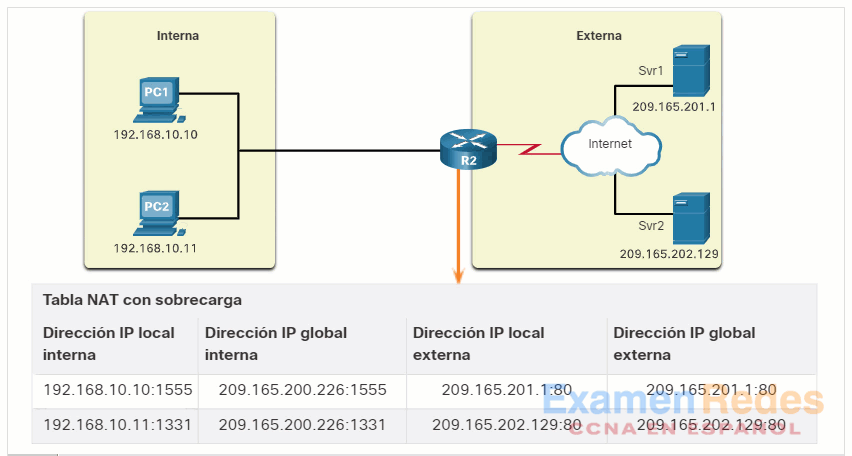
A medida que el R2 procesa cada paquete, utiliza un número de puerto (1331 y 1555, en este ejemplo) para identificar el dispositivo en el que se originó el paquete. La dirección de origen (SA) es la dirección local interna con el número de puerto asignado TCP / UDP agregado. La dirección de destino (DA) es la dirección global externa con el número de puerto de servicio agregado. En este ejemplo, el puerto de servicio es 80, que es HTTP.
Para la dirección de origen, el R2 traduce la dirección local interna a una dirección global interna con el número de puerto agregado. La dirección de destino no cambia, pero ahora se conoce como la dirección IPv4 global externa. Cuando el servidor web responde, se invierte la ruta.
10.4. Servicios de transferencia de archivos y uso compartido
10.4.1. FTP y TFTP
Protocolo de transferencia de archivos (FTP)
FTP es otro protocolo de capa de aplicación que se utiliza comúnmente. El protocolo FTP se desarrolló para permitir las transferencias de datos entre un cliente y un servidor. Un cliente FTP es una aplicación que se ejecuta en una computadora cliente y se utiliza para insertar y extraer datos en un servidor FTP.
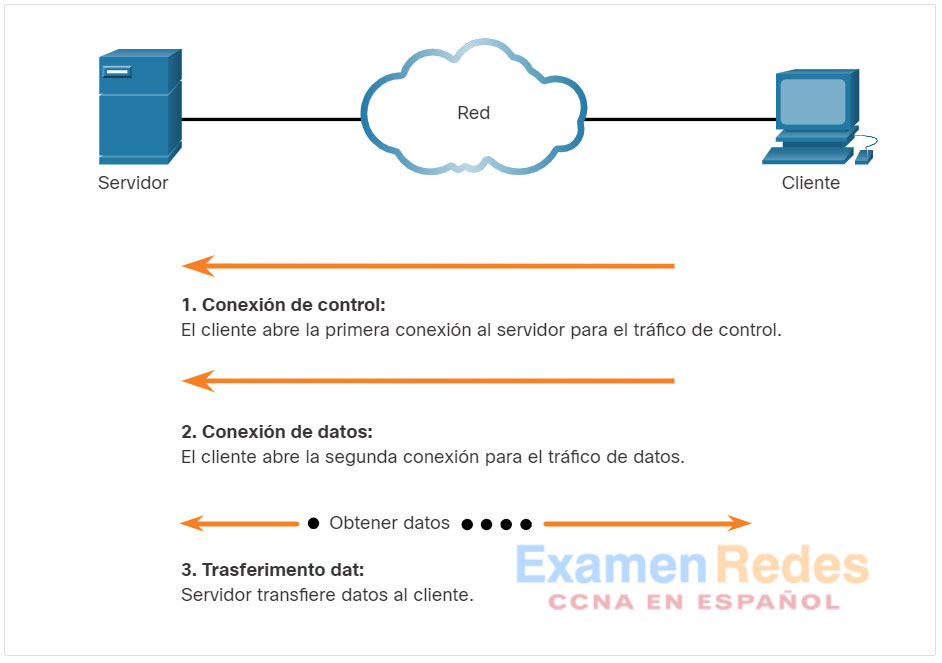
Como se muestra en la figura, para transferir datos correctamente, FTP requiere dos conexiones entre el cliente y el servidor, una para los comandos y las respuestas y la otra para la transferencia de archivos propiamente dicha:
- El cliente establece la primera conexión al servidor para el tráfico de control por medio del puerto 21 de TCP, que está constituido por comandos del cliente y respuestas del servidor.
- El cliente establece la segunda conexión al servidor para la transferencia de datos propiamente dicha por medio del puerto 20 de TCP. Esta conexión se crea cada vez que hay datos para transferir.
La transferencia de datos se puede producir en ambas direcciones. El cliente puede descargar (extraer) datos del servidor o subir datos a él (insertarlos).
El FTP no se concibió como un protocolo de capa de aplicación seguro. Por este motivo, el protocolo de transferencia de SSH, que es una forma segura de FTP que utiliza el protocolo Secure Shell para ofrecer un canal protegido, es la opción preferida para la transferencia de archivos.
Protocolo trivial de transferencia de archivos (TFTP)
TFTP es un protocolo de transferencia de archivos simplificado que utiliza el conocido número de puerto UDP 69. Carece de muchas de las características del FTP, como las operaciones de gestión de archivos para enumerar, eliminar o renombrar archivos. Debido a su sencillez, el TFTP tiene una sobrecarga de red muy baja y es popular para aplicaciones de transferencia de archivos que no son fundamentales. Sin embargo, es inseguro por naturaleza, porque no tiene ninguna característica de inicio de sesión ni de control de acceso. Por este motivo, el TFTP debe implementarse cuidadosamente y solo cuando sea absolutamente necesario.
10.4.2. SMB
El bloque de mensajes del servidor (Server message block)(SMB) es un protocolo de intercambio de archivos entre cliente y servidor que describe la estructura de los recursos de red compartidos, como directorios, archivos, impresoras y puertos serie, como se ve en la Figura. Es un protocolo de solicitud-respuesta. Todos los mensajes SMB comparten un mismo formato. Este formato utiliza un encabezado de tamaño fijo seguido de un parámetro de tamaño variable y un componente de datos.
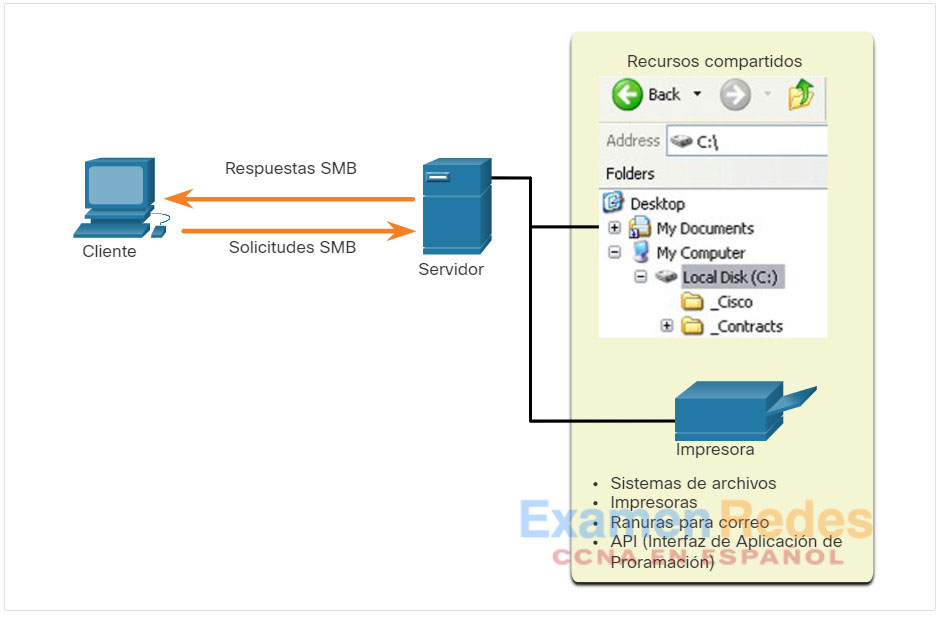
Los mensajes SMB pueden iniciar, autenticar y terminar sesiones, controlar el acceso a archivos e impresoras, y permitir que una aplicación envíe mensajes a otro dispositivo o los reciba de él.
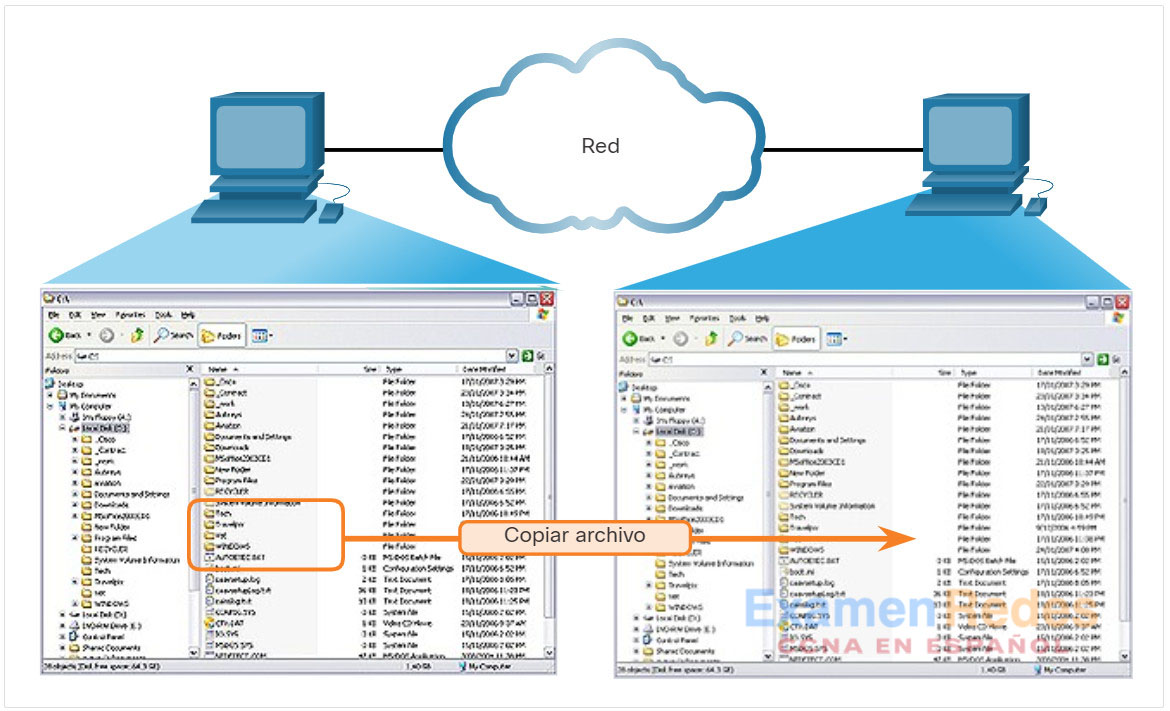
Los servicios de impresión y uso compartido de archivos de SMB se han convertido en el pilar de las redes de Microsoft, como se ve en la Figura.
10.4.3. Práctica de laboratorio: Utilizar Wireshark para examinar capturas de TCP y UDP
En esta práctica de laboratorio se cumplirán los siguientes objetivos:
- Identificar campos de encabezado y operación TCP mediante una captura de sesión FTP de Wireshark
- Identificar campos de encabezado y operación UDP mediante una captura de sesión TFTP de Wireshark
10.5. Correo electrónico
10.5.1. Protocolos de correo electrónico
Uno de los principales servicios que un ISP ofrece es hosting de correo electrónico. Para ejecutar el correo electrónico en una PC o en otro terminal, se requieren varios servicios y aplicaciones, como se muestra en la figura. El correo electrónico es un método de guardado y desvío que se utiliza para enviar, guardar y recuperar mensajes electrónicos a través de una red. Los mensajes de correo electrónico se guardan en bases de datos en servidores de correo.
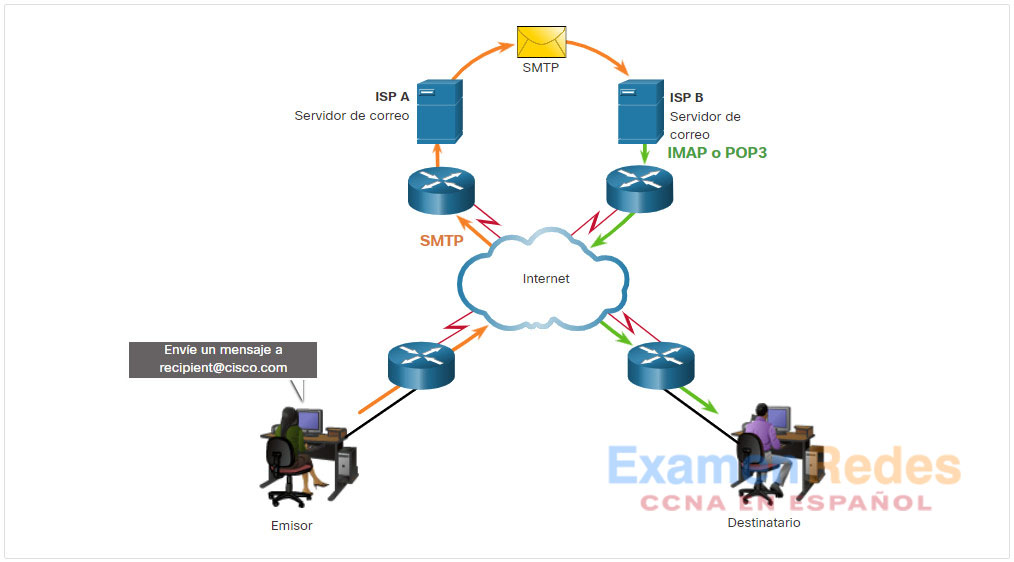
Los clientes de correo electrónico se comunican con servidores de correo para enviar y recibir correo electrónico. Los servidores de correo se comunican con otros servidores de correo para transportar mensajes desde un dominio a otro. Un cliente de correo electrónico no se comunica directamente con otro cliente de correo electrónico cuando envía un correo electrónico. En cambio, ambos clientes dependen del servidor de correo para transportar los mensajes.
El correo electrónico admite tres protocolos diferentes para su funcionamiento: el protocolo simple de transferencia de correo (SMTP), el protocolo de oficina de correos (POP) e IMAP. El proceso de capa de aplicaciones que envía correo utiliza el SMTP. Un cliente recupera el correo electrónico mediante uno de los dos protocolos de capa de aplicaciones: el POP o el IMAP.
10.5.2. SMTP
Los formatos de mensajes SMTP necesitan un encabezado y un cuerpo de mensaje. Mientras que el cuerpo del mensaje puede contener la cantidad de texto que se desee, el encabezado debe contar con una dirección de correo electrónico de destinatario correctamente formateada y una dirección de emisor.
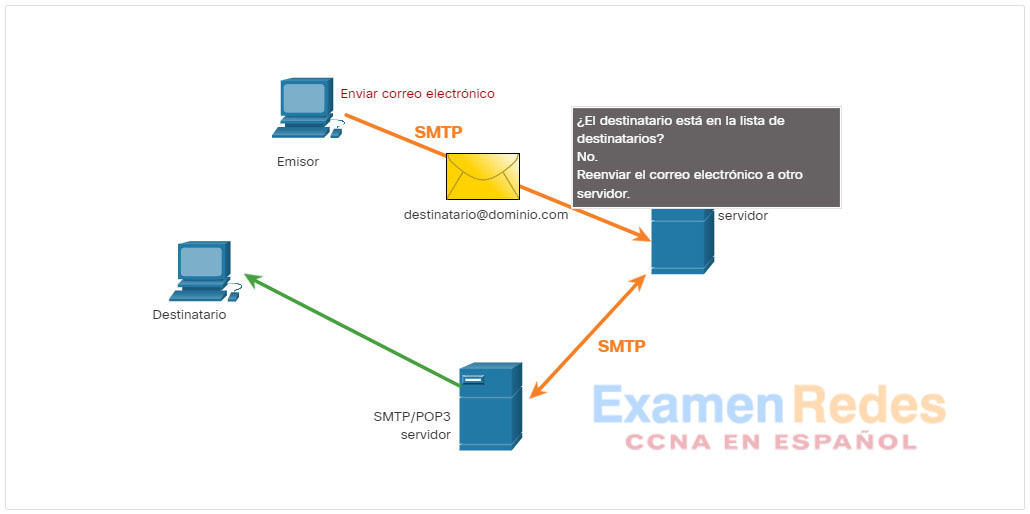
Cuando un cliente envía correo electrónico, el proceso SMTP del cliente se conecta a un proceso SMTP del servidor en el bien conocido puerto 25. Después de que se establece la conexión, el cliente intenta enviar el correo electrónico al servidor a través de esta. Una vez que el servidor recibe el mensaje, lo ubica en una cuenta local (si el destinatario es local) o lo reenvía a otro servidor de correo para su entrega, como se muestra en la figura.
El servidor de correo electrónico de destino puede no estar en línea, o estar muy ocupado, cuando se envían los mensajes. Por lo tanto, el SMTP pone los mensajes en cola para enviarlos posteriormente. El servidor verifica periódicamente la cola en busca de mensajes e intenta enviarlos nuevamente. Si el mensaje aún no se ha entregado después de un tiempo predeterminado de expiración, se devolverá al emisor como imposible de entregar.
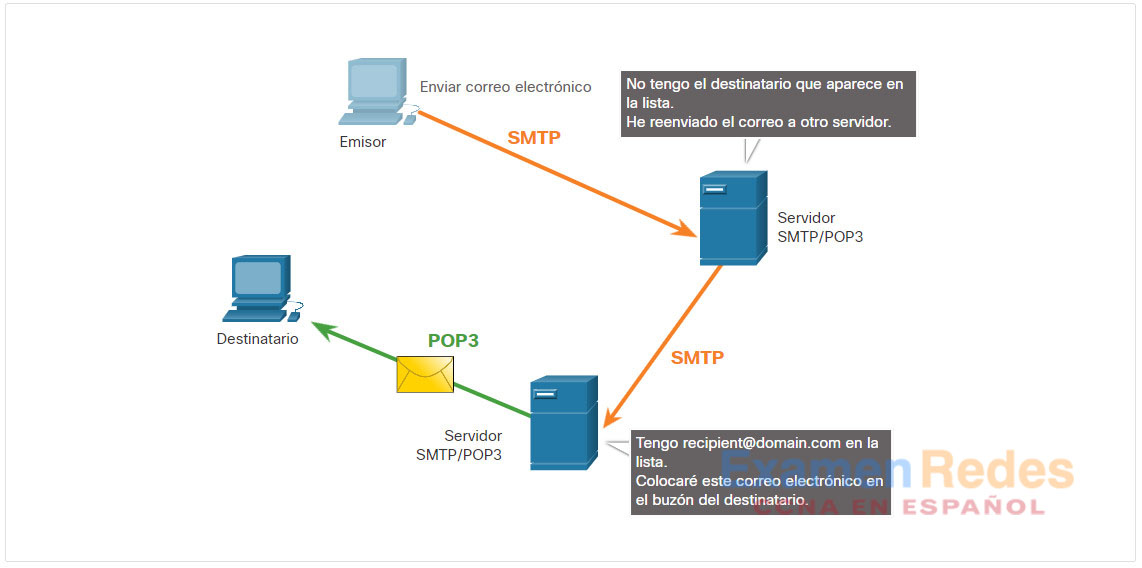
10.5.3. POP3
Una aplicación usa POP3 para recuperar correo de un servidor de correo. Con POP3, el correo se descarga del servidor al cliente y se elimina del servidor después, como se ve en la figura.
El servidor comienza el servicio POP3 escuchando de manera pasiva en el puerto TCP 110 las solicitudes de conexión del cliente. Cuando un cliente desea utilizar el servicio, envía una solicitud para establecer una conexión TCP con el servidor. Una vez establecida la conexión, el servidor POP3 envía un saludo. A continuación, el cliente y el servidor POP3 intercambian comandos y respuestas hasta que la conexión se cierra o cancela.
Con POP3, los mensajes de correo electrónico se descargan en el cliente y se eliminan del servidor, lo que significa que no existe una ubicación centralizada donde se conserven los mensajes de correo electrónico. Como el POP3 no almacena mensajes, no es una opción adecuada para una pequeña empresa que necesita una solución de respaldo centralizada.
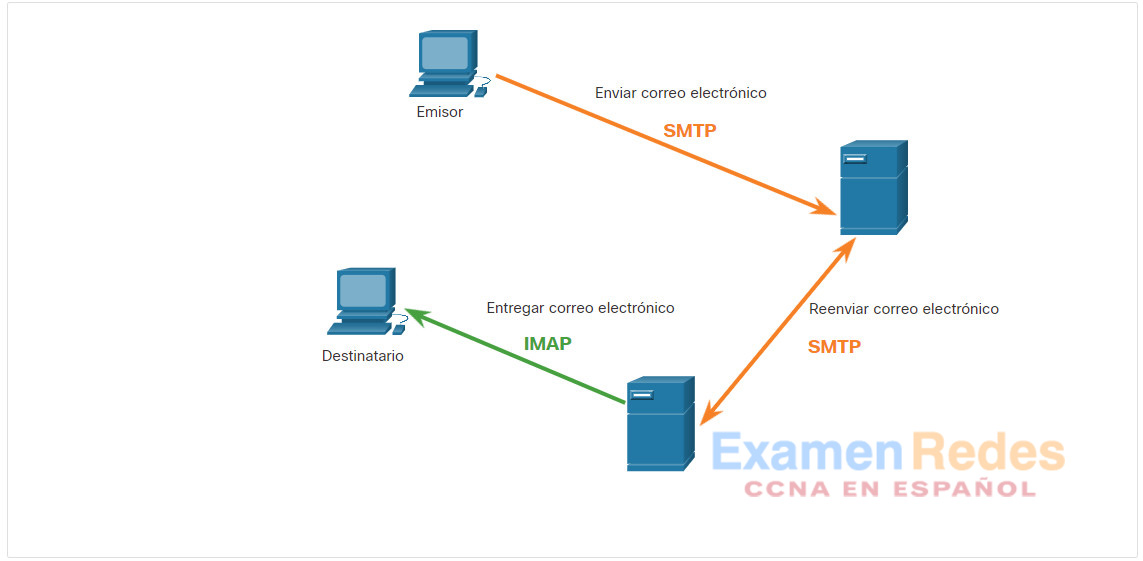
10.5.4. IMAP
IMAP es otro protocolo que describe un método para recuperar mensajes de correo electrónico, como se ve en la figura. A diferencia de POP3, cuando el usuario se conecta a un servidor compatible con IMAP, se descargan copias de los mensajes a la aplicación cliente. Los mensajes originales se mantienen en el servidor hasta que se eliminen manualmente. Los usuarios ven copias de los mensajes en su software de cliente de correo electrónico.
Los usuarios pueden crear una jerarquía de archivos en el servidor para organizar y guardar el correo. Dicha estructura de archivos se duplica también en el cliente de correo electrónico. Cuando un usuario decide eliminar un mensaje, el servidor sincroniza esa acción y elimina el mensaje del servidor.
10.6. HTTP
10.6.1. Protocolo de transferencia de hipertexto y lenguaje de marcado de hipertexto
Existen protocolos específicos de la capa de aplicación diseñados para usos comunes, como la navegación web y el correo electrónico. El primer tema le dio una visión general de estos protocolos. Este tema entra en más detalle.
Cuando se escribe una dirección web o un localizador uniforme de recursos (Uniform Resource Locator)(URL) en un navegador web, el navegador establece una conexión con el servicio web. El servicio web se está ejecutando en el servidor que está utilizando el protocolo HTTP. Los nombres que la mayoría de las personas asocia con las direcciones web son URL e identificador uniforme de recursos (URI).
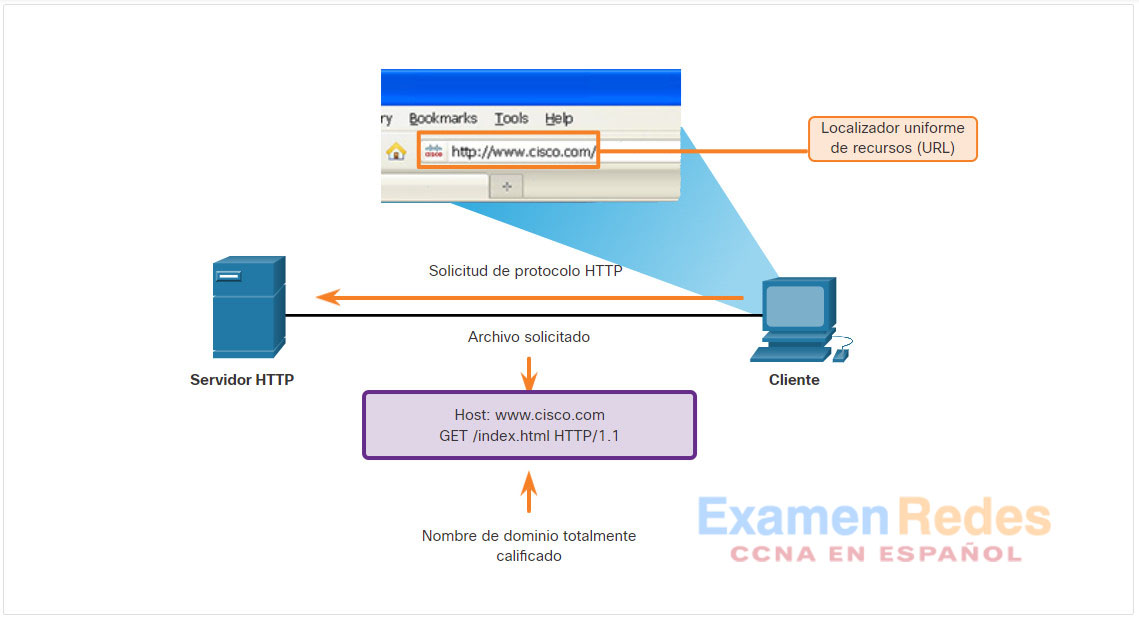
Para comprender mejor cómo interactúa el navegador web con el servidor web, podemos analizar cómo se abre una página web en un navegador. Para este ejemplo, utilice el URL http://www.cisco.com/index.html.
Haga clic en cada botón para obtener más información.
- Paso 1
- Paso 2
- Paso 3
- Paso 4
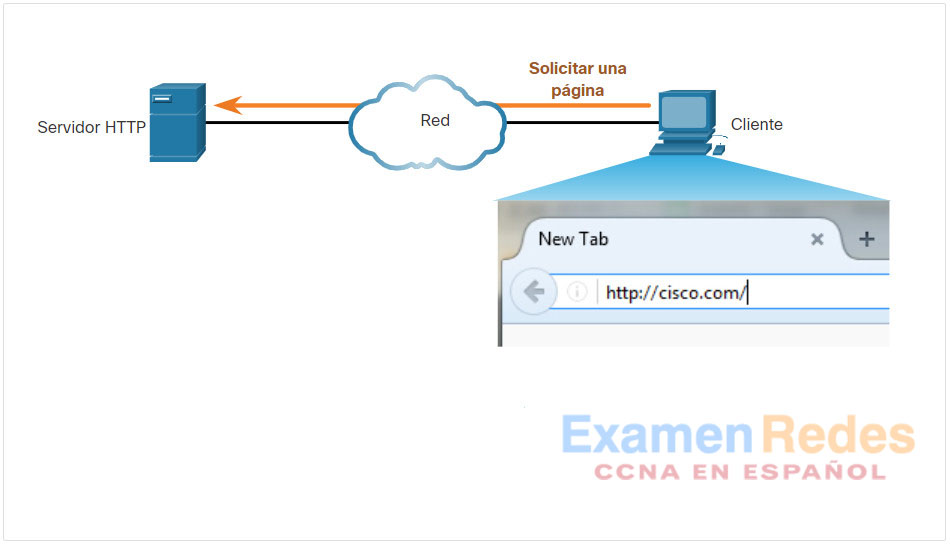
El explorador interpreta las tres partes del URL:
- http (el protocolo o esquema)
- www.cisco.com (el nombre del servidor)
- index.html (el nombre de archivo específico solicitado)
El navegador luego verifica con un Servidor de nombres de dominio (DNS) para convertir a www.cisco.com en una dirección numérica que utiliza para conectarse con el servidor. El cliente inicia una solicitud HTTP a un servidor enviando una solicitud GET al servidor y solicita el archivo index.html.
En respuesta a la solicitud, el servidor envía el código HTML de esta página web al navegador.
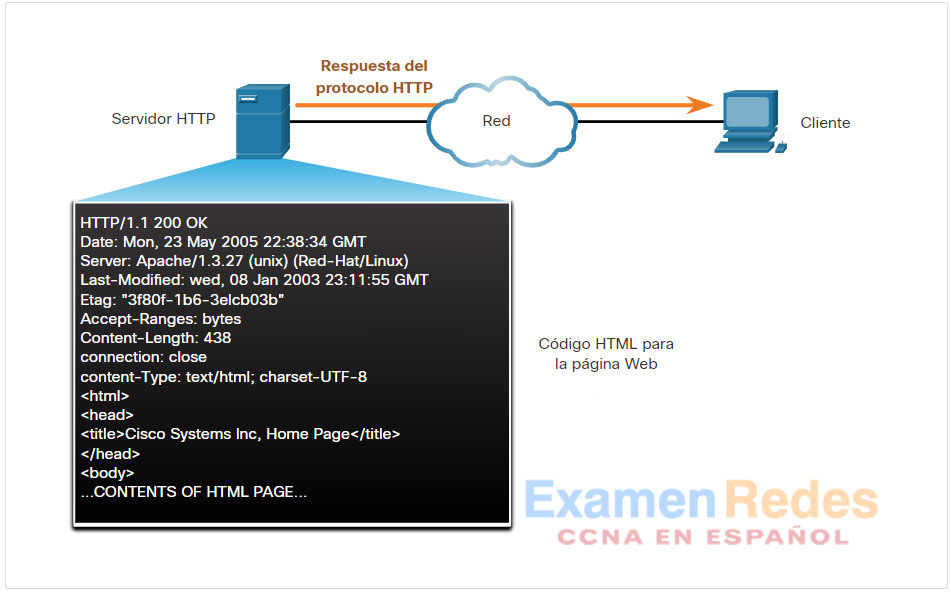
El navegador descifra el código HTML y da formato a la página para que se pueda visualizar en la ventana del navegador.
10.6.2. La URL de HTTP
Las URL de HTTP también pueden especificar el puerto en el servidor que debe manejar los métodos de HTTP. Además, puede especificar una cadena y un fragmento de la consulta. Normalmente, la cadena de la consulta contiene información que no maneja el propio proceso del servidor HTTP, sino otro proceso que se ejecuta en el servidor. Las cadenas de la consulta comienzan con un carácter “?” y, normalmente, constan de una serie de pares de nombre y valor. Un fragmento comienza con un carácter “#”. Hace referencia a una parte subordinada del recurso que se solicita en la URL. Por ejemplo, un fragmento puede hacer referencia a un delimitador nombrado en un documento HTML. La URL tendrá acceso al documento y, luego, se dirigirá a la parte del documento especificada por el fragmento si existe un enlace del delimitador nombrado que coincida en el documento. En la figura, se ve una URL de HTTP que incluye estas partes.

Esta URL solicita el uso de HTTP para tener acceso al servidor de example.com mediante el puerto 8080. Desde el directorio de sonidos devuelva el documento con la ID 973285 con formato mp4 (un archivo de sonido mp4) en la posición 00 minutos y 00 segundos (el comienzo del archivo de sonido).
10.6.3. Operación HTTP
HTTP es un protocolo de solicitud y respuesta que utiliza el puerto TCP 80, aunque se pueden utilizar otros puertos. Cuando un cliente (normalmente, un navegador web) envía una solicitud a un servidor web, utiliza uno de los seis métodos que especifica el protocolo HTTP.
- GET – Solicitud de datos por parte del cliente. Un cliente (navegador web) envía el mensaje GET al servidor web para solicitar las páginas HTML, como se ve en la figura.
- POST – Envía datos para que los procese un recurso.
- PUT – Carga los recursos o el contenido, como por ejemplo una imagen, en el servidor web.
- DELETE – Borra el recurso especificado.
- OPTIONS – Enumera los métodos HTTP que admite el servidor.
- CONNECT – Solicita que un servidor proxy HTTP reenvíe la sesión TCP de HTTP al destino deseado.
Aunque HTTP es sumamente flexible, no es un protocolo seguro. Los mensajes de solicitud envían información al servidor en texto sin formato que puede ser interceptado y leído. Las respuestas del servidor, generalmente páginas HTML, también están sin cifrar.
10.6.4. Códigos de estado de HTTP
Las respuestas del servidor HTTP se identifican con diversos códigos de estado que le informan a la aplicación host el resultado de las solicitudes que el cliente le realiza al servidor. Los códigos se organizan en cinco grupos. Los códigos son numéricos y el primer número del código indica el tipo de mensaje. Los cinco grupos de códigos de estado son los siguientes:
- 1xx – Informativo
- 2xx – Operación exitosa
- 3xx – Redireccionamiento
- 4xx – Error en cliente
- 5xx – Error en servidor
En la figura, se ve una explicación de algunos códigos de estado comunes. Un excelente recurso para obtener detalles sobre códigos de estado específicos se puede encontrar buscando «rest api tutorial» y «códigos de estado HTTP». Los códigos de estado HTTP se muestran en el tráfico de cliente/servidor HTTP y son útiles para las investigaciones de ciberseguridad.
| Código | Estado | Significado |
|---|---|---|
| 1xx – Informativo | ||
| 100 | Continuar | El cliente debe continuar con la solicitud. El servidor ha verificado que la solicitud se puede cumplir. |
| 2xx – Operación exitosa | ||
| 200 | OK | La solicitud se completó correctamente. |
| 202 | Aceptada | La solicitud ha sido aceptada para su procesamiento, pero el procesamiento no está terminado. |
| 4xx – Error en cliente | ||
| 403 | Prohibida | El servidor entiende la solicitud, pero el recurso no se cumplirá. Esto se debe posiblemente a que el solicitante no está autorizado para ver el recurso. |
| 404 | No se encontró | El servidor no puede encontrar el recurso solicitado. Esto puede deberse a una URL obsoleta o incorrecta. |
10.6.5. HTTP/2
HTTP/2 es una revisión importante de la especificación del protocolo HTTP. El propósito de HTTP/2 es mejorar el rendimiento HTTP abordando problemas de latencia que existían en la versión HTTP 1.1 del protocolo. HTTP/2 utiliza el mismo formato de encabezado que HTTP 1.1 y utiliza los mismos códigos de estado. Sin embargo, hay muchas características importantes de HTTP/2 que un analista de ciberseguridad debe tener en cuenta.
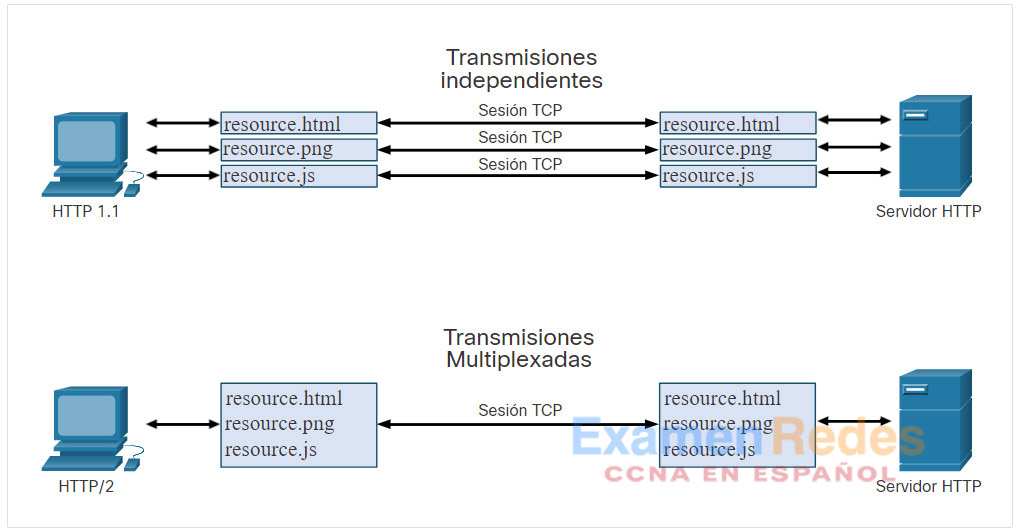
- Multiplexación : los servidores HTTP y los clientes llevan a cabo conversaciones llamadas transmisiones para cada transacción. Por ejemplo, un cliente se conectará a un servidor HTTP, solicitará recursos de ese servidor y recibirá los recursos solicitados. Con HTTP 1.1, solo se admitió una transmisión en el momento. Con HTTP/2, un cliente y un servidor pueden tener múltiples transmisiones ejecutándose entre ellos al mismo tiempo a través de la misma conexión TCP, como se muestra en la figura. Esto proporciona una eficiencia mucho mayor al protocolo.
- Servidor PUSH : los servidores HTTP pueden enviar contenido que aún no se ha solicitado al cliente. El servidor anticipa el contenido que es probable que el cliente solicite. El cliente almacena en caché este contenido para su uso futuro.
- Un protocolo binario : en HTTP 1.1, los comandos, como las solicitudes de cliente a servidor, se realizan en formato de texto. HTTP/2 ha cambiado a usar comandos binarios. Esto supera algunos problemas engorrosos con la versión anterior, reduce la sobrecarga de solicitudes y respuestas, reduce la latencia y mejora el rendimiento.
- Compresión de encabezado : los encabezados de solicitud y respuesta HTTP se comprimen para reducir aún más la cantidad de ancho de banda requerido por las secuencias HTTP/2.
10.6.6. Asegurando HTTP ─ HTTPS
Para una comunicación segura a través de Internet, se utiliza el protocolo HTTP seguro (HTTPS). HTTPS utiliza el puerto TCP 443. HTTPS utiliza autenticación y cifrado para proteger los datos mientras viajan entre el cliente y el servidor. HTTPS utiliza el mismo proceso de solicitud del cliente y respuesta del servidor que HTTP, pero el flujo de datos se encripta con la capa de sockets seguros (SSL) o la seguridad de la capa de transporte (TLS) antes de transportarlo por la red. Aunque SSL es el predecesor de TLS, ambos protocolos suelen denominarse SSL.
HTTPS/2 se especifica para utilizar HTTPS sobre TLS con la extensión de negociación de protocolo de capa de aplicación (ALPN) para TLS 1.2 o posterior. El estándar HTTP/2 no especifica el cifrado; sin embargo, todas las aplicaciones de software cliente principales lo requieren. Por lo tanto, se puede suponer que HTTP/2 está encriptado.
Mucha información confidencial se transmite por Internet usando HTTPS, como las contraseñas, los datos de tarjetas de crédito y la información médica.
10.6.7. Práctica de laboratorio: Utilizar Wireshark para examinar tráfico HTTP y HTTPS
En esta práctica de laboratorio se cumplirán los siguientes objetivos:
- Capturar y ver tráfico HTTP
- Capturar y ver tráfico HTTPS
10.7. Resumen de servicios de red
10.7.1. ¿Qué Aprendí en este Módulo?
DHCP
El Protocolo de Configuración de Host Dinámico (Dynamic Host Configuration Protocol) (DHCP) automatiza la asignación de direcciones IPv4. Esto se conoce como la alternativa al direccionamiento estático y es el direccionamiento dinámico. En redes más grandes, o donde la población de usuarios cambia con frecuencia, el direccionamiento dinámico es a menudo el método preferido para la asignación de direcciones. Muchas redes utilizan ambos métodos. DHCP se utiliza para hosts de propósito general, como dispositivos finales de usuario. El direccionamiento estático se utiliza para los dispositivos de red, tales como (puertas de enlace )gateways, switches, servidores e impresoras.
Cuando un dispositivo configurado con IPv4 DHCP se inicia o se conecta a la red, el cliente transmite un mensaje de descubrimiento de DHCP (DHCPDISCOVER) para identificar cualquier servidor DCHP que esté disponible en la red. Un servidor DHCP responde con un mensaje de oferta DCHP (DHCPOFFER), que ofrece una concesión al cliente. El mensaje de oferta contiene la dirección IPv4 y la máscara de subred que se deben asignar, la dirección IPv4 del servidor DNS y la dirección IPv4 del gateway predeterminado. El cliente puede recibir varios mensajes de OFERTA DHCP si hay más de un servidor DHCP en la red local. Debe elegir entre ellos y envía un mensaje DCHPREQUEST que identifica el servidor explícito y la oferta de arrendamiento que el cliente está aceptando. Si la dirección IPv4 aún está disponible, el servidor devuelve un mensaje DHCPACK. Si la oferta ya no es válida, devolverá un mensaje DCHPNACK. El formato del mensaje DHCPv4 se utiliza para todas las transacciones DHCPv4. Los mensajes DHCPv4 se encapsulan dentro del protocolo de transporte UDP.
Descripción general de DNS
El sistema de nombres de dominio (DNS) se desarrolló para proporcionar un medio confiable de administrar y proporcionar los nombres de dominio y sus direcciones IP asociadas. El sistema de DNS se compone de una jerarquía global de servidores distribuidos que contienen bases de datos con asignaciones de nombre para las direcciones IP. Los analistas de ciberseguridad deben tener un conocimiento profundo del DNS porque un análisis reciente de las amenazas a la seguridad de la red descubrió que más del 90% del software malicioso que se usa para atacar las redes usa el sistema DNS para llevar a cabo campañas de ataque.
Los siguientes son los pasos involucrados en la resolución de DNS:
- El usuario escribe un FQDN en un campo de dirección del navegador.
- Se envía una consulta de DNS al servidor DNS designado.
- El servidor DNS hace coincidir el FQDN con su dirección IP.
- La respuesta de la consulta de DNS se envía de vuelta al cliente con la dirección IP para el FDQN.
- El equipo cliente utiliza la dirección IP para enviar solicitudes al servidor.
DNS utiliza el puerto UDP 53 para las consultas y respuestas de DNS. El servidor DNS almacena los diferentes tipos de RR utilizados para resolver nombres. Estos registros contienen el nombre, la dirección y el tipo de registro. Este formato de mensaje que se ve en la figura se utiliza para todos los tipos de solicitudes de clientes y respuestas del servidor, para los mensajes de error y para la transferencia de información de registro de recursos entre servidores. DNS dinámico (DDNS) le permite a un usuario u organización registrar una dirección IP con un nombre de dominio, al igual que en DNS. Sin embargo, cuando la dirección IP del mapeo cambia, el nuevo mapeo se puede propagar por todo el DNS casi instantáneamente. Los agentes de amenazas pueden abusar de DDNS de varias maneras y las URL que usan DDNS deben ser sospechosas. WHOIS es un protocolo basado en TCP que se utiliza para identificar a los propietarios de dominios de Internet a través del sistema DNS. WHOIS tiene limitaciones y los hackers tienen maneras de ocultar su identidad.
NAT
NAT proporciona la traducción de direcciones privadas a direcciones públicas. Esto permite que los dispositivos con direcciones IPv4 privadas accedan a recursos fuera de su red privada, como los que se encuentran en Internet. NAT ayuda a conservar las direcciones IPv4 públicas. Los routers con NAT habilitada se pueden configurar con una o más direcciones IPv4 públicas válidas. Estas direcciones se conocen como grupo NAT. En general, los routers NAT funcionan en la frontera de una red de rutas internas. Cuando un dispositivo dentro de la red de rutas internas desea comunicarse con un dispositivo fuera de su red, el paquete se reenvía al router de frontera. El enrutador de borde realiza el proceso NAT, traduciendo la dirección privada interna del dispositivo a la dirección pública, externa y enrutable. La traducción de la dirección del puerto (PAT), también conocida como “NAT con overload”, asigna varias direcciones IPv4 privadas a una única dirección IPv4 pública o algunas direcciones.
Servicios de transferencia de archivos y uso compartido
El Protocolo de transferencia de archivos (FTP) es otro protocolo de capa de aplicación de uso común. Fue desarrollado para permitir transferencias de archivos entre un cliente y un servidor. Para transferir archivos correctamente, FTP requiere dos conexiones entre el cliente y el servidor: una para comandos y respuestas, y otra para la transferencia de archivos real. El protocolo de transferencia de archivos SSH es una forma segura de FTP que utiliza Secure Shell para proporcionar un canal seguro. El Protocolo de transferencia de archivos trivial (TFTP) es un protocolo de transferencia de archivos simplificado que utiliza el puerto UDP número 69. TFTP es fundamentalmente inseguro. El bloque de mensajes del servidor (SMB) es un protocolo de intercambio de archivos cliente / servidor que describe la estructura de los recursos de red compartidos, como directorios, archivos, impresoras y puertos serie. Los servicios de impresión y el uso compartido de archivos se han convertido en el pilar de las redes de Microsoft.
Correo electrónico
Los clientes de correo electrónico se comunican con servidores de correo para enviar y recibir correo electrónico. Los servidores de correo se comunican con otros servidores de correo para transportar mensajes de un dominio a otro. El correo electrónico soporta tres protocolos separados para funcionar: SMTP, POP e IMAP. El proceso de la capa de aplicación que envía correo desde un cliente a un servidor de correo electrónico utiliza SMTP. Un cliente recupera el correo electrónico de un servidor de correo mediante POP3 o IMAP.
HTTP
Los navegadores web y los servidores web interactúan mediante los siguientes pasos:
- El navegador interpreta las tres partes de la URL.
- El navegador comprueba con un servidor de nombres para convertir una dirección en una dirección IP numérica. El cliente inicia una solicitud HTTP a un servidor enviando una solicitud GET al servidor.
- En respuesta a la solicitud, el servidor envía el HTML de esta página web al navegador.
- El navegador descifra el HTML y muestra la página para la ventana del navegador.
HTTP URLS también puede especificar el puerto en el servidor que debe manejar los métodos HTTP. Además, puede especificar una cadena y un fragmento de la consulta. HTTP es un protocolo de solicitud y respuesta que utiliza el puerto TCP 80, aunque se pueden utilizar otros puertos. Cuando un cliente envía una solicitud a un servidor web, utiliza uno de los seis métodos especifcados en el protocolo HTTP: GET, POST, PUT, DELETE, OPTIONS y CONNECT. HTTP es flexible pero no seguro. Las respuestas del servidor HTTP se identifican con códigos de estado organizados en cinco grupos de códigos: 1xx, 2xx, 3xx, 4xx y 5xx. HTTP/2 es una revisión importante de la especificación del protocolo HTTP que está diseñada para mejorar el rendimiento HTTP solucionando problemas de latencia. Para una comunicación segura a través de Internet, se utiliza HTTP seguro (HTTPS). HTTPS usa la autenticación y ecriptación para asegurar los datos mientras viajan entre el cliente y el servidor.