Última actualización: abril 1, 2022
28.0. Introducción
28.0.1. ¿Por qué deberíamos tomar este módulo?
Ha aprendido todo sobre los diferentes vectores de ataque que puede necesitar proteger, herramientas y prácticas para proteger su sistema. En este último módulo, aprenderás qué hacer cuando realmente ocurra un ataque.
28.0.2. ¿Qué aprenderemos en este módulo?
Título del módulo: Modelos de respuesta ante los incidentes
Objetivo del módulo: Explique cómo CyberOps Associate responde a los incidentes de ciberseguridad.
| Objetivo | Objetivo del tema |
|---|---|
| Manejo de evidencia y atribución del ataque | Explicar la función de los procesos forenses digitales. |
| La Cadena de eliminación cibernética | Identificar los pasos en la cadena de eliminación cibernética. |
| Análisis del modelo de diamante de las intrusiones | Clasificar un evento de intrusión mediante el modelo de diamante. |
| Respuesta ante los incidentes | Aplique los procedimientos de manejo de incidentes NIST 800-61r2 para una situación de incidentes determinada. |
28.1. Manejo de evidencia y atribución del ataque
28.1.1. Informática forense digital
Ahora que se han investigado e identificado las alertas válidas, ¿qué se debe hacer con las pruebas? Inevitablemente, el analista especializado en ciberseguridad descubrirá evidencia de actividades delictivas. Con el fin de proteger la organización y para evitar la ciberdelincuencia, es necesario identificar los agentes de amenaza, informar a las autoridades competentes y brindar pruebas para respaldar la acusación. Los analistas de ciberseguridad de categoría 1 suelen ser los primeros en descubrir delitos. Deben saber cómo manejar la evidencia correctamente y atribuírsela a los agentes de amenaza.
La informática forense digital consiste en la recuperación e investigación de la información que se encuentra en dispositivos digitales en relación con actividades delictivas. Los indicadores de compromiso son la evidencia de que se ha producido un incidente de ciberseguridad. Esta información puede consistir en datos en dispositivos de almacenamiento, en la memoria volátil de la computadora, o los rastros de ciberdelincuencia que se conservan en los datos de la red, como pcaps y registros. Es esencial que se conserven todos los indicadores de compromiso para futuros análisis y atribución de ataques.
En términos generales, la ciberdelincuencia se puede caracterizar como proveniente del interior o el exterior de la organización. Las investigaciones privadas se realizan a individuos dentro de la organización. Estos individuos podrían simplemente comportarse de maneras que violan los acuerdos de usuario o manifestar otra conducta no delictiva. Cuando los individuos son sospechosos de participar en actividades delictivas que involucran el robo o la destrucción de propiedad intelectual, una organización puede optar por involucrar a las autoridades encargadas del orden público, en cuyo caso la investigación se vuelve pública. Los usuarios internos también pueden usar la red de la organización para llevar a cabo otras actividades delictivas que no están relacionadas con la misión de la organización, pero sí violan diversas leyes. En este caso, los funcionarios públicos llevarán a cabo la investigación.
Cuando un atacante externo ataca una red y roba o altera datos, es necesario recopilar evidencia para documentar el alcance del ataque. Diversos organismos reguladores especifican una serie de acciones que una organización debe adoptar cuando se ponen en riesgo distintos tipos de datos. Los resultados de la investigación forense pueden ayudar a identificar las medidas que deben tomarse.
Por ejemplo, las regulaciones de US HIPAA estipulan que, si ocurre una violación de datos que involucra información de pacientes, se debe notificar a las personas afectadas. Si la violación involucra a más de 500 personas en un estado o jurisdicción, se debe notificar también a los medios de comunicación. La investigación de informática forense digital debe utilizarse para determinar qué personas fueron afectadas y certificar la cantidad de individuos involucrados a fin de que pueda efectuarse la notificación correspondiente de acuerdo con las reglas de la HIPAA.
Es posible que la propia organización sea objeto de una investigación. Los analistas de ciberseguridad pueden encontrarse en contacto directo con evidencia forense digital que detalle la conducta de los miembros de la organización. Los analistas deben conocer los requisitos relativos a la preservación y el manejo de dicha evidencia. Si no lo hacen correctamente, esto podría ocasionar sanciones penales para la organización y hasta para el analista de ciberseguridad si se establece que hubo intención de destruir pruebas.
28.1.2. El proceso de informática forense digital
Es importante que una organización desarrolle procesos y procedimientos bien documentados para el análisis forense digital. El cumplimiento reglamentario puede exigir esta documentación y las autoridades pueden inspeccionarla en caso de una investigación pública.
NIST Special Publication 800-86 Guide to Integrating Forensic Techniques in Incident Response es un recurso valioso para las organizaciones que requieren orientación en el desarrollo de planes forenses digitales. Por ejemplo, se recomienda que la investigación forense se realice utilizando el proceso de cuatro fases.
A continuación se describen las cuatro fases básicas del proceso forense de pruebas digitales.
El proceso forense de evidencia digital
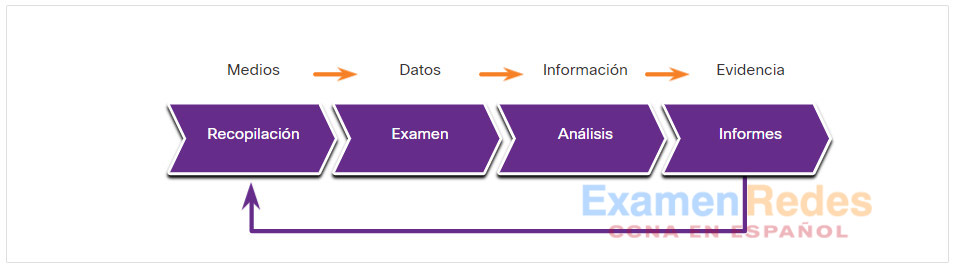
- Paso 1: Recopilación
- Paso 2: Examen
- Paso 3: Análisis
- Paso 4: Generación de informes
28.1.4. Tipos de evidencia
En los procedimientos legales y en términos generales, la evidencia se clasifica como directa o indirecta. La evidencia directa es aquella consta de la evidencia que indudablemente poseía el acusado o de afirmaciones de un testigo presencial que vio directamente el comportamiento delictivo.
Adicionalmente, la evidencia se clasifica del siguiente modo:
- Mejor evidencia – Esta es la evidencia en su estado original. Esta evidencia podrían ser los dispositivos de almacenamiento utilizados por un acusado o archivos que se pueda probar que no fueron alterados.
- Evidencia confirmatoria – Es la evidencia que respalda una afirmación desarrollada a partir de la mejor evidencia.
- Evidencia indirecta – Es la que, combinada con otros hechos, establece una hipótesis. También se conoce como evidencia circunstancial. Por ejemplo, la existencia de pruebas que demuestren que un individuo ya cometió delitos similares puede respaldar la afirmación de que la persona cometió el delito del que se la acusa.
28.1.6. Orden de recopilación de evidencia
IETF RFC 3227 proporciona pautas para la recopilación de evidencia digital. Describe un orden para la recopilación de evidencia digital según la volatilidad de los datos. Los datos almacenados en la memoria RAM son los más volátiles y se perderán cuando se apague el dispositivo. Además, podría suceder que los datos importantes en la memoria volátil se sobrescriban mediante procesos rutinarios de la máquina. Por lo tanto, la recopilación de evidencia digital debe comenzar con las pruebas más volátiles hasta llegar a las menos volátiles, como se muestra en la figura.
Prioridad de recolección de pruebas
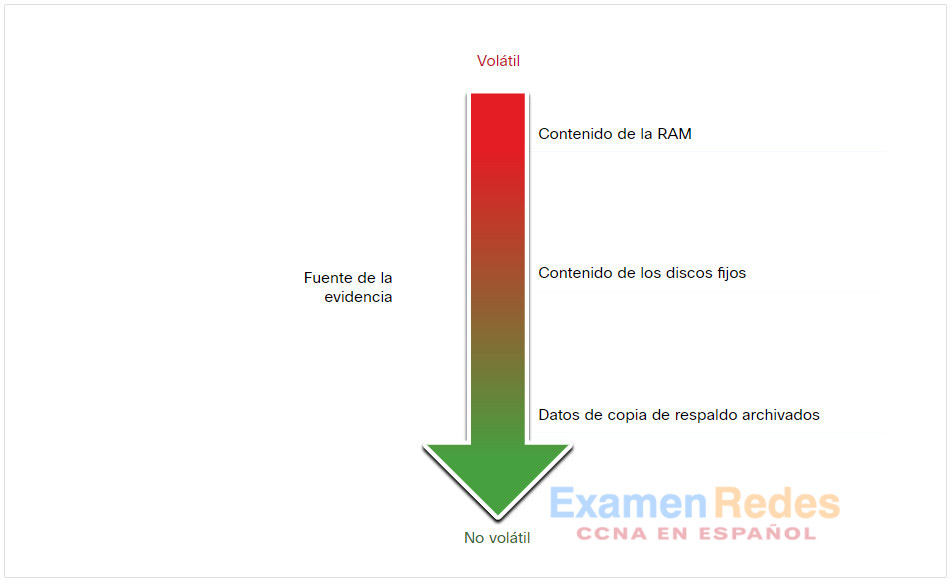
Un ejemplo de la recolección de evidencia ordernado por la mas volátil a la menos volátil sería:
- Registros de memoria, cache
- Tabla de enrutamiento, ARP cache, tabla de procesamiento, estadísticas del Kernel, RAM
- Sistema temporal de archivos
- Medio no-volátil, fijo y retirable
- Inicio de sesión remota y monitoreo de datos
- Interconexiones físicas y topologías
- Medios de almacenamiento, tape u otros de respaldo
Detalles del sistema de donde se capturó la evidencia, incluyendo quién tiene acceso a ese sistema y qué nivel de permiso deberían capturar. Dichos detalles deben incluir configuraciones de hardware y software desde el sistema de donde los datos fueron obtenidos.
28.1.7. Cadena de custodia
Aunque es posible que la evidencia se haya recopilado de fuentes que respaldan la atribución del delito a un individuo acusado, puede cuestionarse la veracidad de las pruebas aduciendo que podrían haberse alterado o fabricado después de la recopilación. Para contrarrestar este argumento, debe definirse y respetarse una rigurosa cadena de custodia.
La cadena de custodia implica la recopilación, el manejo y el almacenamiento seguro de la evidencia. Deben mantenerse registros detallados de lo siguiente:
- ¿Quién descubrió y recopiló la evidencia?
- Todos los detalles sobre el manejo de la evidencia, incluidos momentos, lugares y personal involucrado.
- ¿Quién era el responsable principal de la evidencia, cuándo se le asignó la responsabilidad y cuándo cambió la custodia?
- Quién tiene acceso físico a la evidencia mientras está almacenada. El acceso debe limitarse solamente al personal esencial.
28.1.8. Integridad y preservación de los datos
Al recopilar datos, es importante que se conserven en su estado original. La marca de hora de los archivos debe conservarse. Por esto, debe copiarse la evidencia original y los análisis deben realizarse solamente en las copias del original. Esto permite evitar la pérdida o modificación accidental de las pruebas. Dado que las marcas de hora pueden formar parte de la evidencia, se debe evitar abrir archivos desde el medio original.
Deberá registrarse el proceso utilizado para crear copias de la evidencia que se utiliza en la investigación. Siempre que sea posible, las copias deben ser copias directas de nivel de bit de los volúmenes de almacenamiento originales. Debería ser posible comparar la imagen del disco archivado y la imagen del disco investigada para identificar si se ha manipulado el contenido del disco investigado. Por esta razón, es importante archivar y proteger el disco original para mantenerlo en su condición original, sin alteraciones.
La memoria volátil podría contener evidencia forense, por lo que deben utilizarse herramientas especiales para preservar dicha evidencia antes de que el dispositivo se apague y las pruebas se pierdan. Los usuarios no deben desconectar, desenchufar ni apagar máquinas infectadas, a menos que el personal de seguridad lo indique explícitamente.
El seguimiento de estos procesos garantizará que se conserven todas las pruebas de conducta ilícita y que se puedan identificar indicadores de avenencia.
28.1.9. Atribución de ataques
Después de que se ha evaluado el nivel del ciberataque y se ha recopilado y preservado la evidencia, el equipo de respuesta ante los incidentes puede comenzar a identificar el origen del ataque. Como sabemos, existe una amplia variedad de actores de amenazas, que abarca desde individuos descontentos y hackers, hasta ciberdelincuentes y bandas criminales o incluso naciones. Algunos delincuentes actúan desde el interior de la red, mientras que otros pueden estar del otro lado del mundo. La sofisticación de la ciberdelincuencia también varía. Las naciones pueden emplear a grandes grupos de individuos altamente capacitados para llevar a cabo un ataque y ocultar sus rastros, mientras que otros agentes de amenaza pueden elegir presumir abiertamente de sus actividades delictivas.
La atribución de una amenaza hace referencia a la acción de determinar a la persona, organización o nación responsable de una intrusión o ataque exitosos.
La identificación de los actores responsables de una amenaza debe darse por medio de la investigación sistemática y fundamentada de la evidencia. Mientras que puede resultar útil especular también sobre la identidad de los agentes de amenaza identificando posibles motivaciones para un incidente, es importante no dejar que esto desvíe la investigación. Por ejemplo, atribuir un ataque a un competidor comercial puede desviar la investigación de la posibilidad de que una banda criminal o una nación sean los responsables.
En las investigaciones con base en evidencias, el equipo de respuesta ante los incidentes correlaciona las tácticas, las técnicas y los procedimientos (TTP, Tactics, Techniques and Procedures) empleados en el incidente con los de otros ataques conocidos. Los ciberdelincuentes, al igual que muchos otros delincuentes, tienen características específicas que se repiten en la mayoría de sus delitos. Las fuentes de inteligencia de amenazas pueden ayudar a relacionar las TTP identificadas por una investigación con fuentes conocidas de ataques similares. Sin embargo, esto pone de relieve un problema con la atribución de la amenaza. Es muy improbable que la evidencia de ciberdelincuencia sea directa. Identificar similitudes entre las TTP de agentes de amenazas conocidos y desconocidos es evidencia circunstancial.
Algunos aspectos de una amenaza que pueden ayudar a la atribución son la ubicación de los hosts o dominios originarios, las características del código utilizado en malware, las herramientas utilizadas y otras técnicas. A veces, en el ámbito de la seguridad nacional, no es posible atribuir abiertamente las amenazas porque esto dejaría al descubierto métodos y capacidades que necesitan protección.
Para las amenazas internas, la administración de activos desempeña un papel fundamental. Descubrir los dispositivos desde donde se inició un ataque puede llevar directamente al agente de amenaza. Las direcciones IP, las direcciones MAC y los registros de DHCP pueden ayudar a rastrear las direcciones usadas en el ataque hasta llegar a un dispositivo específico. Los registros de AAA son muy útiles en este sentido, ya que detallan quién tuvo acceso a los recursos de red, en qué momento lo hizo y qué recursos eran.
28.1.10. El marco MITRE ATT&CK
Una forma de atribuir un ataque es modelar el comportamiento del actor de amenazas. El marco de tácticas adversariales, técnicas y conocimiento común (ATT&CK) de MITRE permite detectar tácticas, técnicas y procedimientos del atacante como parte de la defensa de amenazas y la atribución de ataques. Esto se hace mapeando los pasos de un ataque a una matriz de tácticas generalizadas y describiendo las técnicas que se utilizan en cada táctica. Las tácticas consisten en los objetivos técnicos que un atacante debe lograr para ejecutar un ataque y las técnicas son los medios por los que se realizan las tácticas. Por último, los procedimientos son las acciones específicas tomadas por los actores amenazadores en las técnicas identificadas. Los procedimientos son el uso documentado de técnicas en el mundo real por parte de los actores amenazadores.
El marco MITRE ATT&CK es una base de conocimiento global sobre el comportamiento de los actores de amenazas. Se basa en la observación y el análisis de hazañas del mundo real con el propósito de describir el comportamiento del atacante, no el ataque en sí. Está diseñado para permitir el intercambio automatizado de información mediante la definición de estructuras de datos para el intercambio de información entre su comunidad de usuarios y MITRE.
La figura muestra un análisis de una explotación de ransomware de la excelente caja de arena en línea ANY.RUN. Las columnas muestran las tácticas de matriz de ataque empresarial, con las técnicas que utiliza el malware dispuestas debajo de las columnas. Al hacer clic en la técnica, se enumeran los detalles de los procedimientos que utiliza la instancia específica de malware con una definición, explicación y ejemplos de la técnica.
Nota: Haga una búsqueda en Internet en MITRE ATT&CK para obtener más información sobre la herramienta.
Matriz MITRE ATT&CK para una explotación de ransomware

28.2. La Cadena de eliminación cibernética
28.2.1. Pasos de la cadena de cibereliminación
La cadena de cibereliminación fue desarrollada por Lockheed Martin para identificar y evitar ciberintrusiones. Hay siete pasos a la cadena de eliminación cibernética. Enfocarse en estos pasos ayuda a los analistas a entender las técnicas, herramientas y procedimientos de los atacantes. Al responder a un incidente de seguridad, el objetivo es detectar y detener el ataque lo antes posible en el transcurso de la cadena de eliminación. Cuanto antes se detenga el ataque, menor será el daño y menor será la información que el atacante obtenga acerca de la red atacada.
En la cadena de cibereliminación, se detalla qué debe hacer un atacante para alcanzar su objetivo. Los pasos de la cadena de muerte cibernética se muestran en la figura.
Si el atacante es detenido en cualquier etapa, se rompe la cadena del ataque. Romper la cadena significa que el defensor frustró con éxito la intrusión del agente de amenaza. Los agentes de amenaza tienen éxito solamente si completan el paso 7.
Nota: Agente de amenaza es el término utilizado en este curso para referirse al participante que instiga el ataque. Sin embargo, Lockheed Martin utiliza el término “adversario” en su descripción de la cadena de cibereliminación. Por lo tanto, los términos adversario y atacante, se usan como sinónimos en este tema.
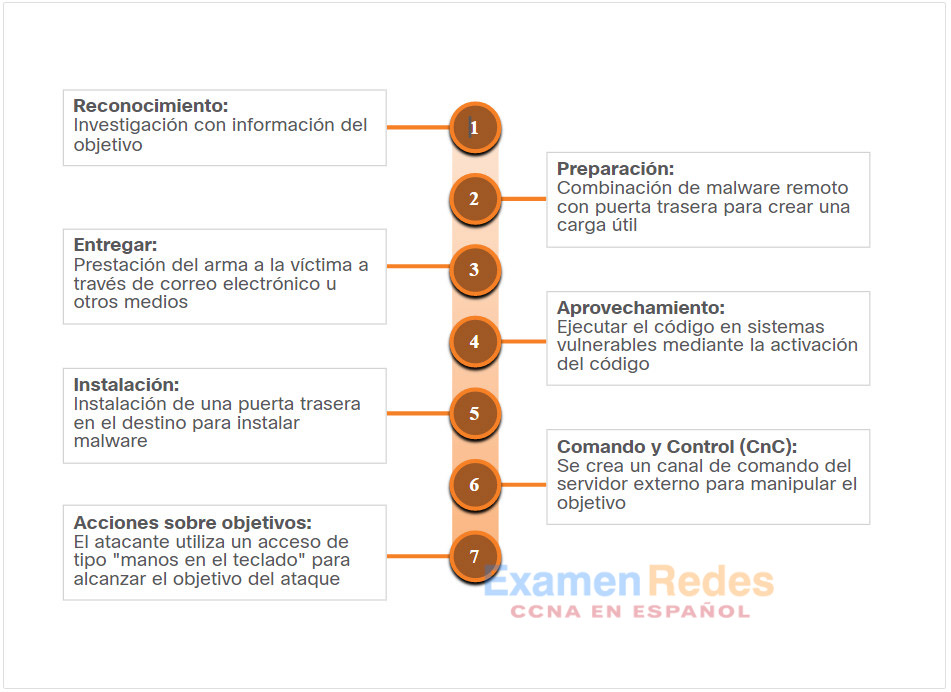
28.2.2. Reconocimiento
El reconocimiento tiene lugar cuando el agente de amenaza realiza una búsqueda, reúne inteligencia y selecciona objetivos. Esto le permite determinar al agente si vale la pena realizar el ataque. Cualquier información pública puede ayudar a determinar qué, dónde, y cómo fue el ataque realizado. Hay mucha información disponible para el público, especialmente en el caso de organizaciones importantes; esto incluye artículos de prensa, sitios web, actas de conferencias y dispositivos de red orientados al público. Cada vez hay más información disponible sobre los empleados en las redes sociales.
El agente de amenaza escogerá objetivos descuidados o sin protección porque es mayor la posibilidad de penetrarlos y atacarlos exitosamente. El agente de amenaza analiza toda la información que obtiene para determinar su importancia y ver si revela otras vías posibles de ataque.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de reconocimiento.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Planificar y dirigir la investigación:
|
Descubrir la intención del atacante:
|
28.2.3. Armamentización
El objetivo de este paso es utilizar la información de reconocimiento para desarrollar un arma contra sistemas o individuos que sean blancos específicos en la organización. Para el desarrollo de esta arma, el diseñador utilizará las vulnerabilidades de los activos que se detectaron y las incorporará en una herramienta que pueda implementarse. Después de que la herramienta se haya utilizado, se espera que el agente de amenaza haya logrado su objetivo de tener acceso al sistema o la red de destino, lo que afecta el estado de un objetivo o de toda la red. El agente de amenaza examinará en más detalle la seguridad de la red y los activos para poner de manifiesto debilidades adicionales, obtener el control de otros activos e implementar ataques adicionales.
No es difícil elegir un arma para el ataque. El agente de amenaza solo necesita ver qué ataques están disponibles para las vulnerabilidades que detectó. Hay muchos ataques prediseñados y ampliamente probados. Uno de los problemas de estos ataques es que, debido a que son tan conocidos, es muy probable que también los conozcan los defensores. A menudo, es más eficaz utilizar un ataque de día cero para evitar los métodos de detección. Un ataque de día cero utiliza un arma desconocida para los defensores y los sistemas de seguridad de la red. El agente de amenaza puede elegir desarrollar su propia arma específicamente diseñada para evitar la detección, con la información que obtuvo sobre la red y los sistemas. Los atacantes han aprendido a crear numerosas variantes de sus ataques para evadir las defensas de la red.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de preparación.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Preparar y organizar la operación:
|
Detectar y reunir artefactos relacionados con las armas:
|
28.2.4. Entrega
Durante este paso, el arma se transmite al objetivo mediante un vector de entrega. Esto puede ocurrir usando un sitio web, un medio USB extraíble o un archivo adjunto de correo electrónico. Si no se entrega el arma, el ataque no tiene éxito. El agente amenaza utilizará muchos métodos diferentes para aumentar las posibilidades de entrega de la carga útil, como encriptar las comunicaciones, modificar el código para que parezca legítimo u ocultar el código. Los sensores de seguridad son tan avanzados que pueden detectar el código malicioso, a menos que se altere para evitarlo. El código puede modificarse para parecer inocente y tener la capacidad de realizar las acciones necesarias, aunque podría demorar más tiempo en ejecutarse.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de entrega.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Iniciar el malware en el objetivo:
|
Aplicación de malware en bloque:
|
28.2.5. Explotación
Una vez aplicada el arma, el actor de la amenaza la utiliza para quebrar la vulnerabilidad y obtener el control del objetivo. Los objetivos de ataque más comunes son las aplicaciones, las vulnerabilidades de sistemas operativos y los usuarios. El atacante debe utilizar un ataque que tenga el efecto deseado. Esto es muy importante porque, si se ejecuta el ataque incorrecto, está claro que no funcionará, pero los efectos secundarios imprevistos, como una denegación de servicio o reinicios reiterados del sistema, llamarán indebidamente la atención de los analistas de ciberseguridad, quienes tomarán conocimiento del ataque y de las intenciones del agente de amenaza.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de aprovechamiento.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Aprovechar una vulnerabilidad para obtener acceso:
|
Capacitar a los empleados, asegurar los códigos y fortalecer los dispositivos:
|
28.2.6. Preparación
En este paso, el agente de amenaza establece una puerta trasera al sistema para poder seguir teniendo acceso al objetivo. Para preservar esta puerta trasera, es importante que el acceso remoto no alerte a los analistas de ciberseguridad ni a los usuarios. Para ser eficaz, el método de acceso debe sobrevivir a los análisis antimalware y al reinicio de la computadora. Este acceso persistente también puede permitir las comunicaciones automatizadas, que resultan especialmente eficaces cuando se necesitan varios canales de comunicación al comandar una botnet.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de instalación.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Instalar una puerta trasera persistente:
|
Detectar, registrar y analizar la actividad de instalación:
|
28.2.7. Comando y control
En este paso, el objetivo es establecer el comando y control (CnC o C2) con el sistema objetivo. Los hosts atacados suelen enviar información fuera de la red a un controlador en Internet. Esto ocurre porque la mayoría del malware requiere la interacción manual para exfiltrar datos de la red. El agente de amenaza utiliza los canales de CnC para emitir comandos al software que instala en el objetivo. El analista de ciberseguridad debe ser capaz de detectar comunicaciones de CnC para descubrir el host atacado. Esto puede hacerse con tráfico no autorizado de Internet Relay Chat (IRC) o tráfico excesivo hacia los dominios sospechosos.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de comando y control.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Abrir canal para la manipulación de destinos:
|
Última oportunidad para bloquear la operación:
|
28.2.8. Acciones en objetivos
El paso final de la cadena de cibereliminación es cuando el agente de amenaza logra su objetivo original. Este puede ser el robo de datos, la ejecución de un ataque de DDoS, o el uso de la red atacada para crear y enviar correo electrónico no deseado o mina de Bitcoin. Llegado este momento, el agente de amenaza está profundamente arraigado en los sistemas de la organización, ocultando sus movimientos y cubriendo sus rastros. Es extremadamente difícil eliminar el agente de amenaza de la red.
La tabla resume algunas de las tácticas y defensas que se utilizan durante el paso de acciones en objetivos.
| Tácticas de los atacantes | Defensas del SOC |
|---|---|
Cosechar los frutos de un ataque exitoso:
|
Detectar mediante evidencias forenses:
|
28.3. Análisis del modelo de diamante de las intrusiones
28.3.1. Descripción general del modelo de diamante
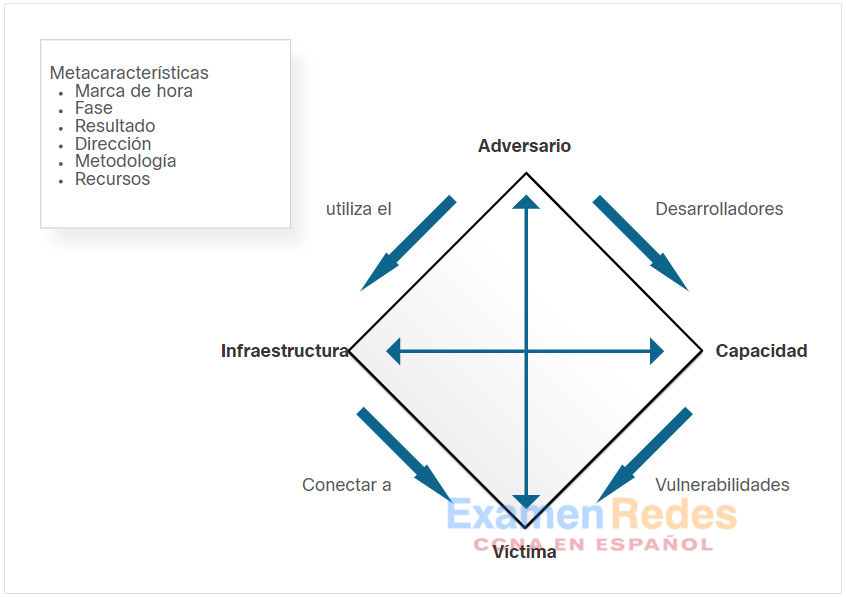
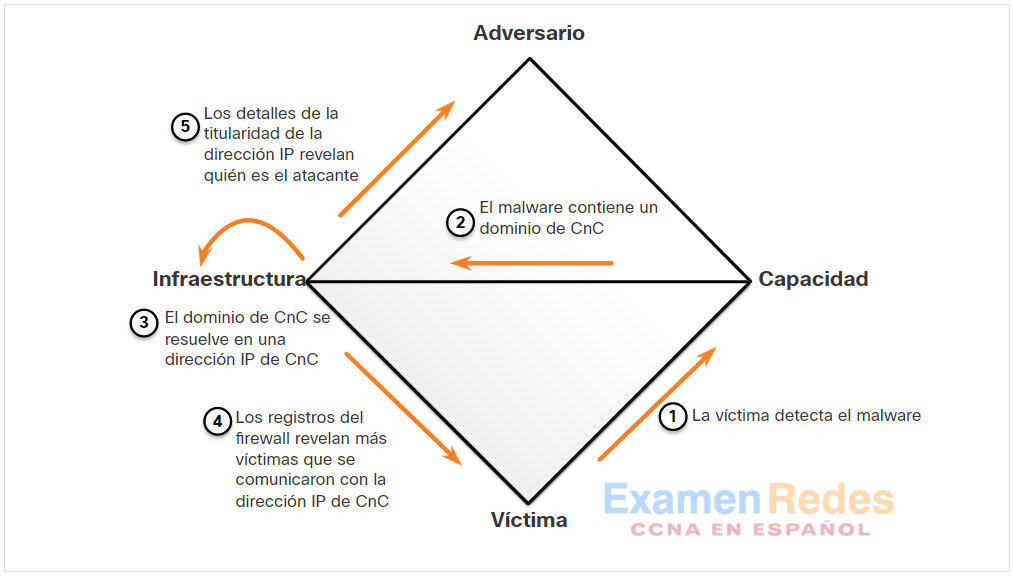
El modelo de diamante para análisis de intrusión está compuesto de cuatro partes, como se muestra en la figura. El modelo representa un incidente o evento de seguridad. En el modelo de diamante, un evento es una actividad de tiempo limitado que está restringido a un paso específico donde el adversario utiliza la capacidad sobre la infraestructura para atacar una víctima para lograr un resultado específico.
Las cuatro características principales de un evento de intrusión son el adversario, la capacidad, la infraestructura y la víctima:
- Adversario – Son los responsables de la intrusión.
- Capacidad – Se trata de una herramienta o técnica que utiliza el adversario para atacar a la víctima.
- Infraestructura – Esta es la ruta o rutas de red que los adversarios utilizan para establecer y mantener el comando y control de sus funcionalidades.
- Víctima – Es el objetivo del ataque. Sin embargo, la víctima podría ser el objetivo inicial y, luego, el atacante puede utilizarla como parte de la infraestructura para iniciar otros ataques.
El adversario utiliza las funcionalidades en la infraestructura para atacar a la víctima. El modelo puede interpretarse como diciendo: «El adversario usa la infraestructura para conectarse con la víctima. El adversario desarrolla la capacidad de explotar a la víctima». Por ejemplo, un adversario podría usar una funcionalidad como el malware sobre la infraestructura de correo electrónico para aprovecharse de la víctima.
Las metacaracterísticas amplían un poco el modelo para incluir los siguientes elementos importantes:
- Marca de hora – Indica la hora de inicio y fin de un evento y es una parte integral de la agrupación de actividad maliciosa.
- Fase – Este concepto es análogo al de los pasos en la cadena de ciber eliminación (Cyber Kill Chain); la actividad maliciosa incluye dos o más pasos ejecutados seguidamente para lograr el resultado deseado.
- Resultado – Define lo que el adversario obtuvo en el evento. Los resultados pueden documentarse como uno o más de los siguientes: confidencialidad afectada, integridad afectada y disponibilidad afectada.
- Dirección – Indica la dirección del evento en el modelo de diamante. Algunas direcciones son adversario a infraestructura, infraestructura a víctima, víctima a infraestructura e infraestructura a adversario.
- Metodología – Se utiliza para clasificar el tipo general del evento, como exploración de puertos, suplantación de identidad, ataque de entrega de contenido, saturación SYN, etc.
- *Recursos – Uno o más recursos externos utilizados por el adversario para el evento de intrusión, como software, conocimiento del adversario, información (por ejemplo, nombre de usuario/contraseñas) y activos para llevar a cabo el ataque (hardware, fondos, instalaciones, acceso a la red).
El modelo de diamante
28.3.2. Cómo desplazarse por el modelo de diamante
Como analistas especializados en ciberseguridad, es posible que se les pida que utilicen el Modelo de diamante de análisis de intrusión para diagramar una serie de eventos de intrusión. El Modelo de diamante es ideal para ilustrar de qué manera el atacante pasa de un evento al siguiente.
Por ejemplo, en la figura, un empleado informa que su computadora se comporta de manera extraña. El técnico de seguridad realiza un análisis del host que indica que la computadora está infectada con malware. Un análisis del malware revela que el malware contiene una lista de nombres de dominio de CnC. Estos nombres de dominio se resuelven en una lista de direcciones IP. Luego, estas direcciones IP se utilizan para identificar al adversario, así como para investigar los registros a fin de determinar si otras víctimas de la organización utilizan el canal de CnC.
Caracterización del modelo de diamante de un exploit
28.3.3. El modelo de diamante y la cadena de cibereliminación
Los adversarios no ejecutan un solo evento. En cambio, los eventos se entretejen en una cadena en la que cada evento debe completarse con éxito antes del siguiente. Esta serie de eventos puede asignarse a la cadena de cibereliminación analizada previamente en el capítulo.
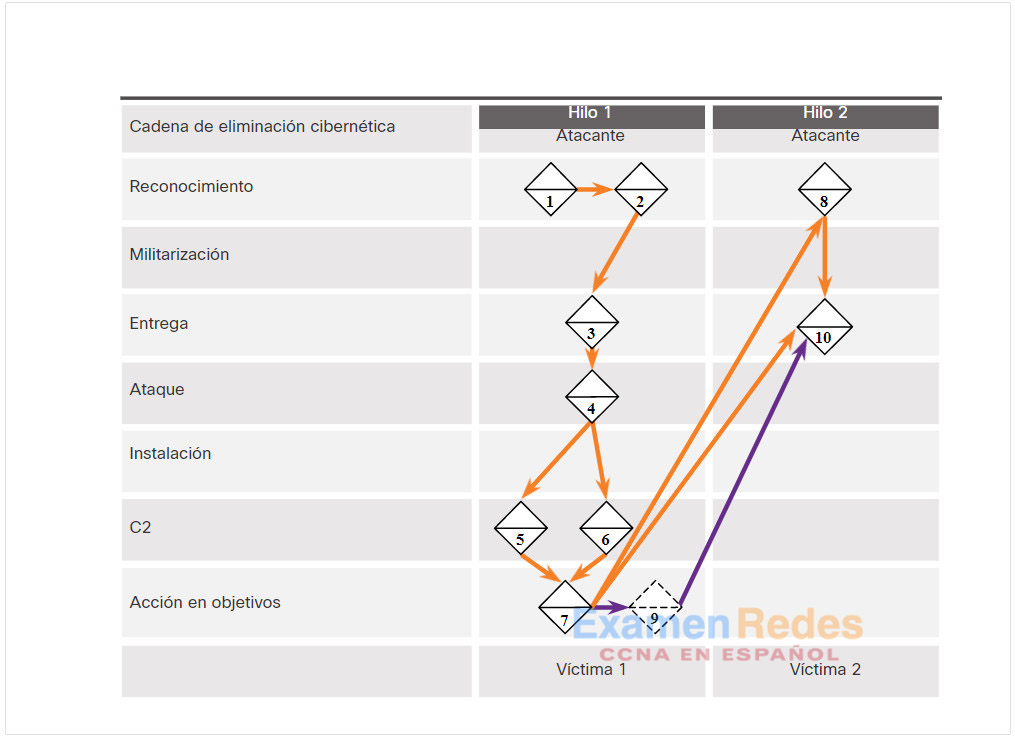
En el siguiente ejemplo (que se muestra en la figura), se ejemplifica el proceso integral de un adversario a medida que atraviesa verticalmente la cadena de cibereliminación, utiliza un host afectado para desplazarse horizontalmente hacia otra víctima, y empieza otro subproceso de la actividad:
1. El adversario realiza una búsqueda web sobre la empresa víctima Gadgets, Inc. y recibe, como parte de los resultados, el nombre de dominio gadgets.com.
2. El adversario utiliza gadgets.com, el dominio que acaba de detectar, para realizar una nueva búsqueda de “administrador de red gadgets.com”. Así, descubre publicaciones de usuarios en los foros alegando que son administradores de red de gadgets.com. Los perfiles de usuario revelan sus direcciones de correo electrónico.
3. El adversario envía correos electrónicos de suplantación de identidad con un troyano adjunto a los administradores de red de gadgets.com.
4. Un administrador de red (NA1) de gadgets.com abre el archivo adjunto malicioso. Esto ejecuta el ataque incluido y permite seguir con la ejecución de código.
5. El host atacado de NA1 envía un mensaje HTTP Post a una dirección IP para registrarla con un controlador de CnC. El host atacado de NA1 recibe una respuesta HTTP.
6. Mediante ingeniería inversa, se revela que el malware tiene direcciones IP adicionales configuradas que actúan como una copia de respaldo si el primer controlador no responde.
7. Mediante un mensaje de respuesta HTTP de CnC enviado al host de NA1, el malware comienza a actuar como un web proxy para nuevas conexiones de TCP.
8. Mediante la información del proxy ejecutado en el host de NA1, el adversario realiza una búsqueda web con las palabras “la investigación más importante de todos los tiempos” y encuentra a la víctima 2, Interesting Research Inc.
9. El adversario consulta la lista de contactos de correo electrónico de NA1 para buscar contactos de Interesting Research, Inc. y descubre el contacto del Director principal de investigaciones de Interesting Research, Inc.
10. El Director principal de investigaciones de Interesting Research, Inc. recibe un correo electrónico de phishing dirigido desde la dirección de correo electrónico de NA1 de Gadget, Inc. enviado desde el host de NA1 con la misma carga útil del evento 3.
El adversario tiene ahora dos víctimas afectadas desde las que puede iniciar ataques adicionales. Por ejemplo, el adversario podría analizar la lista de contactos del Director principal de investigaciones en busca de posibles víctimas adicionales. El adversario también podría configurar otro proxy para exfiltrar todos los archivos del Director principal de investigaciones.
Nota: Este ejemplo es una adaptación del ejemplo de la publicación “El modelo de diamante del análisis de intrusiones”.
La figura muestra el ejemplo del texto anterior.
Ejemplos de hilo de actividad
28.4. Respuesta ante los incidentes
28.4.1. Cómo establecer una capacidad de respuesta ante los incidentes
La respuesta a incidentes implica los métodos, políticas y procedimientos que utiliza una organización para responder a un ataque cibernético. Los objetivos de la respuesta ante incidentes son limitar el impacto del ataque, evaluar los daños causados e implementar procedimientos de recuperación. Debido a la posible pérdida a gran escala de bienes e ingresos que pueden causar los ciberataques, es esencial que las organizaciones creen y mantengan planes detallados de respuesta a incidentes y designen al personal responsable de ejecutar todos los aspectos de ese plan.
Las recomendaciones del NIST (U.S. National Institute of Standards and Technology ) para la respuesta ante los incidentes se detallan en su Publicación especial 800-61 (Revisión 2) titulada “Guía de manejo de incidentes de seguridad informática” que se muestra en la figura.
Nota: Aunque este capítulo resuma gran parte del contenido en el estándar NIST 800-61r2, debería familiarizarse con la publicación entera para cubir todos los temas del examen Entendiendo Operaciones Fundamentales de Cisco Ciberseguridad ( Understanding Cisco Cybersecurity Operations Fundamentals).

El estándar 61r2 800 del NIST proporciona pautas para el manejo de incidentes, especialmente para analizar datos relacionados con el incidente y determinar la respuesta adecuada para cada incidente. Es posible respetar las pautas independientemente de las plataformas de hardware, los sistemas operativos, los protocolos o las aplicaciones que se utilicen.
El primer paso para una organización es establecer una capacidad de respuesta ante los incidentes de seguridad informática (CSIRC, computer security incident response capability). NIST recomienda crear políticas, planes y procedimientos para establecer y mantener un CSIRC.
Elementos de la política
Una política de respuesta ante los incidentes detalla cómo deben manejarse los incidentes de acuerdo con la misión, el tamaño y la función de la organización. La política debe revisarse periódicamente a fin de modificarla para que cumpla con los objetivos de la hoja de ruta que se haya trazado. Entre los elementos de política figuran los siguientes:
- Declaración del compromiso de la gerencia
- Propósito y objetivos de la política
- Alcance de la política
- Definición de incidentes de seguridad informática y términos relacionados
- Estructura organizacional y definición de roles, responsabilidades y niveles de autoridad
- Calificaciones de priorización o gravedad de incidentes
- Acciones de desempeño
- Formularios de informes y contacto
Elementos del plan
Un buen plan de respuesta ante los incidentes ayuda a minimizar el daño causado por un incidente. También ayuda a mejorar el programa de respuesta ante los incidentes en general, ajustándolo según las lecciones aprendidas. El plan debe garantizar que cada parte implicada en la respuesta ante un incidente comprenda claramente lo qué hará y lo qué harán los demás. Los elementos del plan son los siguientes:
- Misión
- Estrategias y metas
- Aprobación de la cúpula gerencial
- Enfoque organizativo para la respuesta ante los incidentes
- Cómo se comunicará el equipo de respuesta ante los incidentes con el resto de la organización y con otras organizaciones
- Métricas para medir la funcionalidad de respuesta ante los incidentes.
- Cómo encaja el programa en la organización general
Elementos del procedimiento
Los procedimientos que se siguen durante una respuesta ante un incidente deben respetar el plan de respuesta ante los incidentes. Los elementos de procedimientos son los siguientes:
- Procesos técnicos
- Usar técnicas
- Rellenar formularios,
- Siguiendo listas de comprobación
Estos son los procesos comunes operativos estándar (SOP) Estos SOP deben ser detallados para tener en mente la misión y los objetivos de la organización cuando se los sigue. Los SOP minimizan los errores que podría causar el personal cuando está bajo presión mientras participa en el manejo de incidentes. Es importante compartir y poner en práctica estos procedimientos, asegurándose de que sean útiles, precisos y adecuados.
28.4.3. Partes interesadas de la respuesta ante los incidentes
Otros grupos e individuos dentro de la organización también pueden estar involucrados en el manejo de incidentes. Es importante asegurarse de que cooperen antes de que ocurra un incidente. Sus conocimientos y habilidades pueden ayudar al CSIRT (Computer Security Incident Response Team) (Equipo de respuesta a incidentes de seguridad informática) a manejar el incidente rápida y correctamente. Estas son algunas de las partes interesadas que pueden estar involucradas en el manejo de un incidente de seguridad:
- Administración – Los administradores crean las políticas que todos deben respetar. También diseñan el presupuesto y están a cargo de dotar de personal a todos los departamentos. La dirección debe coordinar la respuesta ante los incidentes con otras partes interesadas y minimizar el daño causado por el incidente.
- Protección de la información – Es posible que sea necesario convocar a este grupo para cambiar elementos, como las reglas de firewall durante algunas etapas de la gestión de incidentes como por ejemplo, contención o recuperación.
- Soporte de TI – Este es el grupo que trabaja con la tecnología en la organización y la comprende al máximo. Dado que la comprensión de Soporte de TI es muy amplia, es más probable que sean ellos quienes ejecuten las medidas correctas para minimizar la efectividad del ataque o proteger adecuadamente la evidencia.
- Departamento de asuntos legales – Es una mejor práctica tener un departamento de asuntos legales que revise políticas, planes y procedimientos relativos a los incidentes para asegurarse de que no violen pautas locales o federales. Además, si cualquier incidente tiene consecuencias jurídicas, un experto legal tendrá que involucrarse. Esto podría incluir acusaciones, recopilación de evidencia o demandas.
- Relaciones públicas y con los medios – Hay momentos en los que se debe informar sobre un incidente a los medios de comunicación y al público, como cuando se pone en riesgo información personal durante un incidente.
- Recursos Humanos – Es posible que el departamento de Recursos Humanos necesite implementar medidas disciplinarias si el incidente lo causa un empleado.
- Planificadores de continuidad de los negocios – Los incidentes de seguridad pueden alterar la continuidad de los negocios de una organización. Es importante que los responsables de la planificación de continuidad de los negocios conozcan los incidentes de seguridad y su impacto en la totalidad de la organización. Esto les permitirá realizar cambios en los planes y las evaluaciones de riesgo.
- Administración de instalaciones y seguridad física -Cuando ocurre un incidente de seguridad debido a un ataque físico, como la infiltración (tailgating) o mirar por encima del hombro, es posible que sea necesario informar e involucrar a estos equipos. También es su responsabilidad proteger las instalaciones que contienen evidencias de una investigación.
La certificación del modelo de madurez de ciberseguridad
El marco de certificación del modelo de madurez de ciberseguridad (CMMC) fue creado para evaluar la capacidad de las organizaciones que desempeñan funciones para el Departamento de Defensa de los Estados Unidos (DoD) para proteger la cadena de suministro militar de interrupciones o pérdidas debidas a incidentes de ciberseguridad. Las violaciones de seguridad relacionadas con la información del Departamento de Defensa indicaron que las normas NIST no eran suficientes para mitigar el panorama de amenazas cada vez mayor y en evolución, especialmente de los agentes de trato nacional. Para que las empresas reciban contratos del DoD, dichas empresas deben estar certificadas. La certificación consta de cinco niveles, con diferentes niveles requeridos dependiendo del grado de seguridad requerido por el proyecto.
El CMMC especifica 17 dominios, cada uno de los cuales tiene un número variable de capacidades asociadas a él. La organización se califica por el nivel de madurez que se ha alcanzado para cada uno de los dominios. Uno de los dominios se refiere a la respuesta a incidentes. Las capacidades asociadas con el dominio de respuesta a incidentes son las siguientes:
- Planes de respuesta ante los incidentes
- Detectar e informar de eventos
- Desarrollar e implementar una respuesta a un incidente declarado
- Realizar revisiones posteriores a incidentes
- Prueba de respuesta a incidentes
La CMMC certifica las organizaciones por nivel. Para la mayoría de los dominios, hay cinco niveles, sin embargo, para la respuesta a incidentes, sólo hay cuatro. Cuanto mayor sea el nivel certificado, más madura será la capacidad de ciberseguridad de la organización. A continuación se muestra un resumen de los niveles de madurez del dominio de respuesta a la incidencia.
- Nivel 2: establezca un plan de respuesta a incidentes que siga el proceso NIST. Detecte, informe y priorice eventos. Responder a los eventos siguiendo procedimientos predefinidos. Analizar la causa de los incidentes para mitigar problemas futuros.
- Nivel 3 – Documentar e informar a las partes interesadas que hayan sido identificadas en el plan de respuesta a incidentes. Pruebe la capacidad de respuesta a incidentes de la organización.
- Nivel 4: utilice el conocimiento de las tácticas, técnicas y procedimientos del atacante (TPT) para refinar la planificación y ejecución de la respuesta a incidentes. Establezca un centro de operaciones de seguridad (SOC) que facilite una capacidad de respuesta 24/7.
- Nivel 5 – Utilizar técnicas informatizadas aceptadas y sistemáticas de recopilación de datos forenses, incluido el manejo y almacenamiento seguros de datos forenses. Desarrollar y utilizar respuestas manuales y automatizadas en tiempo real a posibles incidentes que sigan patrones conocidos.

28.4.4. Ciclo útil de la respuesta ante los incidentes de NIST
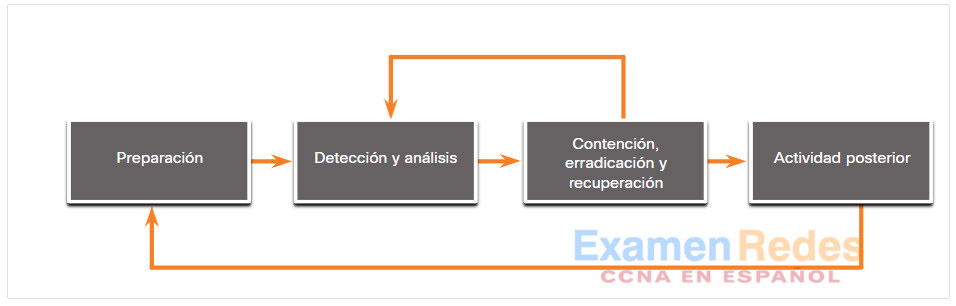
NIST define cuatro pasos en el ciclo de vida del proceso de respuesta ante los incidentes, como se ve en la figura.
- Preparación – Los miembros del CSIRT reciben capacitación sobre cómo responder ante un incidente. Los miembros del CSIRT deben desarrollar continuamente el conocimiento de las amenazas emergentes.
- Detección y análisis – Mediante el monitoreo continuo, el CSIRT identifica, analiza y valida rápidamente un incidente.
- Contención, erradicación y recuperación – El CSIRT implementa procedimientos para contener la amenaza, erradicar el impacto en los activos de la organización y utilizar copias de respaldo para restaurar datos y software. Es posible que, durante esta fase, se regrese a la detección y el análisis para obtener más información o para ampliar el alcance de la investigación.
- Actividades posteriores al incidente – Luego, el CSIRT documenta cómo se manejó el incidente, recomienda cambios para respuestas futuras y especifica cómo evitar que vuelva a suceder.
El ciclo de vida de respuesta ante los incidentes pretende ser un proceso de aprendizaje reafirmante en el que cada incidente alimente el proceso para el manejo de futuros incidentes. Cada una de estas fases se analiza más detalladamente en este tema.
Ciclo de vida de la respuesta ante incidentes
28.4.5. Preparación
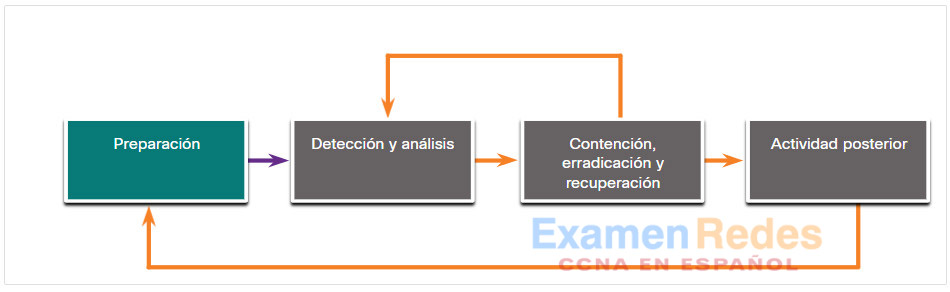
La fase de preparación tiene lugar cuando se crea el CSIRT y se lo capacita. Esta fase ocurre cuando se adquieren e implementan las herramientas y los activos que serán necesarios para que el equipo investigue los incidentes. La siguiente lista tiene ejemplos de acciones que también tienen lugar durante la fase de preparación:
- Los procesos organizativos se crean para abordar la comunicación entre las personas y el equipo de respuesta. Esto incluye elementos como la información de contacto para las partes interesadas, otros CSIRT y la autoridad encargada del orden público, un sistema de seguimiento de problemas, smartphones, software de cifrado, etc.
- Se crean instalaciones para alojar al equipo de respuesta y al SOC.
- Se adquiere el hardware y software necesario para el análisis de incidentes y la mitigación. Esto puede incluir software de informática forense, computadoras de repuesto, servidores y dispositivos de red, dispositivos de respaldo, analizadores de paquetes y analizadores de protocolos.
- Las evaluaciones de riesgos se utilizan para implementar controles que limitarán la cantidad de incidentes.
- La validación de la implementación de hardware y software de seguridad se realiza en dispositivos de usuarios finales, servidores y dispositivos de red.
- Se desarrollan materiales de capacitación para usuarios con el fin de concientizarlos sobre la seguridad.
Es posible que hagan falta recursos de análisis de incidentes adicionales. Ejemplos de estos recursos son una lista de activos críticos, diagramas de red, listas de puertos, hash de archivos esenciales y lecturas de los valores de referencia de la actividad de la red y el sistema. El software de mitigación también es un elemento importante al prepararse para manejar un incidente de seguridad. Es posible que se necesite una imagen de un sistema operativo limpio y archivos de instalación de aplicaciones para recuperar una computadora de un incidente.
A menudo, el CSIRT suele tener preparado un kit de emergencia. Se trata de una caja portátil con muchos de los elementos mencionados antes para ayudar a establecer una respuesta rápida. Algunos de estos elementos pueden ser una computadora portátil con el software apropiado instalado, medios de respaldo, y cualquier otro hardware, software o información para ayudar en la investigación. Es importante inspeccionar el kit de emergencia periódicamente para instalar actualizaciones y asegurarse de que todos los elementos necesarios están disponibles y listos para usar. También resulta útil implementar el kit de emergencia con el CSIRT para asegurarse de que los miembros del equipo sepan cómo utilizar correctamente el contenido.
Fase de preparación
28.4.6. Detección y análisis
Fase de detección y análisis
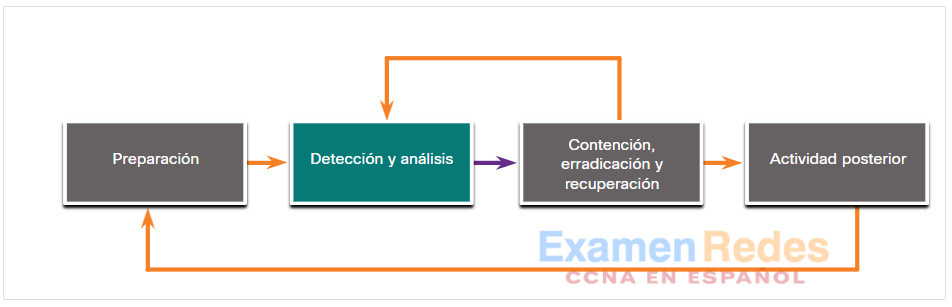
Dado que hay muchas maneras diferentes en las que puede ocurrir un incidente de seguridad, es imposible crear instrucciones que abarquen completamente cada paso para manejarlos. Los distintos tipos de incidentes requieren respuestas diferentes.
- Vectores de ataque
- Detección
- Análisis
- Definición del alcance
- Notificación de incidentes
- Web – Cualquier ataque que se inicia desde un sitio web o una aplicación alojada en un sitio web.
- Correo electrónico – Cualquier ataque que se inicia desde un correo electrónico o archivo adjunto de correo electrónico.
- Pérdida o robo – Cualquier equipo que use la organización, como una computadora portátil o de escritorio, o un smartphone, pueden proporcionar la información necesaria para que alguien inicie un ataque.
- Suplantación – Cuando se sustituye a alguien o algo con intenciones maliciosas.
- Desgaste – Cualquier ataque que utiliza la fuerza bruta para atacar dispositivos, redes o servicios.
- Medios – Cualquier ataque que se inicie con medios de almacenamiento externos o extraíbles.
Es importante determinar con precisión el tipo de incidente y la magnitud de sus efectos. Las señales que indican un incidente se clasifican en dos categorías:
- Precursor – Es una señal que indica que un incidente podría ocurrir en el futuro. Cuando se detectan los precursores, un ataque puede evitarse modificando las medidas de seguridad para abordar específicamente el tipo de ataque detectado. Ejemplos de precursores son las entradas del registro que muestran una respuesta a un análisis de puertos, o una vulnerabilidad recién descubierta en el servidor de web de la organización.
- Indicador – Es una señal que indica que un incidente podría haber ocurrido o está ocurriendo actualmente. Algunos ejemplos de indicadores son un host que se infectó con malware, varios inicios de sesión incorrectos de origen desconocido, o una alerta de IDS.
Cuando un indicador de cambio es exacto, no significa necesariamente que se haya producido un incidente de seguridad. Algunos indicadores tienen lugar por otros motivos además de la seguridad. Por ejemplo, un servidor que deja de funcionar continuamente puede tener una memoria RAM deficiente en lugar de estar sufriendo un ataque de desbordamiento del búfer. Para estar seguros, incluso los síntomas ambiguos o contradictorios deben analizarse para determinar si ha ocurrido un incidente de seguridad real. El CSIRT debe reaccionar rápidamente para validar y analizar los incidentes. Esto se realiza siguiendo un proceso predefinido y documentando cada paso.
- Director general (CIO)
- Director de seguridad informática
- Director local de seguridad informática
- Otros equipos de respuesta ante los incidentes dentro de la organización
- Equipos externos de respuesta ante los incidentes (si corresponde)
- Propietario del sistema
- Recursos Humanos (para casos que involucran a empleados, como el acoso por correo electrónico)
- Relaciones públicas (para los incidentes que pueden generar publicidad)
- Departamento de asuntos legales (para los incidentes que podría tener ramificaciones legales)
- US-CERT (obligatorio en el caso de los organismos federales y los sistemas utilizados en nombre del gobierno federal)
- Autoridad encargada del orden público (si corresponde)
28.4.7. Contención, erradicación y recuperación
Fase de contención, erradicación y recuperación
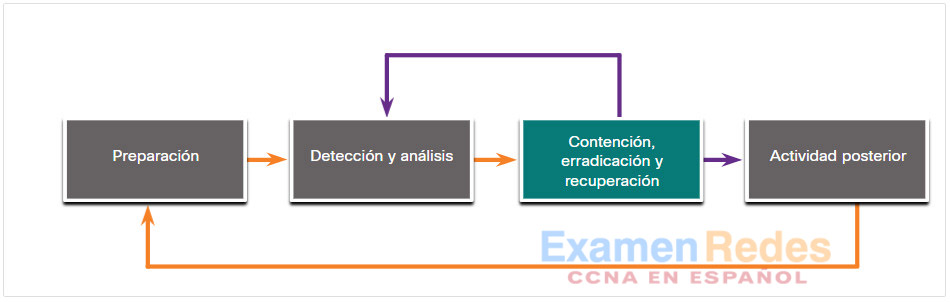
Después de detectar un incidente de seguridad y realizar análisis suficientes para determinar que es válido, se debe contener a fin de decidir qué hacer al respecto. Es necesario definir estrategias y procedimientos para la contención de incidentes antes de que un incidente ocurra e implementarlas antes de que el daño se propague.
- Estrategia de contención
- Evidencia
- Identificación del atacante
- Erradicación, recuperación y corrección
- ¿Cuánto tiempo se demorará en implementar y completar una solución?
- ¿Cuánto tiempo y cuántos recursos se necesitarán para implementar la estrategia?
- ¿Cuál es el proceso para preservar la evidencia?
- ¿Se puede redirigir a un atacante hacia un sandbox para que el CSIRT pueda documentar de manera segura la metodología del atacante?
- ¿Cuál será el impacto en la disponibilidad de los servicios?
- ¿Cuál es la magnitud del daño en los recursos o activos?
- ¿Cuán efectiva es la estrategia?
Durante la contención, se pueden producir más daños. Por ejemplo, no siempre es recomendable desconectar el host atacado de la red. El proceso malicioso podría avisar de esta desconexión al controlador de CnC y desencadenar un borrado de datos o la encriptación del objetivo. Aquí es donde la experiencia y los conocimientos pueden ayudar a contener un incidente que no se contemple en el alcance de la estrategia de contención.
- Ubicación de la recuperación y el almacenamiento de toda la evidencia
- Los criterios de identificación de la evidencia, como el número de serie, la dirección MAC, el nombre de host o la dirección IP
- Información de identificación para todas las personas que participaron en la recopilación o manipulación de la evidencia
- Hora y fecha en que se recopiló la evidencia y cada vez que se manipuló
Es fundamental capacitar a cualquier persona involucrada en el manejo de evidencia sobre cómo protegerla adecuadamente.
- Utilizar bases de datos de incidentes para investigar actividades relacionadas. Esta base de datos puede ser interna o estar ubicada en organizaciones que recogen datos de otras organizaciones y los reúnen en bases de datos de incidentes, como la base de datos de la comunidad de VERIS.
- Validar la dirección IP del atacante para determinar si es viable. El host puede responder a una solicitud de conexión o no hacerlo. Esto puede ocurrir porque el host se configuró para ignorar las solicitudes o porque la dirección ya se reasignó a otro host.
- Utilizar un motor de búsqueda en Internet para obtener más información sobre el ataque. Es posible que otra organización o individuo haya publicado información sobre un ataque desde la dirección IP de origen identificada.
- Monitorear los canales de comunicación que algunos atacantes usan, como IRC. Dado que los usuarios pueden ocultarse en el anonimato en los canales de IRC, es posible que hablen sobre los ataques en estos canales. A menudo, la información recopilada gracias a este tipo de monitoreo es engañosa y debe tratarse como indicios, no hechos.
Para recuperar los hosts, deben usarse copias de respaldo limpias y recientes, o se deben reconstruir los hosts con medios de instalación si no hay copias de seguridad disponibles o también se vieron afectadas. También, deben implementarse completamente actualizaciones y parches en los sistemas operativos y el software instalado en todos los hosts. Deben modificarse todas las contraseñas de hosts y contraseñas de sistemas esenciales según la política de seguridad de las contraseñas. Este puede ser un buen momento para validar y actualizar la seguridad de la red, las estrategias de respaldo y las políticas de seguridad. Los atacantes suelen repetir los ataques en los sistemas o utilizan un ataque similar dirigido a recursos adicionales; por lo tanto, es necesario prevenir esto lo mejor posible. Hace falta concentrarse en lo que pueda repararse rápidamente y dar prioridad a las operaciones y los sistemas esenciales.
28.4.8. Actividades posteriores al incidente
Fase de actividad posincidente
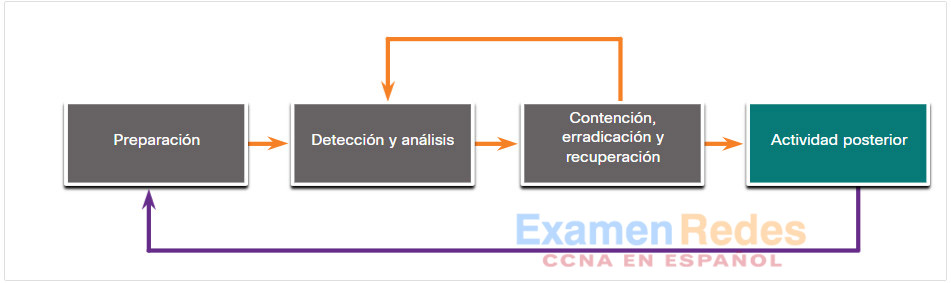
Después de que las actividades de respuesta ante los incidentes erradican las amenazas y la organización comienza a recuperarse de los efectos del ataque, es importante mirar hacia atrás y reunirse periódicamente con todas las personas involucradas para analizar los acontecimientos que tuvieron lugar y las acciones de todos los individuos durante el manejo del incidente. Esto proporcionará una plataforma para aprender qué se hizo bien, qué se hizo mal, qué se podría cambiar y qué se debe mejorar.
Cómo aprovechar las lecciones para fortalecerse
Después de manejar un incidente importante, la organización debe llevar a cabo una reunión de “lección aprendida” para examinar la eficacia del proceso de manejo de incidentes e identificar el fortalecimiento que hace falta en los controles y las prácticas vigentes de seguridad. Algunas buenas preguntas para formularse durante la reunión son las siguientes:
- ¿Exactamente qué pasó y cuándo?
- ¿Con qué eficacia trabajaron el personal y la dirección durante el manejo del incidente?
- ¿Se respetaron los procedimientos documentados? ¿Fueron los adecuados?
- ¿Qué información se necesitó antes?
- ¿Se tomaron medidas o acciones que podrían haber inhibido la recuperación?
- ¿Qué harían de manera diferente el personal y la dirección la próxima vez que ocurra un incidente similar?
- ¿Cómo se podría mejorar el intercambio de información con otras organizaciones?
- ¿Qué medidas correctivas pueden evitar incidentes similares en el futuro?
- ¿Qué precursores o indicadores deben tenerse en cuenta para detectar incidentes similares en el futuro?
- ¿Qué otras herramientas o recursos se necesitan para detectar, analizar y mitigar incidentes futuros?
28.4.9. Recopilación de datos y retención de incidentes
Gracias a las reuniones de “lecciones aprendidas”, los datos recopilados pueden utilizarse para determinar el costo de un incidente por razones presupuestarias, así como determinar la eficacia del CSIRT e identificar las posibles debilidades de seguridad en todo el sistema. Los datos recopilados deben ser procesables. Solo deben recopilarse datos que puedan utilizarse para definir y refinar el proceso de manejo de incidentes.
Una mayor cantidad de incidentes manejados puede demostrar que algo en la metodología de respuesta ante los incidentes no está funcionando correctamente y debería mejorarse. También podría demostrar incompetencia de parte del CSIRT. Una menor cantidad de incidentes puede demostrar que la seguridad de red y hosts ha mejorado. También podría demostrar una falta de detección de incidentes. Los recuentos individuales de cada tipo de incidente pueden resultar efectivos para mostrar las fortalezas y debilidades del CSIRT y de las medidas de seguridad implementadas. Estas subcategorías pueden ayudar a definir dónde residen las debilidades, en lugar de indicar solamente que existen.
El tiempo de cada incidente proporciona información sobre la cantidad total de mano de obra utilizada y el tiempo total que tomó cada fase del proceso de respuesta ante los incidentes. El tiempo que demoró la primera respuesta también es importante, así como cuánto tardó la notificación del incidente y su derivación fuera de la organización si fuera necesario.
Es importante realizar una evaluación objetiva de cada incidente. La respuesta ante un incidente resuelto puede analizarse para determinar su eficacia. La publicación especial 800-61 de NIST proporciona los siguientes ejemplos de actividades que se realizan duarante la evaluación objetiva de un incidente:
- Revisar los registros, formularios, informes y otra documentación del incidente para ver si se respetan las políticas y los procedimientos de respuesta ante los incidentes.
- Identificar qué precursores e indicadores del incidente se registraron para determinar la eficacia del registro y la identificación del incidente.
- Determinar si el incidente causó daños antes de detectarlo.
- Determinar si se identificó la causa real del incidente e identificar el vector de ataque, las vulnerabilidades aprovechadas y las características de los sistemas, las redes y las aplicaciones que sufrieron el ataque.
- Determinar si el incidente ya ocurrió antes.
- Calcular el daño monetario aproximado del incidente (por ejemplo, información y procesos empresariales esenciales afectados por el incidente).
- Medir la diferencia entre la evaluación inicial del impacto inicial y la evaluación final del impacto.
- Identificar qué medidas podrían haber evitado el incidente (si hubiera).
- Valorar subjetivamente cada incidente exige que los miembros del equipo de respuesta ante los incidentes evalúen su propio desempeño, así como el de otros miembros del equipo y de todo el equipo. Otra valiosa fuente de información es el propietario de un recurso atacado, ya que este puede determinar si cree que el incidente se manejó con eficacia y si el resultado fue satisfactorio.
Cada organización debe tener desarrollada una política que detalle cuánto tiempo debe conservarse la evidencia de un incidente. A menudo, la evidencia se conserva durante muchos meses o años después de que ocurre el incidente. En algunos casos, las normas de cumplimiento pueden exigir el período de retención. Estos son algunos de los factores que determinan la retención de evidencia:
- Acusaciones – Cuando se acusa judicialmente a un atacante por un incidente de seguridad, la evidencia debe conservarse hasta después de finalizar con todas las acciones legales. Esto puede ser durante varios meses o muchos años. En acciones judiciales, no se debe pasar por alto ni subestimar ningún tipo de evidencia. La política de una organización podría indicar que cualquier evidencia relativa a un incidente que haya derivado en acciones legales nunca debe eliminarse ni destruirse.
- Tipo de datos – Una organización puede especificar qué tipos específicos de datos deben mantenerse durante un período determinado. Elementos como correo electrónico o texto deben conservarse solo durante 90 días. Los datos más importantes, como los que se utilizan en la respuesta ante un incidente (que no haya derivado en acciones legales), deben conservarse durante tres años o más.
- Costo – Si hay mucho hardware y muchos medios de almacenamiento que deben almacenarse durante un tiempo prolongado, eso puede ser costoso. Es necesario recordar que, a medida que la tecnología cambia, deben almacenarse también los dispositivos funcionales que sean compatibles con hardware y medios de almacenamiento obsoletos.
28.4.10. Requisitos para la creación de informes y el intercambio de información
El equipo legal debe consultar las regulaciones gubernamentales para determinar con exactitud la responsabilidad de la organización de informar el incidente. Además, los directivos necesitarán determinar qué comunicación adicional es necesaria con otras partes interesadas, como clientes, proveedores, partners, etc.
Más allá de los requisitos legales y las consideraciones sobre las partes interesadas, el NIST recomienda que una organización trabaje en conjunto con otras para compartir información sobre incidentes. Por ejemplo, la organización podría registrar el incidente en la base de datos de la comunidad de VERIS.
Las recomendaciones fundamentales del NIST para el intercambio de información son las siguientes:
- Planificar la coordinación de incidentes con participantes externos antes de que ocurran incidentes.
- Consultar con el departamento legal antes de iniciar cualquier tarea de coordinación.
- Intercambiar información sobre el incidente durante todo el ciclo de vida de respuesta ante los incidentes.
- Intentar automatizar al máximo el proceso de intercambio de información.
- Sopesar los beneficios del intercambio de información con las desventajas de compartir información confidencial.
Compartir con otras organizaciones la mayor cantidad posible de información relevante sobre el incidente.
28.4.12. Práctica de laboratorio: Manejo de incidentes
En esta práctica de laboratorio, se aplicará todo el conocimiento adquirido sobre procedimientos para el manejo de incidentes de seguridad a fin de formular preguntas sobre determinadas situaciones de incidentes.
28.5. Resumen de Análisis y respuesta de incidentes e informática forense digital
28.5.1. ¿Qué aprendimos en este módulo?
Manejo de evidencia y atribución del ataque
La informática forense digital consiste en la recuperación e investigación de la información que se encuentra en dispositivos digitales en relación con actividades delictivas. Los indicadores de compromiso son la evidencia de que se ha producido un incidente de ciberseguridad. Es esencial que se conserven todos los indicadores de compromiso para futuros análisis y atribución de ataques. Una organización necesita desarrollar procesos bien documentados para el análisis forense digital. La publicación especial 800-86 de NIST Guía para la Integración de Técnicas Forenses en Respuesta a Incidentes es un recurso valioso para las organizaciones que requieren orientación en el desarrollo de planes forenses digitales. El proceso forense incluye cuatro pasos: recolección, examen, análisis y presentación de informes. En los procedimientos legales y en términos generales, la evidencia se clasifica como directa o indirecta. La evidencia se clasifica además como mejor evidencia (evidencia que está en su estado original), y evidencia corroborante (evidencia que apoya una afirmación que se desarrolla a partir de la mejor evidencia). IETF RFC 3227 Describe un orden para la recopilación de evidencia digital según la volatilidad de los datos. La cadena de custodia implica la recopilación, el manejo y el almacenamiento seguro de la evidencia.
La atribución de una amenaza hace referencia a la acción de determinar a la persona, organización o nación responsable de una intrusión o ataque exitosos. La identificación de los actores responsables de una amenaza debe darse por medio de la investigación sistemática y fundamentada de la evidencia. En las investigaciones con base en evidencias, el equipo de respuesta ante los incidentes correlaciona las tácticas, las técnicas y los procedimientos (TTP, Tactics, Techniques and Procedures) empleados en el incidente con los de otros ataques conocidos. Las fuentes de inteligencia de amenazas pueden ayudar a relacionar las TTP identificadas por una investigación con fuentes conocidas de ataques similares. Para las amenazas internas, la administración de activos desempeña un papel fundamental. Descubrir los dispositivos desde donde se inició un ataque puede llevar directamente al agente de amenaza. Una forma de atribuir un ataque es modelar el comportamiento del actor de amenazas. El marco de tácticas adversariales, técnicas y conocimiento común (ATT&CK) de MITRE permite detectar tácticas, técnicas y procedimientos del atacante como parte de la defensa de amenazas y la atribución de ataques.
La Cadena de eliminación cibernética
La cadena de ciber eliminación (Cyber Kill Chain) fue desarrollada para identificar y evitar ciber intrusiones. Hay siete pasos a la cadena de eliminación cibernética. Enfocarse en estos pasos ayuda a los analistas a entender las técnicas, herramientas y procedimientos de los atacantes. Al responder a un incidente de seguridad, el objetivo es detectar y detener el ataque lo antes posible en el transcurso de la cadena de eliminación. Cuanto antes se detenga el ataque, menor será el daño y menor será la información que el atacante obtenga acerca de la red atacada.
Los pasos de la cadena de ciber eliminación (Cyber Kill Chain) son reconocimiento, armamento, entrega, explotación, instalación, comando y control, y acciones sobre objetivos. El reconocimiento tiene lugar cuando el agente de amenaza realiza una búsqueda, reúne inteligencia y selecciona objetivos. Esto le permite determinar al agente si vale la pena realizar el ataque. El objetivo de armamento es utilizar la información de reconocimiento para desarrollar un arma contra sistemas o individuos que sean blancos específicos en la organización. Durante la entrega, el arma es transmitida a los objetivos utilizando un vector de entrega. Una vez aplicada el arma, el actor de la amenaza la utiliza para quebrar la vulnerabilidad y obtener el control del objetivo. La instalación ocurre cuando el atacante establece una puerta trasera al sistema para poder seguir accediendo al objetivo. Para preservar esta puerta trasera, es importante que el acceso remoto no alerte a los analistas de ciberseguridad ni a los usuarios. Comando y Control, o CnC, establece el control del atacante sobre el objetivo del sistema. El agente de amenaza utiliza los canales de CnC para emitir comandos al software que instala en el objetivo. Acciones sobre objetivos describe el agente amenazador que logra su objetivo original. Este puede ser el robo de datos, la ejecución de un ataque de DDoS, o el uso de la red atacada para crear y enviar correo electrónico no deseado o mina de Bitcoin.
Análisis del modelo de diamante de las intrusiones
El modelo de diamante de análisis de intrusiones representa un incidente o un evento de seguridad. Un evento es una actividad de tiempo limitado que está restringido a un paso específico donde el adversario utiliza la capacidad sobre la infraestructura para atacar una víctima para lograr un resultado específico. Las cuatro características principales de un evento de intrusión son el adversario (las partes responsables de la intrusión), la capacidad (la herramienta o técnica utilizada para atacar a la víctima), la infraestructura (la ruta de red o rutas utilizadas para establecer y mantener CNC) y la víctima (el objetivo del ataque). Las metacaracterísticas, que amplían ligeramente el modelo, incluyen Marca de tiempo, Fase, Resultado, Dirección, Metodología y Recursos (uno o más recursos externos utilizados por el adversario para el evento de intrusión).
Como analistas especializados en ciberseguridad, es posible que se les pida que utilicen el Modelo de diamante de análisis de intrusión para diagramar una serie de eventos de intrusión. Los adversarios no ejecutan un solo evento. En cambio, los eventos se entretejen en una cadena en la que cada evento debe completarse con éxito antes del siguiente. Esta serie de eventos puede asignarse a la cadena de ciber eliminación.
Respuesta ante los incidentes
La respuesta a incidentes implica los métodos, políticas y procedimientos que utiliza una organización para responder a un ataque cibernético. Los objetivos de la respuesta ante incidentes son limitar el impacto del ataque, evaluar los daños causados e implementar procedimientos de recuperación. Es esencial que las organizaciones creen y mantengan planes detallados de respuesta a incidentes y designen al personal responsable de ejecutar todos los aspectos de ese plan. Las recomendaciones del NIST (U.S. National Institute of Standards and Technology ) para la respuesta ante los incidentes se detallan en su Publicación especial 800-61 (Revisión 2) titulada “Guía de manejo de incidentes de seguridad informática”
El primer paso para una organización es establecer una capacidad de respuesta ante los incidentes de seguridad informática (CSIRC, computer security incident response capability). NIST recomienda crear políticas (detallando cómo se manejan los incidentes), planes (definiendo claramente las tareas y responsabilidades) y procedimientos (acciones específicas a tomar) para establecer y mantener un CSIRC. Otros grupos e individuos dentro de la organización también pueden estar involucrados en el manejo de incidentes. Sus conocimientos y habilidades pueden ayudar al CSIRT (Computer Security Incident Response Team) a manejar el incidente rápida y correctamente. Algunas de las partes interesadas incluyen administración, aseguramiento de la información, soporte de TI, el departamento legal, asuntos públicos y relaciones con los medios, recursos humanos, planificadores de continuidad comercial, seguridad física y administración de instalaciones. El equipo legal debe consultar las regulaciones gubernamentales para determinar la responsabilidad de la organización de informar el incidente. Más allá de los requisitos legales y las consideraciones sobre las partes interesadas, el NIST recomienda que una organización trabaje en conjunto con otras para compartir información sobre incidentes. Cada organización debe tener desarrollada una política que detalle cuánto tiempo debe conservarse la evidencia de un incidente.
El marco de certificación del modelo de madurez de ciberseguridad (CMMC) fue creado para evaluar la capacidad de las organizaciones que desempeñan funciones para el Departamento de Defensa de los Estados Unidos (DoD) para proteger la cadena de suministro militar de interrupciones o pérdidas debidas a incidentes de ciberseguridad. El CMMC especifica 17 dominios, cada uno de los cuales tiene un número variable de capacidades asociadas a él. La organización se califica por el nivel de madurez que se ha alcanzado para cada uno de los dominios. La CMMC certifica las organizaciones por nivel.
La NIST define cuatro pasos en respuesta a incidentes en un proceso de ciclo de vida: preparación, detección y análiis, contención, erradicación, recuperación, y actividades post incidente. El ciclo de vida de respuesta ante los incidentes pretende ser un proceso de aprendizaje reafirmante en el que cada incidente alimente el proceso para el manejo de futuros incidentes. La fase de preparación tiene lugar cuando se crea el CSIRT y se lo capacita. Esta fase ocurre cuando se adquieren e implementan las herramientas y los activos que serán necesarios para que el equipo investigue los incidentes. Los incidentes se detectan con muchos métodos diferentes y no todos son muy detallados ni claros. Hay dos categorías para los signos de un incidente: Precursor (un incidente puede ocurrir en el futuro) e Indicador (un incidente ha ocurrido o está sucediendo). El uso de algoritmos complejos y aprendizaje mecanizado ayuda, en ocasiones, a determinar la validez de los incidentes de seguridad. Un método que puede utilizarse es la creación de perfiles de la red y el sistema.
Cuando el CSIRT cree que se ha producido un incidente, debe realizar inmediatamente un análisis inicial para determinar el alcance de los hechos, por ejemplo, qué redes, sistemas o aplicaciones se vieron afectados, qué o quién originó el incidente y cómo está ocurriendo. Cuando se analiza y prioriza un incidente, el equipo de respuesta ante los incidentes debe notificar a las personas interesadas y partes externas para que todos los que necesitan involucrarse desempeñen sus funciones. Es fundamental disponer de documentación clara y concisa relativa a la preservación de la evidencia. La identificación de los atacantes no es tan importante como contener y erradicar el ataque, y recuperar los hosts y servicios. Después de la contención, el primer paso para la erradicación consiste en identificar todos los hosts que necesitan correcciones. Se deben eliminar todos los efectos del incidente de seguridad. También se deben aplicar correcciones o parches en todas las vulnerabilidades que el atacante aprovechó, de modo que el incidente no se repita. Después de manejar un incidente importante, la organización debe llevar a cabo una reunión de “lección aprendida” para examinar la eficacia del proceso de manejo de incidentes e identificar el fortalecimiento que hace falta en los controles y las prácticas vigentes de seguridad.