Última actualización: abril 1, 2022
27.0. Introducción
27.0.1. ¿Por qué deberíamos tomar este módulo?
Hay muchos tipos diferentes de datos que se utilizan en la supervisión de seguridad de red. Se requieren herramientas especializadas para procesar, buscar e investigar estos datos. En este módulo, aprenderá acerca de los datos de seguridad de red y algunas de las herramientas que se utilizan para investigarlos.
27.0.2. ¿Qué aprenderemos en este módulo?
Título del módulo: Trabajo con datos de seguridad de la red
Objetivo de módulo: Interprete los datos para determinar el origen de una alerta.
| Objetivo | Objetivo del tema |
|---|---|
| Una plataforma común para los datos | Explicar cómo se preparan los datos para su uso en un sistema de monitoreo de seguridad de la red (Network Security Monitoring NSM). |
| Investigación de datos de la red | Utilizar las herramientas de la Security Onion para investigar eventos de seguridad de la red. |
| Cómo mejorar el trabajo del analista de ciberseguridad | Describa las herramientas de monitoreo de red que mejoran la administración del flujo de trabajo. |
27.1. Una plataforma común para los datos
27.1.1. ELK
Una red típica tiene una multitud de registros diferentes para realizar un seguimiento y la mayoría de esos registros están en diferentes formatos. Con enormes cantidades de datos dispares, ¿cómo es posible obtener una visión general de las operaciones de red al tiempo que se perciben anomalías sutiles o cambios en la red?
Elastic Stack intenta resolver este problema proporcionando una vista de interfaz única en una red heterogénea. Elastic Stack consta de Elasticsearch, Logstash y Kibana (ELK). Es un marco modular y altamente escalable para ingerir, analizar, almacenar y visualizar datos. Elasticsearch es una plataforma de núcleo abierto (código abierto en los componentes principales) para buscar y analizar los datos de una organización en tiempo casi real. Se puede utilizar en muchos contextos diferentes, pero ha ganado popularidad en seguridad de red como herramienta SIEM. Security Onion incluye ELK y otros componentes de Elastic, incluidos:
- Beats — Esta es una serie de complementos de software que envían diferentes tipos de datos a los almacenes de datos de Elasticsearch.
- ElastAlert ─ Proporciona consultas y alertas de seguridad basadas en criterios definidos por el usuario y otra información de los datos de Elasticsearch. Las notificaciones de alerta se pueden enviar a una consola o correo electrónico y a otros sistemas de notificación, como la plataforma de respuesta a incidentes de seguridad de Hive.
- Curator – Proporciona acciones para administrar los índices de datos de Elasticsearch.
Elasticsearch, que es el componente del motor de búsqueda, utiliza servicios web RESTful y API, un clúster de computación distribuido con varios nodos de servidor y una base de datos NoSQL distribuida formada por documentos JSON. Se pueden agregar funciones adicionales a través de extensiones creadas a medida. La empresa Elasticsearch ofrece una extensión comercial llamada X-Pack que añade seguridad, alertas, monitoreo, informes y gráficos. La compañía también ofrece un complemento de aprendizaje automático, así como su propio producto Elastic SIEM.
Logstash permite la recopilación y normalización de datos de red en índices de datos que Elasticsearch puede buscar eficientemente. Los módulos Logstash y Beats se utilizan para ingerir datos en el clúster de Elasticsearch.
Kibana proporciona una interfaz gráfica a los datos compila dos por Elasticsearch. Permite la visualización de datos de red y proporciona herramientas y accesos directos para consultar esos datos con el fin de aislar posibles violaciones de seguridad.
Los principales componentes de código abierto de Elastic Stack son Logstash, Beats, Elasticsearch y Kibana, como se muestra en la figura.
Componentes de núcleo elástico de pila
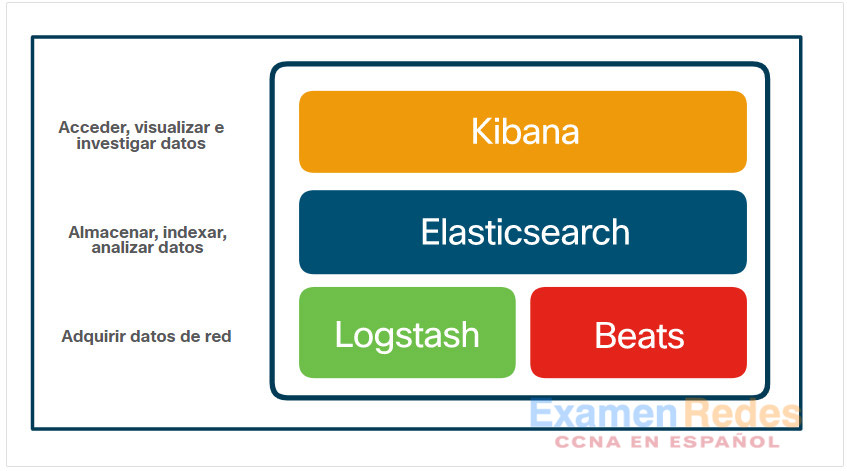
Logstash
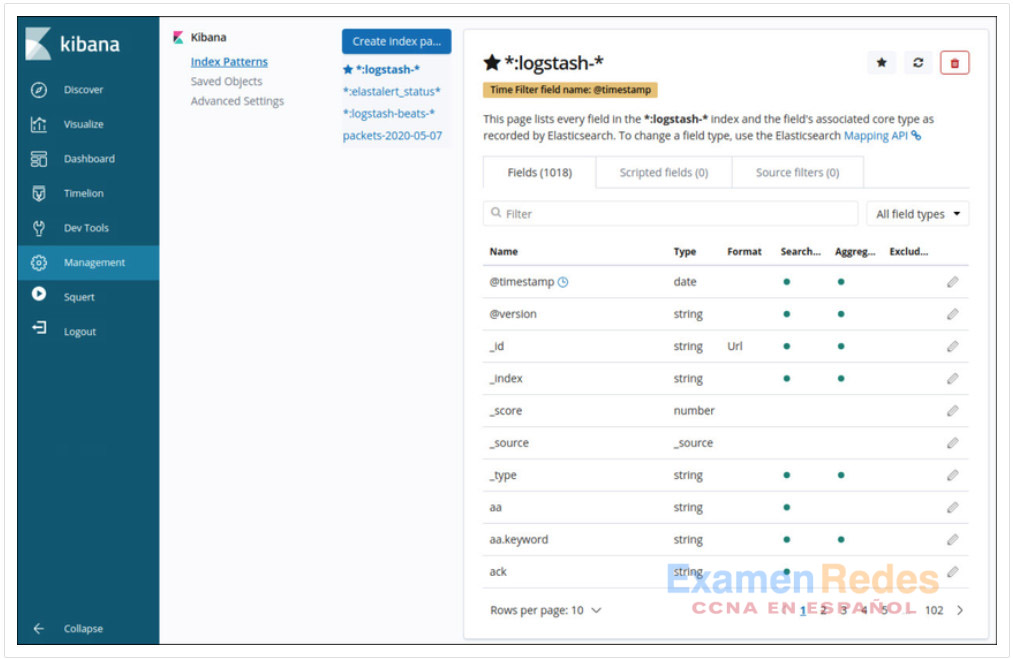
Logstash es un sistema de extracción, transformación y carga con la capacidad de tomar varias fuentes de datos de registro y transformar o analizar los datos a través de la traducción, clasificación, agregación, división y validación. Después de transformar los datos, los datos se cargan en la base de datos de Elasticsearch en el formato de archivo adecuado. La figura muestra algunos de los campos que están disponibles en Logstash como se muestra en la interfaz de administración de Kibana.
Marco de administración de Kibana que muestra detalles del índice Logstash
Beats
Los agentes de Beats son clientes de software de código abierto que se utilizan para enviar datos operativos directamente a Elasticsearch o a través de Logstash. Elastic, así como la comunidad de código abierto, desarrollan activamente agentes de Beats, por lo que hay una gran variedad de agentes de Beats para enviar datos a Elasticsearch casi en tiempo real. Algunos de los agentes Beats proporcionados por Elastic son Auditbeat para datos de auditoría, Metricbeat para datos de métrica, Heartbeat para disponibilidad, Packetbeat para tráfico de red, Journalbeat para diarios Systemd y registros de eventos de Winlogbeat para Windows. Algunos Beats de origen comunitario son Amazonbeat, Apachebeat, Dockbeat, Nginxbeat y Mqttbeat, por nombrar algunos.
Elasticsearch
Elasticsearch es un motor de búsqueda empresarial multiplataforma escrito en Java. Los componentes principales son de código abierto con complementos comerciales llamados X-packs que dan funcionalidad adicional. Elasticsearch admite búsquedas casi en tiempo real utilizando API REST simples para crear o actualizar documentos JavaScript Object Notation (JSON) mediante solicitudes HTTP. Las búsquedas se pueden realizar utilizando cualquier programa capaz de realizar solicitudes HTTP como un navegador web, Postman, cURL, etc. Estas API también pueden ser accedidas por Python u otros scripts de lenguaje de programación para operaciones automatizadas.
La estructura de datos de Elasticsearch se denomina índice invertido, que está diseñado para permitir búsquedas de texto completo muy rápidas. Un índice es como una base de datos, es un espacio de nombres para una colección de documentos que están relacionados entre sí. Un índice puede particionarse o asignarse en diferentes tipos. Si compara un índice de Elasticsearch con una base de datos relacional tradicional, el índice es similar a la base de datos, los tipos son como las tablas y los documentos son como las columnas y filas, como se muestra en la tabla.
| Componente MySQL: | base de datos | tablas | columnas/filas |
| Componente de Elasticsearch: | index | tipos | documentos |
Elasticsearch almacena datos en documentos con formato JSON. Un documento JSON se organiza en jerarquías de pares clave/valor, con una clave que es un nombre y el valor correspondiente es una cadena, número, booleano, fecha, matriz u otro tipo de datos.
Kibana
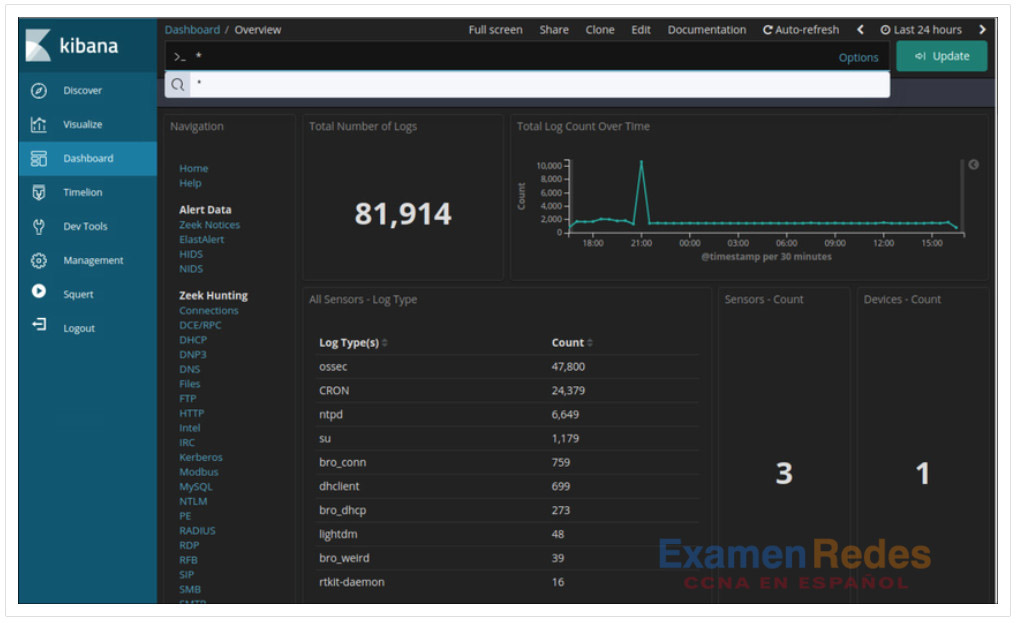
Kibana proporciona una interfaz gráfica de usuario fácil de usar para administrar Elasticsearch. Mediante el uso de un navegador web, un analista puede utilizar la interfaz de Kibana para buscar y ver índices. La pestaña de administración le permite crear y administrar índices y sus tipos y formatos. La pestaña de descubrimiento es una forma rápida y potente de ver sus datos y buscarlos utilizando las herramientas de búsqueda. La pestaña visualizar le permite crear visualizaciones personalizadas como gráficos de barras, gráficos de líneas, gráficos circulares, mapas térmicos y mucho más. Las visualizaciones que cree se pueden organizar en paneles personalizados para supervisar y analizar sus datos. En la figura se muestra un tablero de Kibana.
Un tablero de Kibana
27.1.2. Reducción de datos
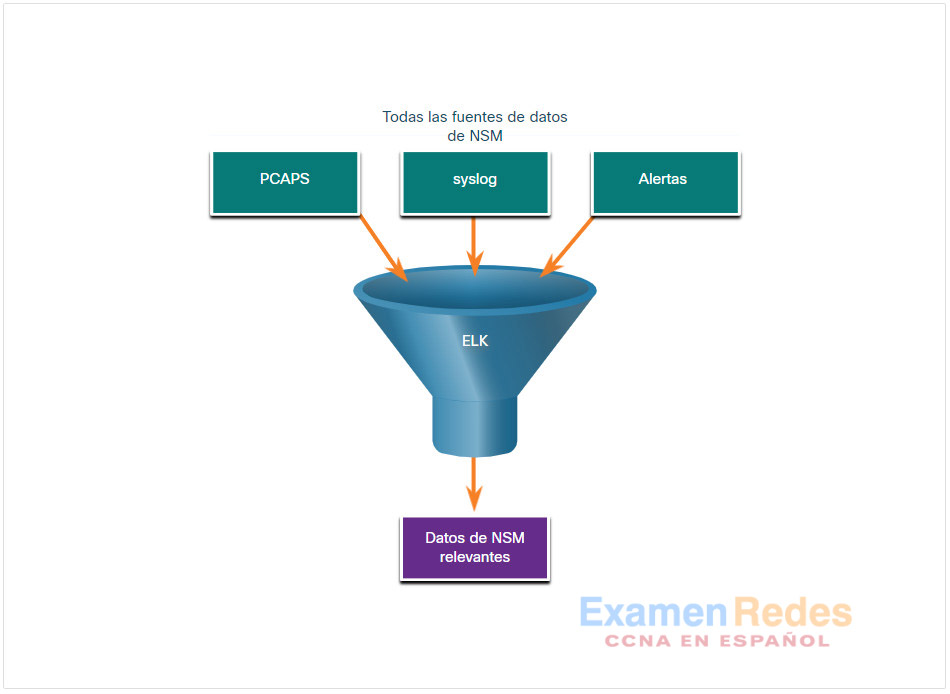
Es impresionante el volumen de tráfico de red que recopila la captura de paquetes y la cantidad de entradas del archivo de registro y alertas que generan los dispositivos de red y de seguridad. Incluso con los avances recientes en datos masivos, el procesamiento, almacenamiento, acceso y archivado de datos relacionados con el NSM es una tarea abrumadora. Por esta razón, es importante identificar los datos de red que deben recopilarse. No es necesario recopilar cada entrada, paquete y alerta del archivo de registro. Si se limita el volumen de datos, herramientas como Elasticsearch son mucho más útiles, como se ve en la figura.
Hay tráfico de la red que tiene poco valor para el NSM. Los datos encriptados, como el tráfico de IPsec o SSL, son prácticamente ilegibles. También es posible excluir más tráfico, como el tráfico de rutina que producen los protocolos de routing. Otros protocolos de difusión y multidifusión generalmente se pueden eliminar de las capturas de paquetes, al igual que el tráfico de otros protocolos que generan mucho tráfico de rutina.
Además, las alertas que genera un HIDS, como la auditoría de seguridad de Windows u OSSEC, deben evaluarse para determinar su relevancia. Algunas son informativas o tienen poco impacto potencial para la seguridad. Estos mensajes se pueden filtrar de los datos de NSM. Del mismo modo, syslog puede almacenar los mensajes de muy baja gravedad que podrían ignorarse para disminuir la cantidad de datos de NSM que se deben manejar.
27.1.3. Normalización de los datos
La normalización de datos es el proceso de combinar datos de varias fuentes en un formato común. Logstash proporciona una serie de transformaciones que procesan datos de seguridad y los transforman antes de agregarlos a Elasticsearch. Es posible crear complementos adicionales que se ajusten a las necesidades de la organización.
Un esquema común especifica los nombres y formatos de los campos de datos requeridos. El formato de los campos de datos puede variar mucho entre las fuentes. Sin embargo, para lograr búsquedas eficaces, deben unificarse los campos de datos. Por ejemplo, es posible representar en formatos diferentes las direcciones IPv6, las direcciones MAC y la información de fecha y hora. Del mismo modo, el formato de las máscaras de subred, los registros de DNS y otros elementos puede variar entre fuentes de datos. Las transformaciones Logstash aceptan los datos en su formato nativo y hacen que los elementos de los datos sean coherentes en todos los orígenes. Por ejemplo, se utilizará un único formato para las direcciones y marcas de hora para los datos de todas las fuentes.
Formatos de direcciones IPv6
- 2001:db8:acad:1111:2222::33
- 2001:DB8:ACAD:1111:2222::33
- 2001:DB8:ACAD:1111:2222:0:0:33
- 2001:DB8:ACAD:1111:2222:0000:0000:0033
Formatos de MAC
- A7:03:DB:7C:91:AA
- A7-03-DB-7C-91-AA
- A70.3DB.7C9.1AA
Formatos de fecha
- Monday, July 24, 2017 7:39:35pm
- Mon, 24 Jul 2017 19:39:35 +0000
- 2017-07-24T19:39:35+00:00
- 1500925254
La normalización de datos es necesaria para simplificar la búsqueda de eventos correlacionados. Si existieran valores con diferente formato en los datos de NSM para las direcciones IPv6, por ejemplo, sería necesario crear un término de consulta por separado para cada variación a fin de que la consulta devuelva eventos correlacionados.
27.1.4. Archivado de datos
A todo el mundo le encantaría poder recopilar y guardar todo por si acaso. Sin embargo, conservar los datos de NSM por tiempo indefinido no es viable debido a limitaciones de almacenamiento y acceso. Cabe destacar que el período de retención para determinados tipos de información de seguridad puede especificarse en marcos de trabajo para el cumplimiento. Por ejemplo, el Concejo de estándares de seguridad de la industria de tarjetas de pago ( Payment Card Industry Security Standards Council PCI DSS) exige que se retenga durante un año la documentación de auditoría de las actividades de los usuarios relacionadas con la información protegida.
Security Onion cuenta con períodos de retención diferentes datos distintos tipos de datos de NSM. Para pcaps y registros sin formato de Bro, un valor asignado en el securityonion.conf archivo controla el porcentaje de espacio en disco que pueden usar los archivos de registro. De forma predeterminada, este valor se establece en 90%. Para Elasticsearch, la retención de índices de datos es controlada por el curator de Elasticsearch. Curator se ejecuta en un contenedor Docker y se ejecuta cada minuto según los cron trabajos. Curator registra su actividad en curator.log. Curator establece de forma predeterminada los índices de cierre de más de 30 días. Para modificar esto, cambie CURATOR\ _CLOSE\ _DAYS en /etc/nsm/securityonion.conf. A medida que un disco alcanza la capacidad, Curator elimina los índices antiguos para evitar que el disco se llene. Para cambiar el límite, modifique LOG\ _SIZE\ _LIMIT en /etc/nsm/securityonion.conf.
Los datos de alerta de Sguil se retienen durante 30 días de manera predeterminada. Este valor se establece en el securityonion.conf archivo.
Se sabe que Security Onion requiere una gran cantidad de almacenamiento y memoria RAM para funcionar correctamente. De acuerdo con el tamaño de la red, es posible que se necesiten varios terabytes de almacenamiento. Por supuesto, siempre es posible archivar los datos de Security Onion en dispositivos de almacenamiento externo mediante un sistema de archivado de datos, de acuerdo con las necesidades y capacidades de la organización.
Nota: Los lugares de almacenamiento para los diferentes tipos de datos de Security Onion variarán en función de la implementación de Security Onion.
27.1.5. Práctica de laboratorio: Convertir datos a un formato universal
Las entradas de registro son generadas por dispositivos de red, sistemas operativos, aplicaciones y diversos tipos de dispositivos programables. Los archivos que contienen una secuencia temporizada de entradas de registro se denominan archivos de registro. Por naturaleza, los archivos de registro registran eventos que son relevantes a la fuente. La sintaxis y el formato de los datos que se encuentran dentro de los mensajes de registro a menudo son definidos por el desarrollador de la aplicación. Por lo tanto, la terminología utilizada en las entradas de registro a menudo varía según la fuente. Por ejemplo, dependiendo de la fuente, los términos iniciar sesión, conectarse, evento de autenticación y conexión del usuario, pueden aparecer en entradas de registro para describir la autenticación exitosa de un usuario en un servidor.
Es aconsejable tener terminología consistente y uniforme en los archivos de registro generados por diferentes fuentes. Esto es especialmente cierto cuando todos los archivos de registro son recopilados por un punto centralizado. El término normalización se refiere al proceso de convertir partes de un mensaje, en este caso una entrada de registro, a un formato común.
En esta práctica de laboratorio utilizarán herramientas de la línea de comando para normalizar las entradas de registro manualmente. En la parte 2, se normalizará el campo de la marca de hora. En la parte 3, deberá normalizarse el campo IPv6.
27.2. Investigación de datos de la red
27.2.1. Uso de Sguil
El deber principal de un analista especializado en ciberseguridad es verificar las alertas de seguridad. Según la organización, las herramientas utilizadas para hacerlo varían. Por ejemplo, un sistema de tickets puede utilizarse para administrar la asignación y documentación de las tareas. En Security Onion, el primer lugar al que acudirá un analista en ciberseguridad para verificar las alertas es Sguil.
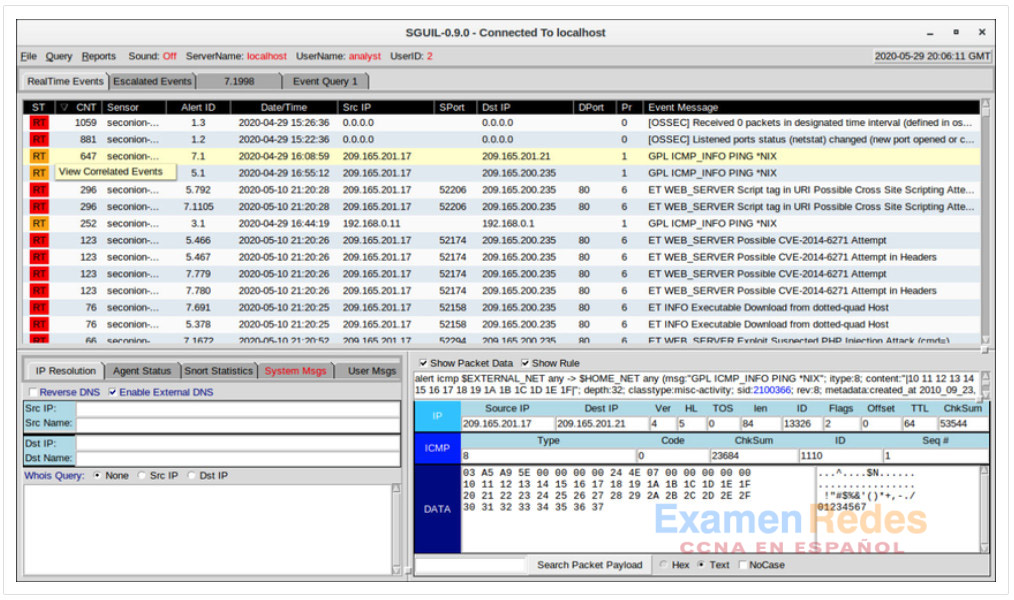
Sguil correlaciona automáticamente alertas similares en una única línea y permite ver eventos correlacionados representados por esa línea. Para tener una idea de lo que ha estado ocurriendo en la red, puede resultar útil ordenar la columna CNT para mostrar las alertas con la frecuencia más alta.
Al hacer clic derecho en el valor CNT y seleccionar Ver eventos correlacionados, se abre una ficha con todos los eventos correlacionados por Sguil. Esto puede ayudar al analista de ciberseguridad a entender el plazo durante el Sguil recibió los eventos correlacionados. Tenga en cuenta que cada evento recibe una identificación única de evento. Solo se muestra el primer ID de evento de la serie de eventos correlacionados en la pestaña Eventos en tiempo real. La figura muestra las alertas de Sguil ordenadas en CNT con el menú Ver eventos correlacionados abierto.
Alertas de Sguil ordenadas en CNT
27.2.2. Consultas de Sguil
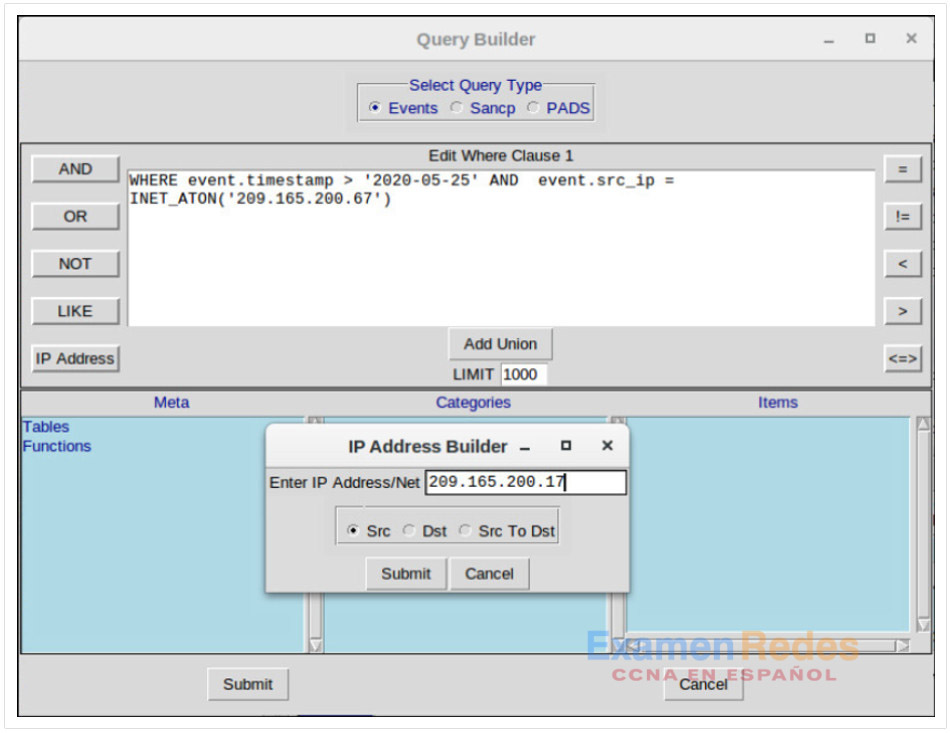
Las consultas pueden crearse en Sguil utilizando Query Builder. Simplifica la construcción de consultas hasta cierto punto, pero el analista de ciberseguridad debe conocer los nombres de los campos y algunos problemas con los valores de los campos. Por ejemplo, Sguil almacena direcciones IP en una representación de números enteros. Para consultar una dirección IP en notación decimal punteada, el valor de la dirección IP debe colocarse dentro de la INET_ATON() función. El Generador de consultas se abre desde el menú Query de Sguil. Se debe seleccionar Query Event Table para buscar eventos activos.
La tabla muestra los nombres de algunos de los campos de la tabla de eventos que se pueden consultar directamente. Al seleccionar Mostrar Tablas de Base de Datos en el menú Consulta se muestra una referencia a los nombres y tipos de campo para cada una de las tablas que se pueden consultar. Cuando realice búsquedas en tablas de eventos, utilice el patrón event.fieldName = value.
| Nombre de campo | Tipo | Descripción |
|---|---|---|
| sid | int | El ID único del sensor |
| cid | int | El número de evento único del sensor ’s |
| firma | varchar | el nombre legible por humanos del evento (por ejemplo, & # x201C; fuente de la vista WEB-IIS a través del encabezado de traducción & # x201D;) |
| marca de tiempo | fecha y hora | La hora y fecha a la que se produjo el evento en el sensor |
| estado | int | La clasificación de Sguil asignada a este evento. Los eventos sin clasificar son de prioridad 0. |
| src_ip | int | la dirección IP de origen para el evento. Utilice la función INET_ATON () para convertir la dirección a la representación entera de la base de datos. |
| dst_ip | int | la dirección IP de destino para el evento. |
| src_port | int | el puerto de origen del paquete que activó el evento |
| dst_port | int | el puerto de destino del paquete que activó el evento |
| ip_proto | inconcluso | El tipo de protocolo IP del paquete (6 = TCP, 17 = UDP, 1 = ICMP, otros son posibles) |
En la figura se ve una consulta sencilla de marca de hora y dirección IP realizada en la ventana de Generador de Consultas. Cabe destacar el uso de la INET_ATON()función para simplificar el ingreso de una dirección IP.
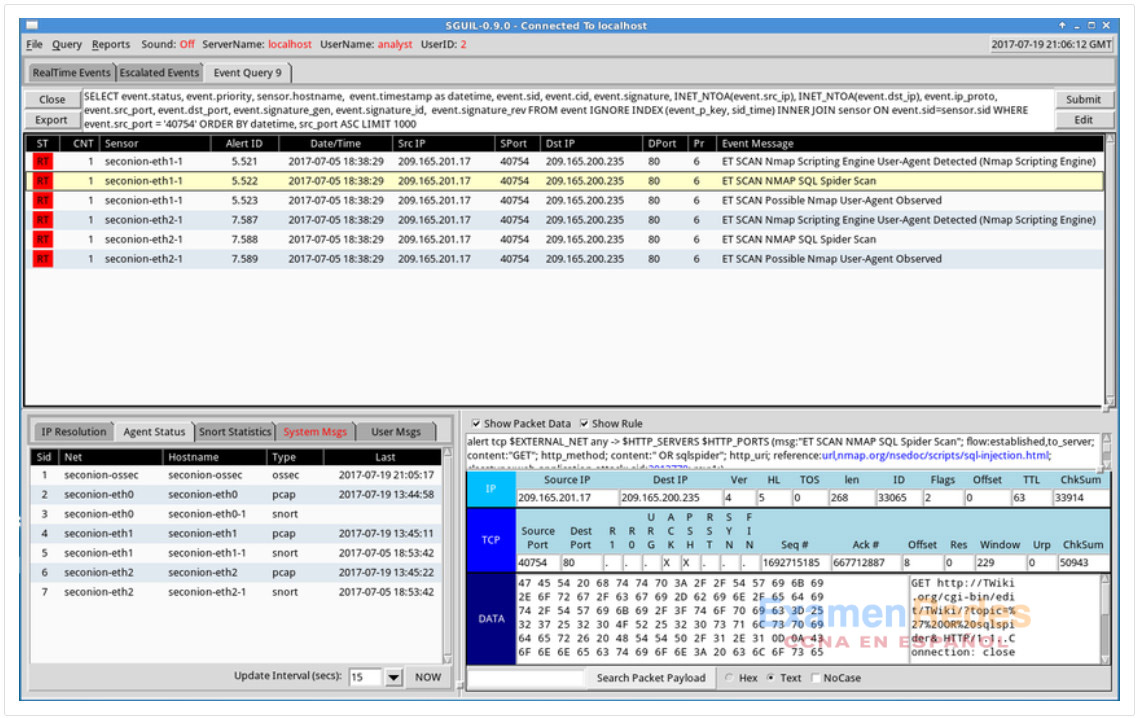
En el siguiente ejemplo, el analista de ciberseguridad está investigando un puerto de origen 40754 asociado a una alerta de amenazas emergentes. Hacia el final de la consulta, la WHERE event.src_port = ‘40754’parte fue creada por el usuario en el Generador de Consultas. Sguil proporciona automáticamente el resto de la consulta y se refiere a cómo se van a recuperar, mostrar y presentar los datos asociados a los eventos.
27.2.3. Alternar a otros programas desde Sguil
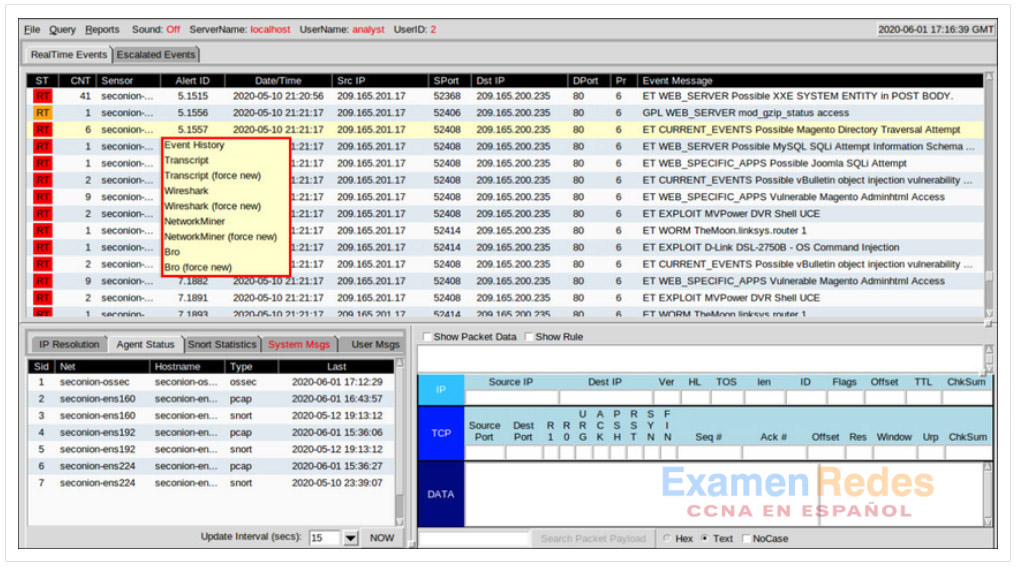
Sguil permite que el analista de ciberseguridad pueda alternar con otras fuentes y herramientas de información. Los archivos de registro están disponibles en Elasticsearch. Las capturas de paquetes relevantes se pueden mostrar en Wireshark. También están disponibles transcripciones de sesiones TCP e información de detección de Zeek (Bro). El menú que se ve en la figura se abrió haciendo clic con el botón secundario del mouse sobre una identificación de alerta. Las selecciones en este menú abren la información acerca de la alerta en otras herramientas, lo que le permite al analista de ciberseguridad ver información completa y contextualizada.
Alternar a otros programas desde Sguil
Además, Sguil puede proporcionar pivotes a la información del Sistema de detección de activos en tiempo real pasivo (Passive-Real-time Asset Detection System PRADS) y del Perfil de conexión de red del analista de seguridad (Security Analyst Network Connection Profiler SANCP). Para acceder a estas herramientas, haga clic derecho en una dirección IP de un evento y seleccione los menús Consulta rápida o Consulta avanzada.
PRADS reúne datos de perfiles de red, incluida información sobre el comportamiento de los activos en la red. PRADS es una fuente de eventos, como Snort y OSSEC. También se puede consultar mediante Sguil cuando una alerta indica que podría estar en riesgo un host interno. Ejecutar una consulta de PRADS fuera de Sguil puede proporcionar información sobre los servicios, las aplicaciones y las cargas útiles que pueden ser relevantes para la alerta. Además, PRADS detecta cuándo aparecen nuevos activos en la red.
Nota: La interfaz de Sguil menciona a PADS en lugar de PRADS. PADS es el precursor de PRADS. PRADS es la herramienta que se utiliza en Security Onion. PRADS también se utiliza para completar tablas de SANCP. En Security Onion, las funcionalidades de SANCP se reemplazaron con PRADS; sin embargo, el término SANCP se sigue usando en la interfaz de Sguil. PRADS recopila los datos y un agente de SANCP registra estos datos en una tabla de datos de SANCP.
Las funcionalidades de SANCP se refieren a la recopilación y el registro de información estadística sobre el tráfico y el comportamiento de la red. SANCP proporciona un método para verificar que las conexiones de red sean válidas. Esto se logra mediante la aplicación de reglas que indican que el tráfico debe registrarse y la información con la que debe etiquetarse el tráfico.
27.2.4. Manejo de eventos en Sguil
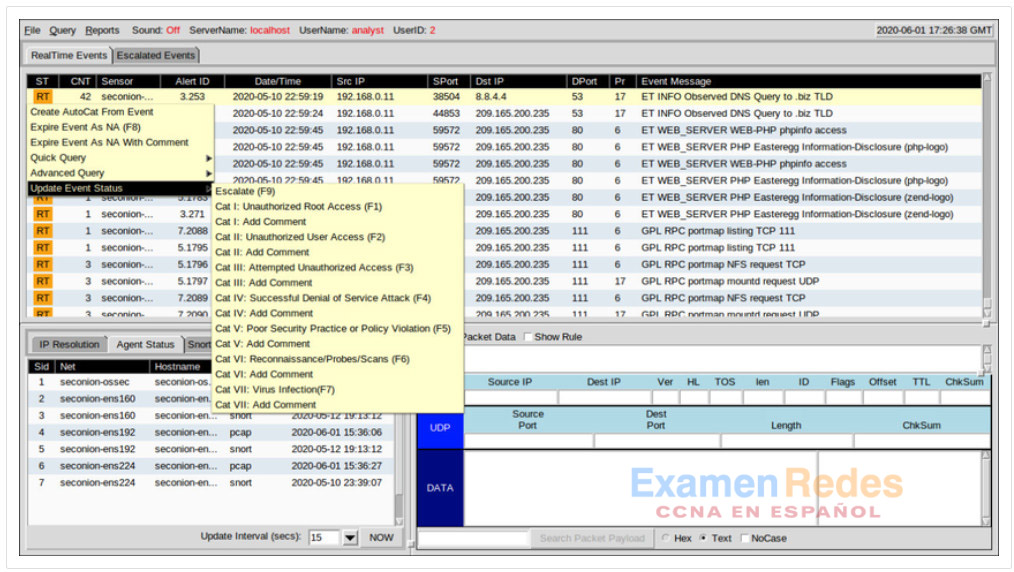
Finalmente, Sguil no es solamente una consola que facilita la investigación de alertas. También es una herramienta para direccionar o abordar las alertas. Es posible realizar tres tareas en Sguil para administrar alertas. En primer lugar, las alertas que se consideren falsos positivos pueden caducar. Esto se puede hacer usando el clic derecho en la columna ST para el evento y usando el menú o presionando la tecla F8. Un evento caducado desaparece de la cola. En segundo lugar, si el analista de ciberseguridad no sabe cómo manejar un evento, puede derivarlo presionando la tecla F9. La alerta se moverá a la ficha de eventos derivados de Sguil. Por último, es posible categorizar un evento. La categorización es para los eventos que se identificaron como positivos verdaderos.
Sguil incluye siete categorías prediseñadas que pueden asignarse usando el menú que se ve en la figura o presionando la tecla de función correspondiente. Por ejemplo, si se presiona la tecla F1, un evento se categoriza como Cat I. Además, se pueden crear criterios que categorizarán automáticamente un evento. Se supone que los eventos categorizados han sido manejados por el analista de ciberseguridad. Cuando se clasifica un evento, se elimina de la lista de Eventos de Tiempo Real. El evento igual permanece en la base de datos y es posible tener acceso a él mediante consultas emitidas por categoría.
Este curso solamente abarca un nivel básico de Sguil. Existen numerosos recursos en Internet para aprender más.
Manejo de eventos en Sguil
27.2.5. Trabajar en ELK
Logstash y Beats se utilizan para la ingestión de datos en Elastic Stack. Proporcionan acceso a una gran cantidad de entradas de archivos de registro. Debido a que el número de registros que se pueden mostrar es tan grande, Kibana, que es la interfaz visual de los registros, está configurado para mostrar las últimas 24 horas de forma predeterminada. Puede ajustar el intervalo de tiempo para ver rangos de datos más amplios o antiguos.
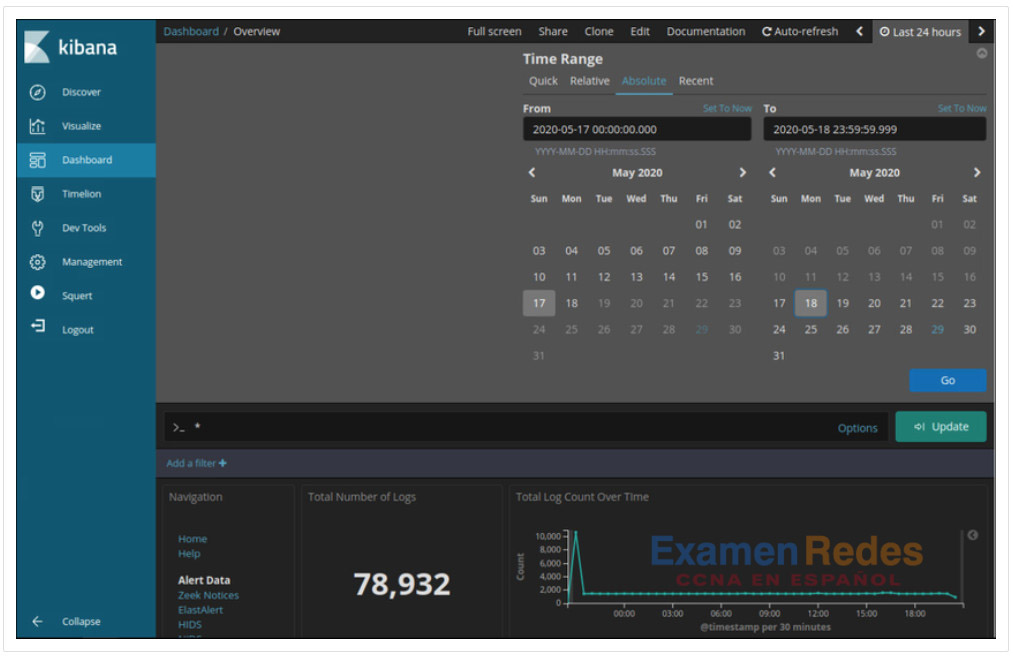
Para ver los registros del archivo de registro durante un período de tiempo diferente, haga clic en la pestaña Últimas 24 horas en la esquina superior derecha de Kibana. A partir de ahí, defina el intervalo de tiempo seleccionando la ficha Rápida para intervalos de tiempo predefinidos. También puede introducir las fechas y horas manualmente mediante la pestaña Absoluto. La figura muestra un intervalo de tiempo absoluto entre el 17 de mayo y el 18 de mayo de 2020. Los registros se introducen en Elasticsearch en índices o bases de datos independientes según un intervalo de tiempo configurado.
La mejor manera de monitorear sus datos en Elasticsearch es crear paneles visuales personalizados que rastreen los datos que le interesan utilizar. Una variedad de gráficos visuales, incluyendo gráficos de barras, gráficos circulares, métricas de recuento, mapas térmicos, mapas geográficos, listas de números principales están disponibles. En Kibana, las visualizaciones y gráficos se pueden buscar y filtrar con métricas y depósitos de datos específicos.
27.2.6. Consultas en ELK
Elasticsearch se basa en Apache Lucene, una biblioteca de software de motor de búsqueda de código abierto que cuenta con capacidades de indexación y búsqueda de texto completo. Elasticsearch introduce datos en documentos denominados índices y esos documentos se asignan a varios tipos de datos utilizando patrones de índice. Los patrones de índice crean una estructura de datos de campos y valores con formato JSON. Los tipos de datos de los campos pueden estar en los siguientes formatos:
- Core Datatypes: Texto (cadenas), numérico, fecha, booleano, binario y rango
- Complex Datatypes: Objeto (JSON), Anidado (matrices de objetos JSON)
- Geo Datatypes: Geo-punto (latitud/longitud), Geo-forma (polígonos)
- Specialized Datatypes: Direcciones IP, recuento de tokens, histograma, etc.)
Usando las bibliotecas de software de Lucene, Elasticsearch tiene su propio lenguaje de consulta basado en JSON llamado Query DSL (Lenguaje específico de dominio). Query DSL incluye consultas de hoja, consultas compuestas y consultas costosas. Las consultas de hoja buscan un valor específico en un campo específico, como las consultas de coincidencia, término o rango. Las consultas compuestas incluyen otras consultas de hoja o compuestas y se utilizan para combinar varias consultas de forma lógica. Las consultas costosas se ejecutan lentamente e incluyen coincidencia difusa, coincidencia de expresiones regulares y coincidencia de caracteres comodín.
Lenguaje de consultas
Junto con JSON, las consultas de Elasticsearch hacen uso de los siguientes elementos: operadores booleanos, campos, rangos, comodines, expresiones regulares, búsqueda difusa, búsqueda de texto.
Operadores booleanos : operadores AND, OR y NOT:
- «php» O «zip» O «exe» O «jar» O «ejecutar»
- «RST» Y «ACK»
Campos – En pares clave: valor separados por dos puntos, especifica el campo clave, dos puntos, un espacio y el valor:
- dst.ip: “192.168.1.5”
- dst.port: 80
Rangos – Puede buscar campos dentro de un rango específico usando corchetes (inclusive) o llaves (exclusivo):
- host:[1 TO 255] — Devolverá eventos con una edad entre 1 y 255
- TTL:{100 TO 400} — Devolverá eventos con precios entre 101 y 399
- name: [Admin TO User] — Devolverá nombres entre e incluyendo Administrador y Usuario
Wildcards – El* carácter\ es para caracteres wildcard de varios caracteres y el ? para caracteres wildcard de un solo carácter:
- P?ssw?rd — Coincidirá con la contraseña y P@ssw0rd
- Pas* — Coincidirá con Pase, Passwd y Contraseña
Regex – se colocan entre barras diagonales (/):
- /d[ao]n/ — Coincidirá con dan y don
- /<.+>/ — Coincidirá con texto similar a una etiqueta HTML
Búsqueda difusa – la búsqueda difusa utiliza la distancia de Damerau-Levenshtein para coincidir con términos similares en la ortografía. Esto es genial cuando el conjunto de datos tiene palabras mal escritas. Utilice la tilde (~) para encontrar términos similares:
- index.php~ – Esto puede devolver resultados como «index.html», «home.php» y «info.php».
- Utilice la tilde (~) junto con un número para especificar qué tan grande puede ser la distancia entre palabras:
- term~2 – Esto coincidirá, entre otras cosas: «equipo», «términos», «trem» y «rasgado»
Búsqueda de texto : escriba el término o valor que desea encontrar. Esto puede ser un campo, o una cadena dentro de un campo, etc.
Ejecución de consultas
Elasticsearch se diseñó para interactuar con usuarios que utilizan clientes basados en web que siguen el marco HTTP REST. Las consultas se pueden ejecutar utilizando los siguientes métodos:
URI – Elasticsearch can execute queries using URI searches:
- http://localhost:9200/_search?q=query:ns.example.com
cURL – Elasticsearch can execute queries using cURL from the command line:
- curl «localhost:9200/\ _search?q=query:ns.example.com»
JSON – Elasticsearch puede ejecutar consultas con una búsqueda en el cuerpo de la solicitud utilizando un documento JSON que comienza con un elemento de consulta y una consulta formateada con el lenguaje específico del dominio de consulta.
Herramientas de desarrollo – Elasticsearch puede ejecutar consultas utilizando la consola Herramientas de desarrollo en Kibana y una consulta formateada utilizando el lenguaje específico de dominio de consulta.
Nota: Las consultas de Elasticksearch avanzadas no se incluyen en el alcance de este curso. En los laboratorios, se suministrarán los enunciados de consultas complejas si es necesario.
27.2.7. Investigación de llamadas de proceso o API
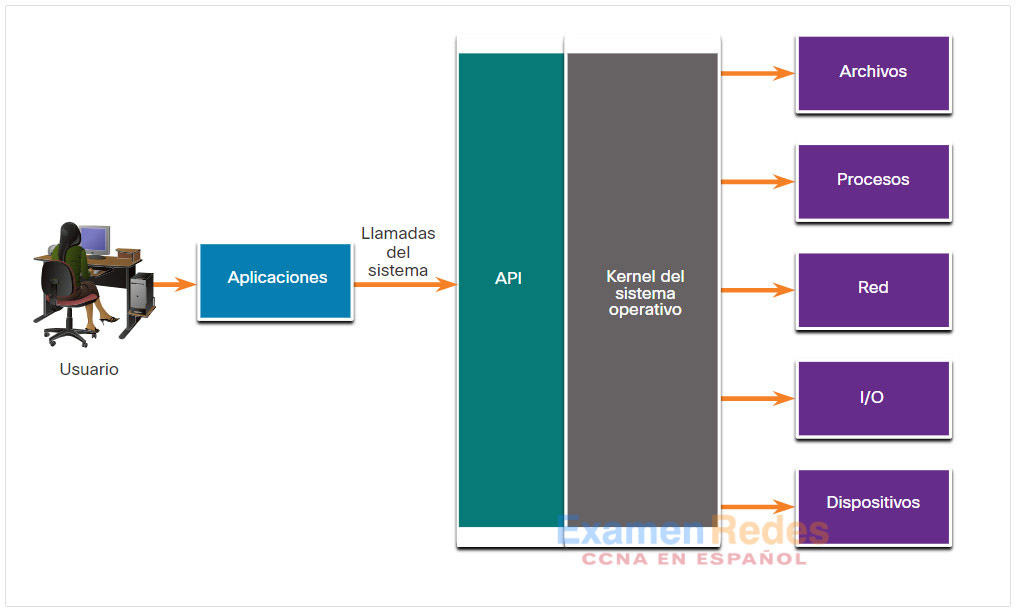
Las aplicaciones interactúan con un sistema operativo (operating system OS) mediante llamadas del sistema a la interfaz de programación de aplicaciones (application programming interface API) del sistema operativo (operating system OS), como se ve en la figura. Estas llamadas del sistema permiten tener acceso a muchos aspectos del funcionamiento del sistema, como las siguientes:
- Control de procesos de software
- Administración de archivos
- Administración de dispositivos
- Administración de la información
- Comunicación
El malware también puede hacer llamadas al sistema. Si el malware puede engañar al kernel de un OS y para que le permita hacer llamadas al sistema, son posibles muchas vulnerabilidades.
El software HIDS rastrea el funcionamiento de un OS host. Las reglas de OSSEC detectan los cambios en parámetros con base en el host, como la ejecución de procesos de software, los cambios en privilegios de usuarios y las modificaciones del registro, entre otros. Las reglas de OSSEC activarán una alerta en Sguil. Girar a Kibana en la dirección IP del host le permite elegir el tipo de alerta según el programa que la creó. El filtrado de índices OSSEC da como resultado una vista de los eventos OSSEC que se produjeron en el host, incluidos los indicadores de que el malware puede haber interactuado con el kernel del sistema operativo
27.2.8. Investigación de detalles de los archivos
En Sguil, si el analista en ciberseguridad sospecha de un archivo, el valor hash se puede enviar a un sitio en línea, como VirusTotal, para determinar si el archivo es un malware conocido. El valor de hash se puede enviar desde la ficha de búsqueda en la página de VirusTotal.
En Kibana, Zeek Hunting se puede utilizar para mostrar información sobre los archivos que han entrado en la red. A partir de los tipos MIME, o medios, que están presentes, se pueden configurar filtros para mostrar información sobre tipos específicos de archivos como application/xml o application/zip. A partir de ahí, se pueden mostrar los detalles de los archivos individuales, como se muestra en la figura. Tenga en cuenta que en Kibana, el tipo de evento se muestra como bro_files, aunque el nuevo nombre de Bro sea Zeek.
Detalles del archivo de Zeek como se muestra en Kibana
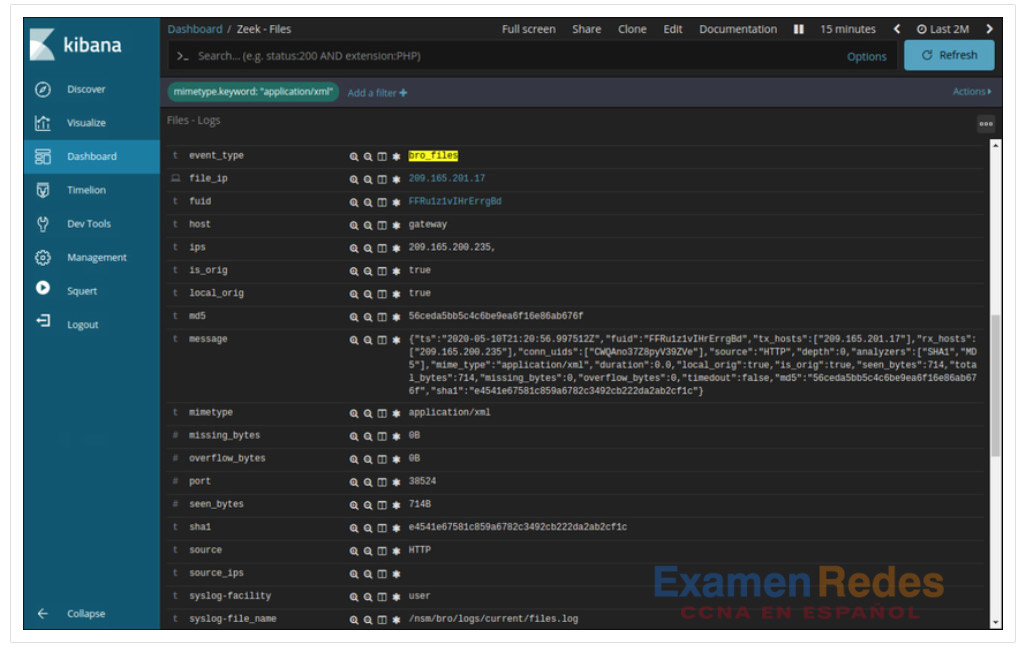
Numerosos detalles están disponibles para los archivos. En este ejemplo, se muestran los hashes MD5 y SHA-1, al igual que otros detalles. Las entradas azules proporcionan pivotes para ver los detalles de la información proporcionada en la tabla en CapMe! u otras herramientas.
27.2.9. Práctica de laboratorio: Tutorial de expresiones regulares
Una expresión regular (regular expression regex) es un patrón de símbolos que describe datos que deben coincidir en una consulta o en cualquier otra operación. Las expresiones regulares se construyen en forma similar a las aritméticas, utilizando diversos operadores para combinar expresiones más pequeñas. Hay dos estándares principales de expresiones regulares, POSIX y Perl.
En esta práctica de laboratorio utilizarán un tutorial en línea para estudiar expresiones regulares. También describirán la información que coincide con expresiones regulares dadas.
27.2.10. Práctica de laboratorio: Extraer un ejecutable de un PCAP
Analizar registros es muy importante, pero también lo es comprender de qué manera suceden las transacciones de red al nivel de los paquetes.
En esta práctica de laboratorio analizarán el tráfico de un archivo pcap previamente capturado y extraerán un ejecutable del archivo.
27.2.11. Video: Interpretar datos HTTP y DNS para aislar a los actores maliciosos
Vea el vídeo para ver un tutorial del laboratorio Security Onion Interpret HTTP and DNS Data to Aislar Threat Actor.
27.2.12. Práctica de laboratorio: Interpretar datos HTTP y DNS para aislar al actor de la amenaza
En este laboratorio, investigará las vulnerabilidades de inyección SQL y exfiltración de DNS mediante herramientas de seguridad Onion.
27.2.13. Video – Aislamiento de hosts afectados mediante 5 tuplas
Vea el video para ver un tutorial del Host comprometido con aislamiento de Security Onion usando el laboratorio de 5 tuplas.
27.2.14. Práctica de laboratorio: Aislar hosts afectados con el método de cinco tuplas
En este laboratorio, usará las herramientas de Security Onion para investigar un ataque utilizando las herramientas de Security onion.
27.2.15. Laboratorio – Investigar un ataque de malware Exploit
En este laboratorio usará Security Onion para investigar un malware más complejo explotar el uso de un kit de ataque para infectar hosts.
27.2.16. Laboratorio – Investigación de un ataque en un host de Windows
En esta práctica de laboratorio:
- Investigar un ataque a un host de Windows.
- Usar Sguil, Kibana y Wireshark en Security Onion para investigar el ataque.
- Examinar artefactos de ataque.
27.3. Cómo mejorar el trabajo del analista de ciberseguridad
27.3.1. Tableros y visualizaciones
Los paneles ofrecen una combinación de datos y visualizaciones diseñada para mejorar el acceso de las personas a grandes cantidades de información. Los tableros suelen ser interactivos. Les permiten a los analistas de ciberseguridad centrarse en detalles e información específicos haciendo clic en los elementos del tablero. Por ejemplo, hacer clic en una barra de un gráfico de barras podría proporcionar un desglose de la información que representa esa barra. ELSA incluye la capacidad de diseñar páneles personalizados. Además, otras herramientas que se incluyen en Security Onion, como Squert, proporcionan una interfaz visual de los datos de NSM.
La interfaz de Kibana para seleccionar las visualizaciones que compondrán un panel personalizado se muestra en la figura.
Selección de visualizaciones para un panel Kibana personalizado
27.3.2. Administración del flujo de trabajo
Debido al carácter fundamental del monitoreo de la seguridad de la red, resulta esencial administrar los flujos de trabajo. Los flujos de trabajo son la secuencia de procesos y procedimientos a través de los cuales se completan las tareas de trabajo. La gestión de los flujos de trabajo de SOC mejora la eficiencia del equipo de operaciones cibernéticas, aumenta la responsabilidad del personal y garantiza que todas las posibles alertas se traten correctamente. En las grandes organizaciones de seguridad, es aceptable recibir miles de alertas cada día. El personal de ciberoperaciones debe asignar, procesar y documentar sistemáticamente cada alerta.
La automatización de runbook o los sistemas de administración del flujo de trabajo proporcionan las herramientas necesarias para optimizar y controlar los procesos en un centro de operaciones de ciberseguridad. Sguil proporciona administración básica del flujo de trabajo. Sin embargo, no es una buena opción para las operaciones grandes con muchos empleados. En cambio, hay disponibles sistemas de administración del flujo de trabajo de terceros que pueden personalizarse para satisfacer las necesidades de las operaciones de ciberseguridad.
Además, las consultas automatizadas son útiles para aumentar la eficiencia del flujo de trabajo de ciberoperaciones. Estas consultas, a veces denominadas estrategias o cuadernos de estrategias, buscan automáticamente incidentes de seguridad complejos que puedan sortear otras herramientas. En Kibana, las búsquedas filtradas se pueden convertir en visualizaciones, que se pueden actualizar y supervisar dinámicamente para realizar un seguimiento de eventos. La pila ELK puede agregar funcionalidad de alerta instalando la extensión X-Pack en Elastic. X-Pack es una extensión comercial de Elasticsearch y ofrece funciones de seguridad, alertas, supervisión, generación de informes y gráficos. Elasticsearch proporciona múltiples formas de notificación de alertas y puede notificar a los analistas de ciberseguridad por correo electrónico u otros medios. Además de X-Pack, Elastic.co también ofrece su propio producto comercial Elastic SIEM con capacidades avanzadas de supervisión, alerta y orquestación.
27.4. Trabajar con resumen de datos de seguridad de la red
27.4.1. ¿Qué aprendí en este módulo?
Una plataforma común para los datos
Debido a la diversidad de datos de supervisión de red, una plataforma de supervisión de seguridad de red debe unir los datos para su análisis. ELK, o The Elastic Stack, es una plataforma de este tipo. ELK consiste en Elasticsearch, Logstash y Kibana con Beats, ElastAlert y Curator. Estos componentes permiten la recopilación, normalización y análisis de datos de supervisión de red. Elasticsearch permite una búsqueda rápida de grandes cantidades de datos. Los módulos Logstash y Beats compilan y normalizan datos de muchas fuentes, y Kibana proporciona una interfaz gráfica de usuario y herramientas para analizar los datos. Los datos de red deben reducirse para que el sistema NSM procese solo los datos relevantes. Los datos de red también deben normalizarse para convertir los mismos tipos de datos a formatos coherentes. Los datos deben archivarse durante un tiempo razonable y ese período puede especificarse mediante marcos de cumplimiento. Security Onion está configurado para eliminar datos automáticamente si el espacio disponible en disco es demasiado bajo. Curator eliminará los índices Logstash que tienen más de 30 días de forma predeterminada.
Investigación de datos de la red
Sguil proporciona una consola que permite a un analista de ciberseguridad investigar, verificar y clasificar alertas de seguridad. Sguil correlaciona eventos basados en información como direcciones IP de origen y destino y puertos de capa 4, entre otros. Esto despeja la consola del analista al representar eventos relacionados en una sola línea. La columna CNT indica el número de eventos que se han correlacionado para una alerta. Se muestra la primera alerta de la serie. Toda la serie se puede ver en Sguil haciendo clic con el botón derecho en el valor CNT y seleccionando Ver eventos correlacionados. Pivotaje que implica pasar de la información en una aplicación a diferentes herramientas especializadas para ver detalles de esa información. Sguil proporciona formas de gestionar las alertas escalándolas, retirándolas y clasificándolas.
Kibana solo muestra datos de las últimas 24 horas de forma predeterminada. Esto es para evitar que la pantalla se desordene. Al investigar los datos que se produjeron antes de ese período, el analista debe establecer el intervalo de tiempo. Se pueden crear paneles personalizados con una variedad de visualizaciones. Hay varias formas de consultar Elasticsearch mediante Query DSL (Domain Specific Language). Se pueden especificar numerosos operadores, campos, comodines y otros términos. Las consultas se pueden ejecutar enviándolas directamente a un URI RESTful o a través de cURL, cuerpos de consulta JSON. o utilizando Kibana Dev Tools. Las llamadas a procesos y API se pueden investigar trabajando con alertas OSSEC HIDS. Además, se puede acceder a los detalles de los archivos, como tipos de archivos y hashes a través de Kibana y se pueden enviar a una fuente externa para ser identificados como benignos o como malware. Una de esas fuentes es VirusTotal.
Cómo mejorar el trabajo del analista de ciberseguridad
Las visualizaciones de Kibana proporcionan información sobre los datos de NSM al representar grandes cantidades de formatos de datos que son más fáciles de interpretar. Algunos paneles proporcionan la posibilidad de hacer clic en elementos interactivos que proporcionarán información enfocada. La gestión del flujo de trabajo añade eficiencia al trabajo del equipo SOC. La automatización de Runbook, o los sistemas de gestión de flujo de trabajo, proporcionan herramientas para optimizar y controlar los procesos SOC. Las consultas automatizadas también ayudan para agregar eficiencia. Estas consultas, denominadas estrategias o cuadernos de estrategias, buscan automáticamente incidentes de seguridad complejos que puedan sortear otras herramientas.