Última actualización: enero 30, 2022
14.0. Introducción
14.0.1. ¿Por qué debería tomar este módulo?
¡Bienvenido a la automatización de la red!
¿Has configurado la red de tu hogar? ¿Una pequeña red de oficina? Imagina realizar esas tareas en miles de dispositivos finales, enrutadores (routers), conmutadores (switches) y puntos de acceso(access points) ¿Sabes que existen programas que automatizan esas tareas para redes empresariales? De hecho, existen programas que pueden automatizar el diseño de una red empresarial. Puede automatizar todo el monitoreo, operación y mantenimiento de la red. ¿Le interesa? Comience.
14.0.2. ¿Qué aprenderé en este módulo?
Título del módulo: Automatización de la red
Objetivos del módulo: Explicar como habilitar la automatización de red a través de las API RESTful y las herramientas administrativas de configuración.
| Título del tema | Objetivo del tema |
|---|---|
| Descripción general de la automatización | Describa la automatización. |
| Formato de datos | Compare los formatos de datos JSON, YAML y XML. |
| API | Explique cómo las API permiten las comunicaciones de equipo a equipo. |
| REST | Explique cómo REST permite las comunicaciones de equipo a equipo. |
| Administración de la configuración | Compare las herramientas administrativas de configuración Puppet, Chef, Ansible, and SaltStack. |
| IBN y Cisco DNA Center | Explique cómo Cisco DNA Center permite las redes basadas en la intención. |
14.1. Descripción general de la automatización
14.1.1. Video – Automatización por doquier
Ahora vemos la automatización en todas partes, desde las cajas registradoras de autoservicio en las tiendas y los controles ambientales de los edificios automáticos hasta automóviles y vehículos autónomos. ¿Cuántos sistemas automatizados encuentra usted en un solo día?
Haga clic en Reproducir en el video para ver ejemplos de automatización.
14.1.2. El aumento en el uso de la Automatización
La automatización es cualquier proceso impulsado de forma automática que reduce y, a la larga, elimina, la necesidad de intervención humana.
La automatización estuvo una vez limitada a la industria de fabricación. Las tareas altamente repetitivas, como el ensamblaje automotriz, se derivaron a las máquinas y así nació la línea de montaje moderna. Las máquinas son excelentes repitiendo la misma tarea sin fatigarse y sin los errores que los seres humanos son propensos a cometer en estos trabajos.
Estos son algunos de los beneficios de la automatización:
- Las máquinas pueden trabajar las 24 horas sin interrupciones, por ende brindan una mayor producción.
- Las máquinas proporcionan un resultado más uniforme.
- La automatización permite la recolección de grandes cantidades de datos, los cuales pueden analizarse rápidamente, para proporcionar información que guíe un evento o proceso.
- Los robots se utilizan en condiciones peligrosas como la minería, la lucha contra incendios y la limpieza de accidentes industriales. Esto reduce el riesgo para las personas.
- Bajo ciertas circunstancias, los dispositivos inteligentes pueden alterar su uso de energía, realizar diagnósticos médicos, y mejorar la conducción de los automóviles, para que sea más segura.
14.1.3. Dispositivos Inteligentes
¿Pueden los dispositivos pensar? ¿Pueden ellos aprender basados en su alrededor? En este contexto, hay muchas definiciones de la palabra «pensar». Una posible definición es la capacidad para conectar una serie de partes relacionadas de información y usarlas para alterar un curso de acción.
Actualmente muchos dispositivos incorporan tecnologías inteligentes, que ayudan a determinar su comportamiento. Esto puede ser tan simple como cuando un dispositivo inteligente reduce su consumo de energía durante períodos de alta demanda o tan complejo como conducir un auto de manera autónoma.
Cada vez que un dispositivo toma una decisión, en función de información externa, dicho dispositivo se conoce como dispositivo inteligente. En la actualidad muchos dispositivos con los que interactuamos llevan la palabra inteligente en el nombre. Esto indica que el dispositivo tiene la capacidad para alterar su comportamiento según su entorno.
Para que un dispositivo pueda «pensar», el mismo debe ser programado utilizando herramientas de automatización de red.

14.2. Formato de datos
14.2.1. Video – Formato de datos
De hecho, los dispositivos inteligentes, son pequeñas computadoras. Para que un dispositivo inteligente, como un actuador, reaccione a condiciones cambiantes, debe ser capaz de recibir e interpretar la información enviada por otros dispositivos inteligente, como un sensor. Estos dos dispositivos inteligentes deben compartir un «lenguaje» en común, el cual es llamado formato de datos. La información compartida es usada de igual manera por otros dispositivos en la red.
Para aprender acerca del formato de datos haga clic en reproducir.
14.2.2. El concepto del formato de datos
Cuando se comparten datos con personas, las posibilidades para desplegar la información son casi ilimitadas. Por ejemplo, imagina como un restaurante puede presentar su menú. Puede ser solamente texto, una lista con viñetas, o imágenes con una descripción textual, o solamente imágenes Todas estas son maneras diferentes en las cuales el restaurante puede presentar la información de su menú. Una formato bien diseñado, es dictado por su facilidad de interpretación. Este mismo principio aplica a la datos compartidos entre computadoras. Una computadora debe poner los datos en un formato que otra computadora pueda entender.
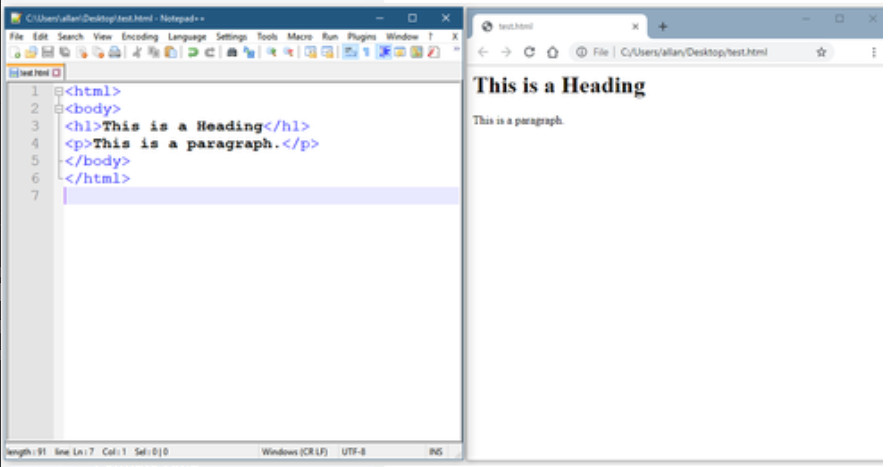
Los formatos son simplemente una manera de almacenar e intercambiar datos de una manera estructurada. Uno de esos formatos es el Lenguaje de marcas de hipertexto (Hypertext Markup Language – HTML). HTML es un estándar que describe la estructura de las páginas web, como se aprecia en la imagen.
Existen algunos formatos de datos comunes que son usados en muchas aplicaciones incluidas automatización de la red y programación;
- Notación de objeto de JavaScript (JavaScript Object Notation – JSON)
- Lenguaje de marcado extensible (XML)
- YAML no es un lenguaje de marcado (YAML Ain’t Markup Language – YAML)
El formato de datos seleccionado dependerá del formato que es usado por la aplicación, herramienta o las instrucciones que usted esté usando. Muchos sistemas pueden soportar más de un formato, lo que le permite al usuario elegir el preferido.
14.2.3. Reglas del formato de datos
El formato de datos posee reglas y estructuras similares a los que tenemos en programación y lenguajes escritos. Cada formato va a tener características específicas:
- La sintaxis, incluye diferentes tipos de símbolos, tales como [ ], ( ), { }, el uso de espacio o sangría, comillas, comas, y más.
- ¿Cómo se representan los objetos?, como caracteres, una cadena de caracteres, una lista, y vectores.
- ¿Cómo se representan los pares llave/valor (key/value)? La llave (key) usualmente se encuentra al lado izquierdo e identifica o describe los datos. El valor (value) que se encuentra al lado derecho, consiste en los datos, los cuales pueden ser caracteres, cadenas de caracteres, números, listas o cualquier otro tipo de información.
Busque en Internet “ubicación ISS” para encontrar una página que permita rastrear la ubicación de la Estación Espacial Internacional. En este sitio usted puede observar los formatos de datos usados y algunas similitudes entre ellos. La página web incluye un enlace para realizar una llamada mediante la interfaz de programación de aplicaciones (Application Programming Interface – API) hacia un servidor, la cual muestra como respuesta la latitud y longitud actual de la estación espacial en conjunto con marca temporal UNIX. El siguiente ejemplo muestra la información enviada por el servidor usando notación de objeto de JavaScript (JavaScript Object Notation – JSON). La información es mostrada en formato bruto. Esto puede dificultar el entendimiento de la estructura de datos.
{"message": "success", "timestamp": 1560789216, "iss_position": {"latitude": "25.9990", "longitude": "-132.6992"}}
Busque en Internet la extensión, para navegadores (browsers), “JSONView” o cualquier extensión que le permita visualizar el formato JSON de manera mas amigable Los objetos de datos son mostrados en pares llave/valor (key/value). El siguiente resultado muestra la misma información usando JSONView. Los pares llave/valor (key/value) son mucho más fáciles de interpretar. En el siguiente ejemplo, usted puede ver la llave (key) latitud (latitude) y su valor (value) 25.9990.
{
"message": "success",
"timestamp": 1560789260,
"iss_position": {
"latitude": "25.9990",
"longitude": "-132.6992"
}
}
Nota: JSONView podría remover las comillas de la sección llave (key). Las comillas son requeridas cuando se codifican pares llave/valor (key/value) en JSON.
14.2.4. Comparar formato de datos
Para ver la misma información en formatos distintos, como XML o YAML, busque alguna herramienta de conversión JSON. En este momento, no es importante entender los detalles de cada formato, pero si debe notar como cada formato usa la sintaxis y como lo pares llave/valor son representados.
Formato JSON
{
"message": "success",
"timestamp": 1560789260,
"iss_position": {
"latitude": "25.9990",
"longitude": "-132.6992"
}
}
Formato YAML
message: success
timestamp: 1560789260
iss_position:
latitude: '25.9990'
longitude: '-132.6992'
Formato XML
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<message>success</message>
<timestamp>1560789260</timestamp>
<iss_position>
<latitude>25.9990</latitude>
<longitude>-132.6992</longitude>
</iss_position>
</root>
14.2.5. Formato Datos JSON
JSON es un formato legible para humanos, usado por aplicaciones para almacenar, transferir y leer información. JSON es relativamente popular y es usado por servicios web y API para brindar información pública. Esto se debe a que es fácil de analizar y puede ser usado con la mayoría de lenguajes de programación moderno, entre ellos Python.
El siguiente ejemplo muestra el resultado parcial de ejecutar el comando show interface GigabitEthernet0/0/0 en el router.
Salida IOS Router
GigabitEthernet0/0/0 is up, line protocol is up (connected) Description: Wide Area Network Internet address is 172.16.0.2/24
Esta misma información puede ser mostrada usando el formato JSON. Nótese que cada objecto (cada par de llave/valor) es una porción de información diferente acerca de las interfaces, incluyendo su nombre, una descripción, y si se encuentra habilitada.
JSON Output
{
"ietf-interfaces:interface": {
"name": "GigabitEthernet0/0/0",
"description": "Wide Area Network",
"enabled": true,
"ietf-ip:ipv4": {
"address": [
{
"ip": "172.16.0.2",
"netmask": "255.255.255.0"
}
]
}
}
}
14.2.6. Reglas de sintaxis JSON
Estas son algunas de las características de el formato JSON:
- JSON utiliza una estructura jerárquica y contiene valores anidados.
- Utiliza llaves { } para almacenar objetos y corchetes [ ] para almacenar vectores.
- Su información es escrita en pares llave/valor (key/value).
En JSON, la información conocida como objetos consiste en uno o mas pares de llaves/valores (key/value) contenidos dentro de llaves { }. La sintaxis de un objecto JSON incluye:
- Las llaves deben ser cadenas de caracteres contenidas dentro de comillas » «.
- Los valores deben ser un tipo de información válida (cadena de caracteres, números, vectores, valores booleanos, carácter nulo, u otro objecto).
- Las llaves y los valores son separados por dos puntos ( :).
- Múltiples pares de llaves/valores dentro de un objeto se separan mediante comas.
- El espacio en blanco no tiene relevancia.
En ocasiones una llave puede tener mas de un valor. Esto es conocido como un vector. Un vector en JSON es una lista ordenada de valores. Las características de un vector en JSON incluyen:
- La llave debe ser seguida por dos puntos (:) y una lista de valores contenidos dentro de corchetes [ ].
- Un vector en JSON es una lista ordenada de valores.
- Un vector puede almacenar diferentes tipos de valores como caracteres, números, valores booleanos, objectos u otro vector.
- Cada valor dentro del vector es separado por una coma.
Por ejemplo, una lista de direcciones IPv4 podría verse de la siguiente manera. La llave es “addresses”. Cada entrada de la lista es un objecto independiente, separado por llaves { }. Los objectos son dos pares de llaves/valores: una dirección IPv4 («ip») y una máscara de red («netmask») separados por una coma. El vector es una lista separa por una coma seguido de una llave de cierre
JSON List of IPv4 Addresses
{
"addresses": [
{
"ip": "172.16.0.2",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.3",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.4",
"netmask": "255.255.255.0"
}
]
}
14.2.7. Formato YAML
YAML es otro tipo de formato usado por aplicaciones para almacenar, transferir y leer información, el cual es legible por humanos. Algunas de las características de YAML incluyen:
- Es considerado una versión mejorada de JSON.
- Tiene un formato minimalista, lo cual lo hace fácil de leer y escribir.
- Utilizar la sangría para definir su estructura, sin utilizar corchetes o comas .
Por ejemplo, observe la siguiente información en formato JSON, relacionada a la interfaz Gigabit Ethernet 2.
JSON para GigabitEthernet2
{
"ietf-interfaces:interface": {
"name": "GigabitEthernet2",
"description": "Wide Area Network",
"enabled": true,
"ietf-ip:ipv4": {
"address": [
{
"ip": "172.16.0.2",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.3",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.4",
"netmask": "255.255.255.0"
}
]
}
}
}
La misma información en formato YAML es más fácil de leer. Similar a JSON, un objeto en YAML se compone de uno o mas pares de llaves/valores. Las llaves y los valores, son separados por medio de dos puntos sin el uso de comillas. En YAML, un guión es usado para separar cada elemento de un lista. El siguiente ejemplo lo muestra para las tres direcciones IPv4.
YAML para GigabitEthernet2
ietf-interfaces:interface:
name: GigabitEthernet2
description: Wide Area Network
enabled: true
ietf-ip:ipv4:
address:
- ip: 172.16.0.2
netmask: 255.255.255.0
- ip: 172.16.0.3
netmask: 255.255.255.0
- ip: 172.16.0.4
netmask: 255.255.255.0
14.2.8. Formato XML
XML es un formato más que legible para humanos, y se utiliza para almacenar, transferir y leer información desde aplicaciones. Algunas de las características de XML incluyen:
- Es similar a HTML , el cual es el lenguaje de marcado generalizado para la creación de páginas y aplicaciones web.
- Es auto-descriptivo. Contiene información dentro de un conjunto de etiquetas: <tag>data</tag>
- A diferencia de HTML, XML no utiliza etiquetas predefinidas, ni una estructura de documento.
Los objectos XML se componen de uno o más pares de llave/valor (key/value), en los cuales la etiqueta inicial funciona como llave: <key>value</key>
El siguiente ejemplo muestra la misma información de GigabitEthernet2 en formato XML. Nótese como los valores están contenidos dentro de las etiquetas de objeto. En este ejemplo, cada par de llaves/valores esta en una línea separada y en algunas se utiliza sangría. Esto último no es requerido, pero se utiliza para mejorar la lectura. La lista utiliza instancias repetitivas de las etiquetas <tag></tag> para cada elemento de la lista Los elementos dentro de estas instancias representan uno o más pares de llaves/valores (key/value).
XML para GigabitEthernet2
<?xml version="1.0" encoding="UTF-8" ?>
<ietf-interfaces:interface>
<name>GigabitEthernet2</name>
<description>Wide Area Network</description>
<enabled>true</enabled>
<ietf-ip:ipv4>
<address>
<ip>172.16.0.2</ip>
<netmask>255.255.255.0</netmask>
</address>
<address>
<ip>172.16.0.3</ip>
<netmask>255.255.255.0</netmask>
</address>
<address>
<ip>172.16.0.4</ip>
<netmask>255.255.255.0</netmask>
</address>
</ietf-ip:ipv4>
</ietf-interfaces:interface>
14.3. API
14.3.1. Video – APIs
Los formatos compartidos entre dispositivos inteligentes generalmente utilizan una interfaz de programación de aplicaciones (Application Programming Interface – API). Como aprenderás en este tema, API es un programa que permite a otras aplicaciones accesar a su información o sus servicios.
Haga clic en reproducir para aprender mas acerca de APIs.
14.3.2. El concepto API
APIs se encuentra prácticamente en todos los sistemas. Amazon Web Services, Facebook, y dispositivos de automatización como los termostatos, refrigeradores y sistemas inalámbricos de iluminación utilizan APIs. También se utilizan en la creación de redes automatizadas
API es un programa que permite a otras aplicaciones accesar a su información o sus servicios. Es un conjunto de reglas que describe cómo una aplicación puede interactuar con otra, y las instrucciones para que esa interacción ocurra. El usuario envía una solicitud API a un servidor solicitando información especifica y recibe una respuesta API desde el servidor con la información solicitada.
Una API es similar a un mesero en un restaurante, como se muestra en el siguiente ejemplo. Un cliente desea que le entreguen comida a su mesa. La comida está en la cocina donde es cocinada y preparada. El mesero es el mensajero, similar a una API. El mesero (la API) es una persona que toma la orden del cliente (la solicitud) y le dice a la cocina que hacer. Cuando la comida esta lista, el mesero entrega la comida (la respuesta) al cliente.
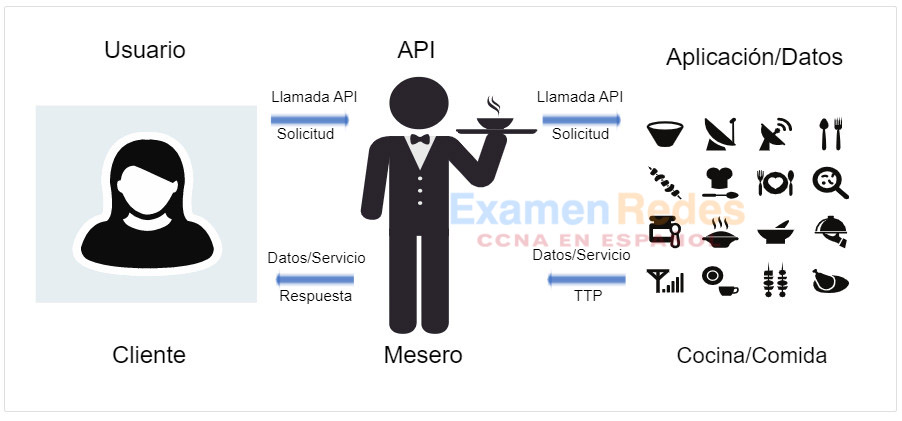
Anteriormente, se vió una solicitud de API a un servidor que devolvió la latitud y longitud actuales de la Estación Espacial Internacional (IIS) Esta fue una API que proporcionó una notificación Abierta para acceder a datos desde un navegador web en la Administración Nacional de Aeronáutica y del Espacio (NASA).
14.3.3. Un ejemplo de API
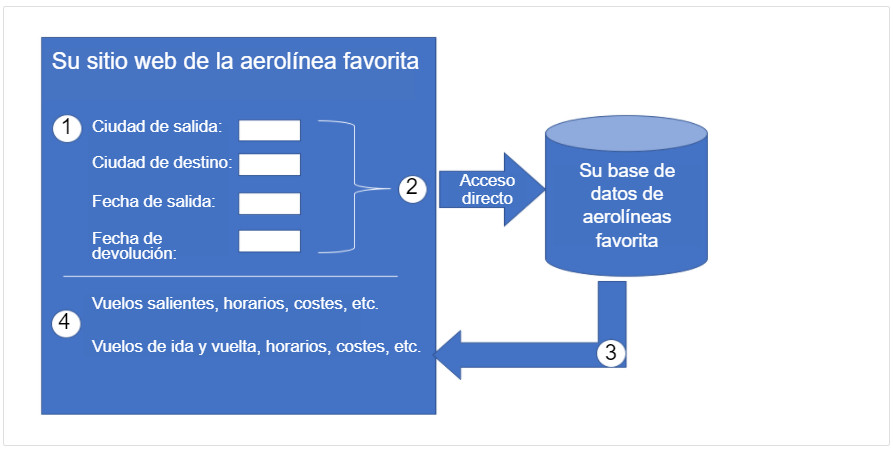
Para entender realmente cómo se pueden utilizar las API para proporcionar datos y servicios, veremos dos opciones para reservar reservas de aerolíneas. La primera opción utiliza el sitio web de una aerolínea específica, como se muestra en la figura. Mediante el sitio web de la aerolínea, el usuario ingresa la información para realizar una solicitud de reserva. El sitio web interactúa directamente con la propia base de datos de la aerolínea y proporciona al usuario información que coincide con la solicitud del usuario.
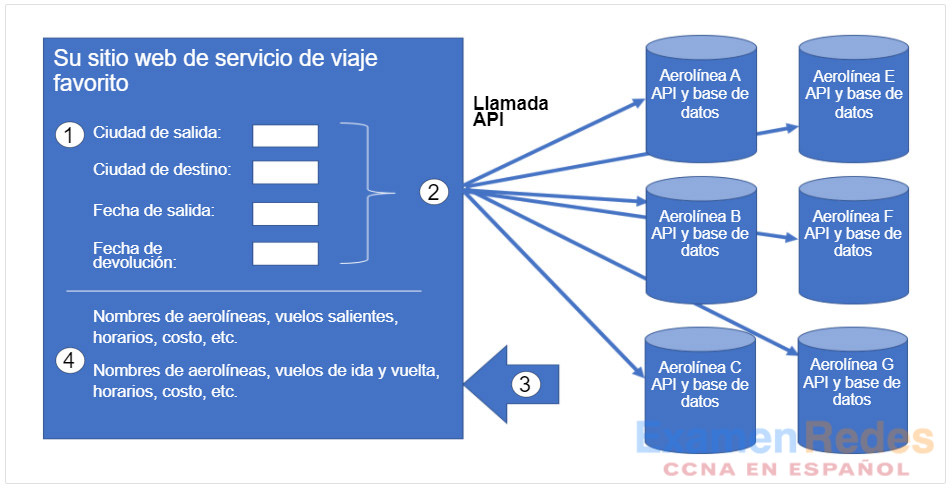
En lugar de utilizar un sitio web de aerolínea individual que tiene acceso directo a su propia información, hay una segunda opción. Los usuarios pueden utilizar un sitio de viaje para acceder a esta misma información, no sólo desde una aerolínea específica, sino una variedad de aerolíneas. En este caso, el usuario introduce información de reserva similar. El sitio web del servicio de viajes interactúa con las diversas bases de datos de aerolíneas mediante las API proporcionadas por cada aerolínea. El servicio de viaje utiliza cada API de aerolínea para solicitar información a esa aerolínea específica y, a continuación, muestra la información de todas las aerolíneas en su página web, como se muestra en la figura.
La API actúa como una especie de mensajero entre la aplicación solicitante y la aplicación en el servidor que proporciona los datos o el servicio. El mensaje de la aplicación solicitante al servidor donde residen los datos se conoce como una llamada a la API.
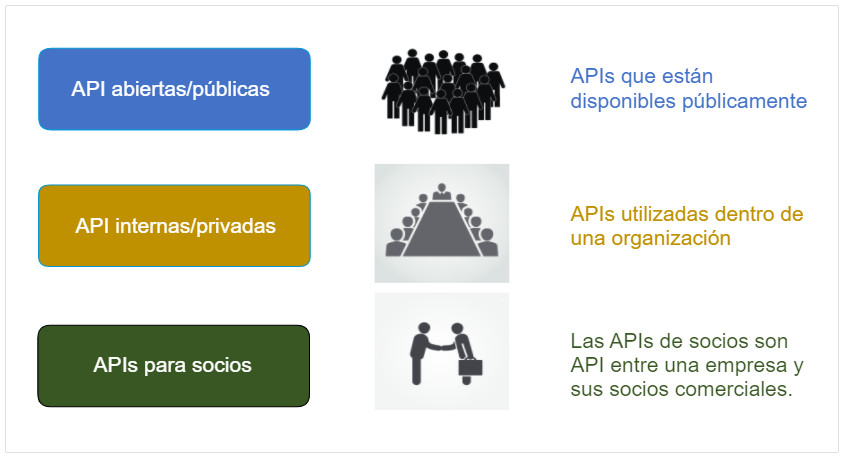
14.3.4. API abiertas, internas y de socios
Una consideración importante al desarrollar una API es la distinción entre API abiertas, internas y de partner:
- APIs abiertas o APIs públicas- : disponibles públicamente y se pueden usar sin restricciones La API de la estación espacial internacional es un ejemplo de una API pública. Dado que estas API son públicas, muchos proveedores de API, como Google Maps, requieren que el usuario obtenga una clave gratuita, o token, antes de usar la API. Esto es para ayudar a controlar la cantidad de solicitudes API que reciben y procesan. Busque en Internet una lista de las API públicas.
- APIs internas o privadas: utilizadas por una organización o empresa para acceder a datos y servicios solo para uso interno únicamente Un ejemplo de una API interna es permitir a los vendedores autorizados acceder a los datos de ventas internas en sus dispositivos móviles.
- API de socios:- son APIs que se utilizan entre una empresa y sus socios comerciales o contratistas para facilitar el negocio entre ellos. El socio comercial debe tener una licencia u otra forma de permiso para usar la API. Un servicio de viaje que utiliza la API de una aerolínea es un ejemplo de una API de socio.
riales, Seguridad y Automatización
v7.02
Saltar a contenido
Automatización de la red
API
API
14.3.1
Video – APIs
Los formatos compartidos entre dispositivos inteligentes generalmente utilizan una interfaz de programación de aplicaciones (Application Programming Interface – API). Como aprenderás en este tema, API es un programa que permite a otras aplicaciones accesar a su información o sus servicios.
Haga clic en reproducir para aprender mas acerca de APIs.
Play Video
14.3.2
El concepto API
APIs se encuentra prácticamente en todos los sistemas. Amazon Web Services, Facebook, y dispositivos de automatización como los termostatos, refrigeradores y sistemas inalámbricos de iluminación utilizan APIs. También se utilizan en la creación de redes automatizadas
API es un programa que permite a otras aplicaciones accesar a su información o sus servicios. Es un conjunto de reglas que describe cómo una aplicación puede interactuar con otra, y las instrucciones para que esa interacción ocurra. El usuario envía una solicitud API a un servidor solicitando información especifica y recibe una respuesta API desde el servidor con la información solicitada.
Una API es similar a un mesero en un restaurante, como se muestra en el siguiente ejemplo. Un cliente desea que le entreguen comida a su mesa. La comida está en la cocina donde es cocinada y preparada. El mesero es el mensajero, similar a una API. El mesero (la API) es una persona que toma la orden del cliente (la solicitud) y le dice a la cocina que hacer. Cuando la comida esta lista, el mesero entrega la comida (la respuesta) al cliente.
El ejemplo muestra como una API es similar a un mesero en un restaurante. El usuario es el cliente, el mesero es la API y la cocina representa las aplicaciones y la información. El cliente/usuario realiza una llamada o solicitud API. El mesero/API toma la solicitud y la entrega a la cocina/aplicación. La cocina/aplicación envía devuelta la información/servicio o respuesta. El mesero/API recibe la respuesta de la cocina/aplicación y la entrega al cliente/usuario.
UsuarioAPIAplicación/DatosClienteMeseroCocina/ComidaLlamada APISolicitudLlamada APISolicitudDatos/ServicioRespuestaDatos/ServicioTTP
Anteriormente, se vió una solicitud de API a un servidor que devolvió la latitud y longitud actuales de la Estación Espacial Internacional (IIS) Esta fue una API que proporcionó una notificación Abierta para acceder a datos desde un navegador web en la Administración Nacional de Aeronáutica y del Espacio (NASA).
14.3.3
Un ejemplo de API
Para entender realmente cómo se pueden utilizar las API para proporcionar datos y servicios, veremos dos opciones para reservar reservas de aerolíneas. La primera opción utiliza el sitio web de una aerolínea específica, como se muestra en la figura. Mediante el sitio web de la aerolínea, el usuario ingresa la información para realizar una solicitud de reserva. El sitio web interactúa directamente con la propia base de datos de la aerolínea y proporciona al usuario información que coincide con la solicitud del usuario.
La figura muestra un ejemplo del uso de una API para reservar una reserva de aerolínea. El ejemplo tiene cuatro pasos. El primer paso es introducir información en el sitio web de las aerolíneas para realizar una solicitud de reserva. Las opciones que se muestran son Departure city, Destination city, Departure date y Return date. El segundo paso es el acceso directo/interacción con la base de datos de aerolíneas. El tercer paso es devolver información que coincida con la solicitud de los usuarios. El cuarto muestra la información al usuario, como vuelos salientes, vuelos de regreso, tiempos, costes, etc.
Su sitio web de la aerolínea favoritaCiudad de salida:Ciudad de destino:Fecha de salida:Fecha de devolución:12Acceso directoSu base de datos de aerolíneas favorita34Vuelos salientes, horarios, costes, etc.Vuelos de ida y vuelta, horarios, costes, etc.
En lugar de utilizar un sitio web de aerolínea individual que tiene acceso directo a su propia información, hay una segunda opción. Los usuarios pueden utilizar un sitio de viaje para acceder a esta misma información, no sólo desde una aerolínea específica, sino una variedad de aerolíneas. En este caso, el usuario introduce información de reserva similar. El sitio web del servicio de viajes interactúa con las diversas bases de datos de aerolíneas mediante las API proporcionadas por cada aerolínea. El servicio de viaje utiliza cada API de aerolínea para solicitar información a esa aerolínea específica y, a continuación, muestra la información de todas las aerolíneas en su página web, como se muestra en la figura.
La figura muestra un ejemplo del uso de una API para reservar una reserva de aerolínea. El ejemplo tiene cuatro pasos. El primer paso es introducir información en el sitio web de las aerolíneas para realizar una solicitud de reserva. Las opciones que se muestran son Departure city, Destination city, Departure date y Return date. El segundo paso, el sitio de viajes interactúa con varias bases de datos de aerolíneas utilizando las API proporcionadas por cada sitio web. El tercer paso que las aerolíneas devuelven información que coincide con la solicitud. El cuarto muestra la información al usuario, como vuelos salientes, vuelos de regreso, tiempos, costes, etc.
Su sitio web de servicio de viaje favoritoCiudad de salida:Ciudad de destino:Fecha de salida:Fecha de devolución:12Aerolínea A API y base de datosAerolínea B API y base de datosAerolínea C API y base de datosAerolínea E API y base de datosAerolínea F API y base de datosAerolínea G API y base de datos34Nombres de aerolíneas, vuelos salientes, horarios, costo, etc.Nombres de aerolíneas, vuelos de ida y vuelta, horarios, costo, etc.Llamada API
La API actúa como una especie de mensajero entre la aplicación solicitante y la aplicación en el servidor que proporciona los datos o el servicio. El mensaje de la aplicación solicitante al servidor donde residen los datos se conoce como una llamada a la API.
14.3.4
API abiertas, internas y de socios
Una consideración importante al desarrollar una API es la distinción entre API abiertas, internas y de partner:
APIs abiertas o APIs públicas- : disponibles públicamente y se pueden usar sin restricciones La API de la estación espacial internacional es un ejemplo de una API pública. Dado que estas API son públicas, muchos proveedores de API, como Google Maps, requieren que el usuario obtenga una clave gratuita, o token, antes de usar la API. Esto es para ayudar a controlar la cantidad de solicitudes API que reciben y procesan. Busque en Internet una lista de las API públicas.
APIs internas o privadas: utilizadas por una organización o empresa para acceder a datos y servicios solo para uso interno únicamente Un ejemplo de una API interna es permitir a los vendedores autorizados acceder a los datos de ventas internas en sus dispositivos móviles.
API de socios:- son APIs que se utilizan entre una empresa y sus socios comerciales o contratistas para facilitar el negocio entre ellos. El socio comercial debe tener una licencia u otra forma de permiso para usar la API. Un servicio de viaje que utiliza la API de una aerolínea es un ejemplo de una API de socio.
La figura ilustra la distinción entre las API abiertas, internas y asociadas. Las API abiertas/públicas son API que están disponibles públicamente. La figura tiene una imagen de un gran grupo de individuos. Las API internas/privadas se utilizan dentro de una organización. La figura tiene una imagen de un grupo de figuras sentados a la mesa en una reunión. Las API de socios son API entre una empresa y sus socios comerciales. La figura tiene una imagen de dos figuras de negocio sacudiéndose la mano.
API abiertas/públicasAPI internas/privadasAPIs para sociosAPIs que están disponibles públicamenteAPIs utilizadas dentro de una organizaciónLas APIs de socios son API entre una empresa y sus socios comerciales.
14.3.5. Tipos de APIs de servicios web
Un servicio web es un servicio que está disponible a través de Internet, utilizando la World Wide Web. Existen cuatro tipos de APIs de servicios web:
- Protocolo simple de acceso a objetos (SOAP, Simple Object Access Protocol)
- Transferencia de estado representacional (REST, Representational State Transfer)
- Llamada a procedimiento remoto de lenguaje de marcado extensible (XML-RPC, eXtensible Markup Language-Remote Procedure Call)
- Llamada a procedimiento remoto de notación de objetos JavaScript (JSON-RPC, JavaScript Object Notation-Remote Procedure Call)
| Característica | SOAP | REST | XML-RPC | JSON-RPC |
|---|---|---|---|---|
| Formato de Datos: | XML | JSON, XML, YAML y otros | XML | JSON |
| First released | 1998 | 2000 | 1998 | 2005 |
| Puntos fuertes | Bien establecido | Formateo flexible y más utilizado | Bien establecido, simplicidad |
SOAP es un protocolo de mensajería para intercambiar información XML-estructured, la mayoría de las veces a través de HTTP o Simple Mail Transfer Protocol (SMTP). Diseñadas por Microsoft en 1998, las API SOAP se consideran lentas de analizar, complejas y rígidas.
Esto llevó al desarrollo de un marco de API REST más simple que no requiere XML. REST utiliza HTTP, es menos detallado y es más fácil de usar que SOAP. REST se refiere al estilo de la arquitectura de software y se ha vuelto popular debido a su rendimiento, escalabilidad, simplicidad y confiabilidad.
REST es la API de servicio web más utilizada, que representa más del 80% de todos los tipos de API utilizados. REST se discutirá más adelante en este módulo.
RPC es cuando un sistema solicita que otro sistema ejecute código y devuelva la información. Esto se hace sin tener que entender los detalles de la red. Esto funciona de forma muy similar a una API REST, pero hay diferencias relacionadas con el formato y la flexibilidad. XML-RPC es un protocolo desarrollado antes de SOAP y más tarde evolucionó en lo que se convirtió en SOAP. JSON-RPC es un protocolo muy simple y similar a XML-RPC.
14.4. REST
14.4.1. Video – REST
Como acaba de aprender, REST es actualmente la API más utilizada. En este tema se trata REST con más detalle.
Haga clic en Reproducir en el video para obtener más información sobre REST.
14.4.2. API REST y RESTful
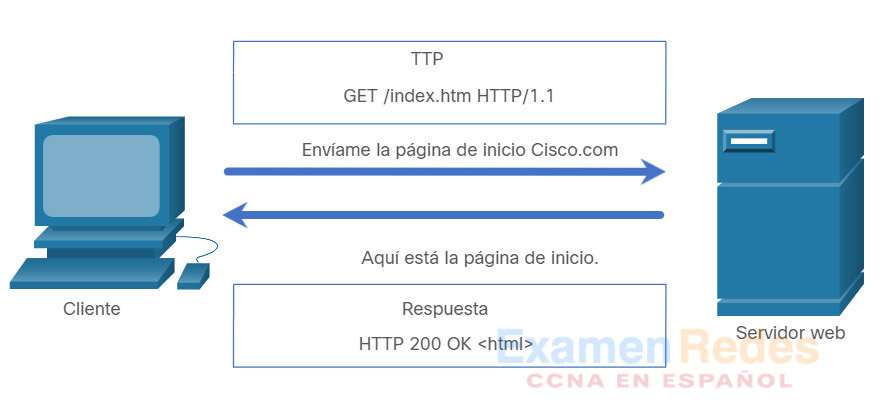
Los exploradores web utilizan HTTP o HTTPS para solicitar (GET) una página web. Si se solicita correctamente (código de estado HTTP 200), los servidores web responden a las solicitudes GET con una página web codificada HTML, como se muestra en la figura.

REST es un estilo arquitectónico para diseñar aplicaciones de servicio web. Se refiere a un estilo de arquitectura web que tiene muchas características subyacentes y gobierna el comportamiento de los clientes y servidores. En pocas palabras, una API REST es una API que funciona encima del protocolo HTTP. Define un conjunto de funciones que los desarrolladores pueden usar para realizar solicitudes y recibir respuestas a través del protocolo HTTP como GET y POST.
El cumplimiento de las restricciones de la arquitectura REST generalmente se conoce como «RESTful». Una API puede considerarse «RESTful» si tiene las siguientes características:
- Cliente/servidor – El cliente maneja el front-end y el servidor maneja el back-end. Cualquiera de los dos puede ser reemplazado independientemente del otro.
- Sin estado – No se almacenan datos del cliente en el servidor entre solicitudes. El estado de la sesión se almacena en el cliente.
- Cacheable – los clientes pueden almacenar en caché las respuestas localmente para mejorar el rendimiento.
14.4.3. Implementación RESTful
Un servicio web RESTful se implementa mediante HTTP. Es una colección de recursos con cuatro aspectos definidos:
- Identificador uniforme de recursos (URI) base para el servicio web, como http://example.com/resources.
- El formato de datos admitido por el servicio web. A menudo es JSON, YAML o XML, pero podría ser cualquier otro formato de datos que sea un estándar de hipertexto válido.
- El conjunto de operaciones admitidas por el servicio web mediante métodos HTTP.
- La API debe estar controlada por hipertexto.
Las API RESTful utilizan métodos HTTP comunes, como POST, GET, PUT, PATCH y DELETE. Como se muestra en la tabla siguiente, esto corresponde a operaciones RESTful: Crear, Leer, Actualizar y Eliminar (o CRUD).
| Método HTTP: | Operación RESTful |
|---|---|
| POST | Crear |
| GET | lectura |
| PUT/PATCH | Actualizar |
| DELETE | Eliminar |
En la figura, la solicitud HTTP solicita datos con formato JSON. Si la solicitud se construye correctamente de acuerdo con la documentación de la API, el servidor responderá con datos JSON. La aplicación web de un cliente puede utilizar estos datos JSON para mostrar los datos. Por ejemplo, una aplicación de mapeo de teléfonos inteligentes muestra la ubicación de San José, California.

14.4.4. URI, URN, y URL
Los recursos web y los servicios web, como las API RESTful, se identifican mediante un URI. Un URI es una cadena de caracteres que identifica un recurso de red específico. Como se muestra en la figura, un URI tiene dos especializaciones:
- Nombre uniforme de recurso (URN): -identifica solo el espacio de nombres del recurso (página web, documento, imagen, etc.) sin referencia al protocolo.
- Localizador uniforme de recursos (URL): – define la ubicación de red de un recurso específico en la red. HTTP or HTTPS URLs se usan tipicamente con web browsers. Otros protocolos como FTP, SFTP, SSH y otros pueden usar una dirección URL. Una URL que usa SFTP podría tener el siguiente aspecto: sftp://sftp.example.com.
Estas son las partes de un URI, tal y como se muestra en la figura:
- Protocolo/esquema: – HTTPS u otros protocolos como FTP, SFTP, mailto y NNTP
- Nombre de host \www.example.com
- Path and file name – /author/book.html
- Fragmento – #página155
Parts of a URI

14.4.5. Anatomía de una solicitud RESTful
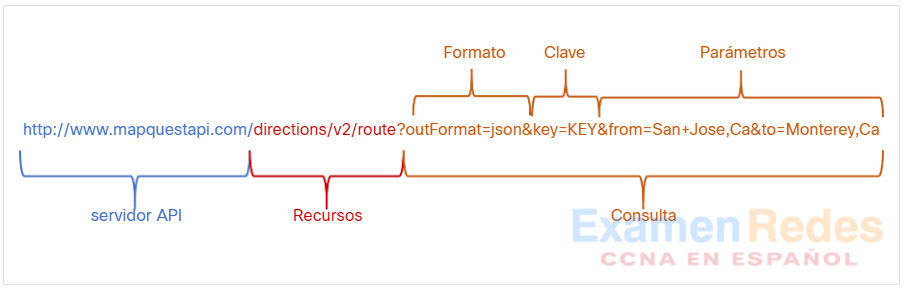
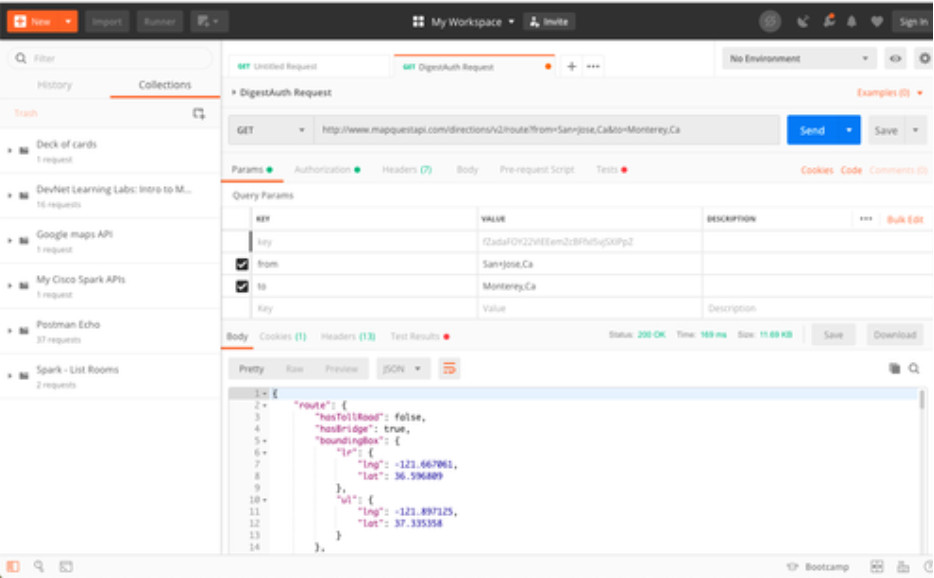
En un servicio web RESTful, una solicitud realizada al URI de un recurso obtendrá una respuesta. La respuesta será una carga normalmente formateada en JSON, pero podría ser HTML, XML o algún otro formato. La figura muestra el URI de la API de direcciones de MapQuest. La solicitud de API es para indicaciones desde San José, California hasta Monterey, California.
Partes de una solicitud de API
La figura muestra parte de la respuesta de la API. En este ejemplo son las direcciones de MapQuest de San José a Monterrey en formato JSON.
Carga JSON parcial recibida de una solicitud de API

Estas son las diferentes partes de la solicitud de API:
- Servidor API: – es la dirección URL del servidor que responde a las solicitudes REST. En este ejemplo es el servidor de la API de MapQuest.
- Recursos – especifica la API que se está solicitando. En este ejemplo es la API de direcciones de MapQuest.
- Consulta: – especifica el formato de datos y la información que el cliente solicita al servicio de API. Las consultas pueden incluir:
- Formato: – normalmente es JSON, pero puede ser YAML o XML. En este ejemplo se solicita JSON.
- Clave: – La clave es para autorización, si es necesario. MapQuest requiere una clave para su API de direcciones. En el URI anterior, deberá reemplazar «KEY» por una clave válida para enviar una solicitud válida.
- Parámetros: – los parámetros se utilizan para enviar información relativa a la solicitud. En este ejemplo, los parámetros de consulta incluyen información acerca de las direcciones que necesita la API para que sepa qué direcciones devolver: «from-San+Jose,Ca» y «to-Monterey,Ca».
Muchas API RESTful, incluidas las API públicas, requieren una clave. La clave se utiliza para identificar el origen de la solicitud a través de la autenticación. Estas son algunas razones por las que un proveedor de API puede requerir una clave:
- Para autenticar la fuente y asegurarse de que esté autorizada para usar la API
- para limitar el número de personas que usan la API
- Para limitar el número de solicitudes por usuario.
- Para capturar y rastrear mejor los datos que solicitan los usuarios
- Para recopilar información sobre las personas que usan la API
Nota: Si desea utilizar la API de MapQuest, la API requiere una clave. Busque en Internet la URL para obtener una clave MapQuest. Utilice los parámetros de búsqueda: developer.mapquest. También puede buscar en Internet la URL actual que describe la política de privacidad de MapQuest.
14.4.6. Aplicaciones de API RESTful
Muchos sitios web y aplicaciones utilizan las API para acceder a la información y proporcionar el servicio a sus clientes. Por ejemplo, cuando se utiliza un sitio web de servicio de viajes, el servicio de viajes utiliza la API de varias aerolíneas para proporcionar al usuario información de aerolíneas, hoteles y otra.
Algunas solicitudes de API RESTful se pueden realizar escribiendo el URI desde un explorador web. La API de direcciones de MapQuest es un ejemplo de esto. Una solicitud de API RESTful también se puede realizar de otras maneras.
Haga clic en cada escenario de aplicación de API a continuación para obtener más información.
- Sitio Web para desarrolladores
- Postman
- Python
- Sistemas operativos de red
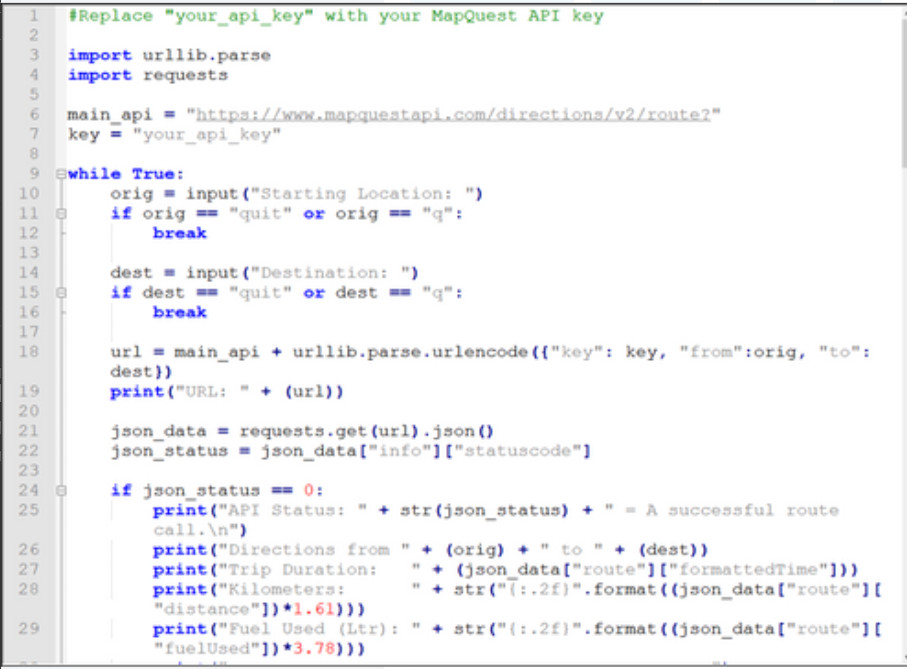
$ ssh [email protected] -p 830 -s netconf [email protected]'s password: <hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <capabilities> <capability>urn:ietf:params:netconf:base:1.1</capability> <capability>urn:ietf:params:netconf:capability:candidate:1.0</capability> <capability>urn:ietf:params:xml:ns:yang:ietf-netconf-monitoring</capability> <capability>urn:ietf:params:xml:ns:yang:ietf-interfaces</capability> [output omitted and edited for clarity] <capabilities> <session-id>19150</session-id></hello>
14.5. Herramientas de administración de configuración
14.5.1. Video – Herramientas de administración de configuración
Como se mencionó en la introducción a este módulo, la configuración de una red puede llevar mucho tiempo. Las herramientas de administración de configuración pueden ayudarle a automatizar la configuración de routers, switches, firewalls y muchos otros aspectos de su red.
Haga clic en reproducir en el vídeo para obtener más información sobre las herramientas de administración de configuración.
14.5.2. Configuración de red tradicional
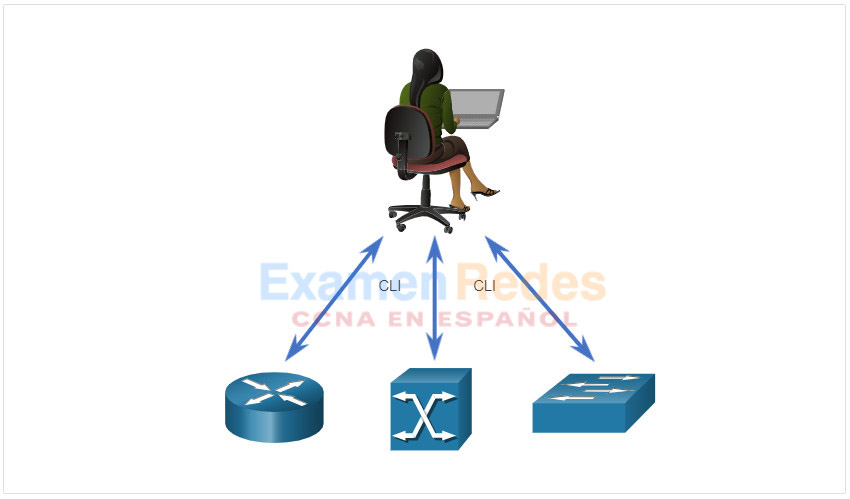
Los dispositivos de red tales como router, switches, y firewalls han sido configurados tradicionalmente por un administrador de red usando el CLI, tal y como se muestra en la figura. Siempre que haya un cambio o una nueva característica, los comandos de configuración necesarios se deben ingresar manualmente en todos los dispositivos apropiados. En muchos casos, esto no sólo consume mucho tiempo, sino que también puede ser propenso a errores. Esto se convierte en un problema importante en redes más grandes o con configuraciones más complejas.
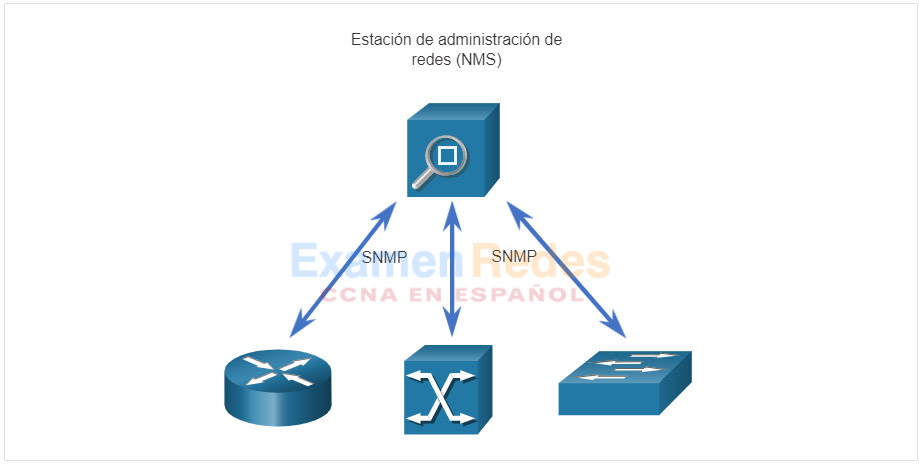
El protocolo simple de administración de redes (SNMP) se desarrolló para que los administradores puedan administrar nodos como servidores, estaciones de trabajo, routers, switches y dispositivos de seguridad en una red IP. Usando una estación de administración de red (NMS, network management station), como se muestra en la figura siguiente, SNMP permite a los administradores de red supervisar y administrar el rendimiento de la red, buscar y resolver problemas de red y realizar consultas para estadísticas. SNMP funciona razonablemente bien para la supervisión de dispositivos. Sin embargo, no se utiliza normalmente para la configuración debido a problemas de seguridad y dificultad en la implementación. Aunque SNMP está ampliamente disponible, este no puede servir como una herramienta de automatización para las redes actuales.
También puede usar las API para automatizar la implementación y administración de recursos de red. En lugar de que el administrador de red configure manualmente los puertos, las listas de acceso, la calidad de servicio (QoS) y las directivas de equilibrio de carga, pueden usar herramientas para automatizar las configuraciones. Estas herramientas se enlazan a las APIs de red para automatizar las tareas rutinarias de aprovisionamiento de red, lo que permite al administrador seleccionar e implementar los servicios de red que necesitan. Esto puede reducir significativamente muchas tareas repetitivas y mundanas para liberar tiempo para que los administradores de red trabajen en cosas más importantes.
14.5.3. Automatización de la red
Nos estamos alejando rápidamente de un mundo en el que un administrador de red administra unas pocas docenas de dispositivos de red, a uno en el que están implementando y administrando cientos, miles e incluso decenas de miles de dispositivos de red complejos (tanto físicos como virtuales) con la ayuda de software. Esta transformación se está extendiendo rápidamente desde sus inicios en el centro de datos, a todos los lugares de la red. Existen métodos nuevos y diferentes para que los operadores de red supervisen, administren y configuren automáticamente la red. Como se muestra en la figura, estos incluyen protocolos y tecnologías como REST, Ansible, Puppet, Chef, Python, JSON, XML y más.
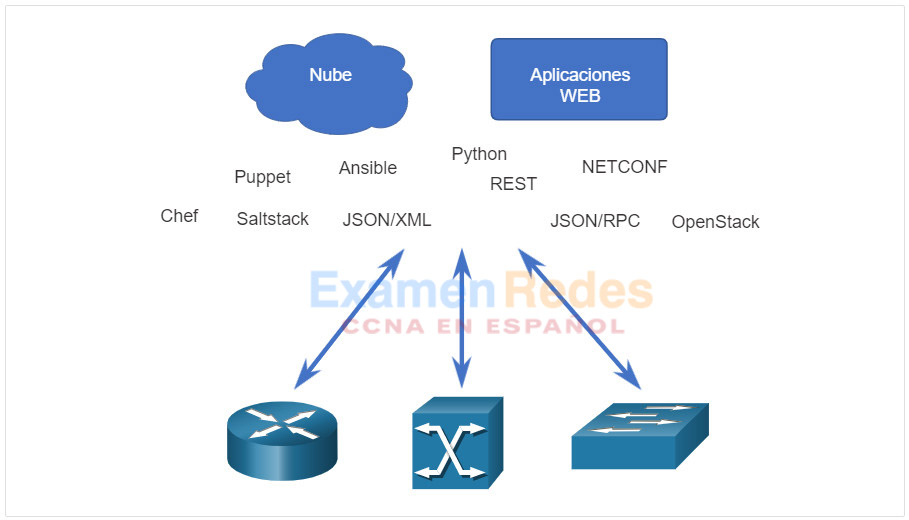
14.5.4. Herramientas de administración de configuración
Las herramientas de administración de configuración utilizan las solicitudes de API RESTful para automatizar tareas y pueden escalar en miles de dispositivos. Las herramientas de administración de configuración mantienen las características de un sistema o red para la coherencia. Estas son algunas características de la red que los administradores se benefician de la automatización:
- ‘Control de versión de software’
- Atributos del dispositivo, como nombres, direccionamiento y seguridad
- Configuración de protocolos
- Configuraciones de ACL
Las herramientas de gestión de la configuración suelen incluir automatización y orquestación. La automatización realiza automáticamente una tarea en un sistema. Esto podría estar configurando una interfaz o implementando una VLAN. La orquestación es el proceso de cómo deben realizarse todas estas actividades automatizadas, como el orden en el que deben realizarse, lo que debe completarse antes de que se inicia otra tarea, etc. La orquestación es la organización de las tareas automatizadas que da como resultado un proceso de coordenadas o un flujo de trabajo.
Hay varias herramientas disponibles para facilitar la gestión de la configuración:
- Ansible
- Chef
- Puppet
- SaltStack

El objetivo de todas estas herramientas es reducir la complejidad y el tiempo que implica configurar y mantener una infraestructura de red a gran escala con cientos, incluso miles de dispositivos. Estas mismas herramientas también pueden beneficiar a redes más pequeñas.
14.5.5. Compare Ansible, Chef, Puppet y SaltStack
Ansible, Chef, Puppet y SaltStack vienen con documentación de API para configurar solicitudes de API RESTful. Todos ellos admiten JSON y YAML, así como otros formatos de datos. En la tabla siguiente se muestra un resumen de una comparación de las principales características de las herramientas de administración de configuración de Ansible, Puppet, Chef y SaltStack.
| Característica | Ansible | Chef | Puppet | SaltStack |
|---|---|---|---|---|
| Lenguaje de programación | Python + YAML | Ruby | Ruby | Python |
| ¿Basado en agentes o sin agente? | Sin agente | Basado en agentes | Soporta ambos | Soporta ambos |
| ¿Cómo se administran los dispositivos? | Cualquier dispositivo puede ser “controller” | Chef Master | Puppet Master | Salt Master |
| ¿Qué crea la herramienta? | Cuaderno de estrategias | Cookbook | Manifesto | Pilar |
- Lenguaje de programación – Ansible y SaltStack están construidos en Python, mientras que Puppet y Chef están construidos en Ruby. Al igual que Python, Ruby es un lenguaje de programación de código abierto que es multiplataforma. Ruby generalmente se considera un lenguaje más difícil de aprender que Python.
- ¿Basado en agentes o sin agente? – La administración de configuración está basada en agentes o sin agente. La administración de configuración basada en agente se «basa en extracción», lo que significa que el agente del dispositivo administrado se conecta periódicamente con el maestro para obtener su información de configuración. Los cambios se realizan en el Master y se tiran hacia abajo y se ejecutan por el dispositivo. La administración de configuración sin agente está «basada en inserción». Se ejecuta un script de configuración en el maestro. El maestro se conecta al dispositivo y ejecuta las tareas del script. De las cuatro herramientas de configuración de la tabla, solo Ansible no tiene agente.
- ¿Cómo se administran los dispositivos? – Esto radica en un dispositivo llamado El Master en Títeres, Chef y SaltStack. Sin embargo, debido a que Ansible no tiene agentes, cualquier equipo puede ser el controlador.
- ¿Qué crea la herramienta? – Los administradores de red utilizan herramientas de administración de configuración para crear un conjunto de instrucciones a ejecutar. Cada herramienta tiene su propio nombre para estas instrucciones: Libro de jugadas, Libro de cocina, Manifiesto y Pilar. Común a cada uno de estos es la especificación de una directiva o una configuración que se va a aplicar a los dispositivos. Cada tipo de dispositivo puede tener su propia directiva. Por ejemplo, todos los servidores Linux podrían obtener la misma configuración básica y la misma directiva de seguridad.
14.6. IBN y Cisco DNA Center
14.6.1. Video: redes basadas en la intención
Usted ha aprendido de las muchas herramientas y software que pueden ayudarle a automatizar su red. Intent-Based Networking (IBN) y Cisco Digital Network Architecture (DNA) Center pueden ayudarle a reunir todo para crear una red automatizada.
Haga clic en Reproducir (Play) en la figura para ver un vídeo de John Apostolopoulos y Anand Oswal de Cisco que explican cómo la inteligencia artificial y las redes basadas en la intención (IBN) pueden mejorar las redes.
14.6.2. Descripción general de las redes basadas en la intención
IBN es el modelo de industria emergente para la próxima generación de redes. IBN se basa en las redes definidas por software (SDN), transformando un enfoque manual y centrado en el hardware para diseñar y operar redes en uno que esté centrado en el software y totalmente automatizado.
Los objetivos de negocio para la red se expresan como intención. IBN captura la intención del negocio y utiliza análisis, aprendizaje automático y automatización para alinear la red de forma continua y dinámica a medida que cambian las necesidades del negocio.
IBN captura y traduce la intención empresarial en políticas de red que se pueden automatizar y aplicar de forma coherente en toda la red.
Cisco considera que IBN tiene tres funciones esenciales: traducción, activación y seguridad. Estas funciones interactúan con la infraestructura física y virtual subyacente, como se muestra en la figura.
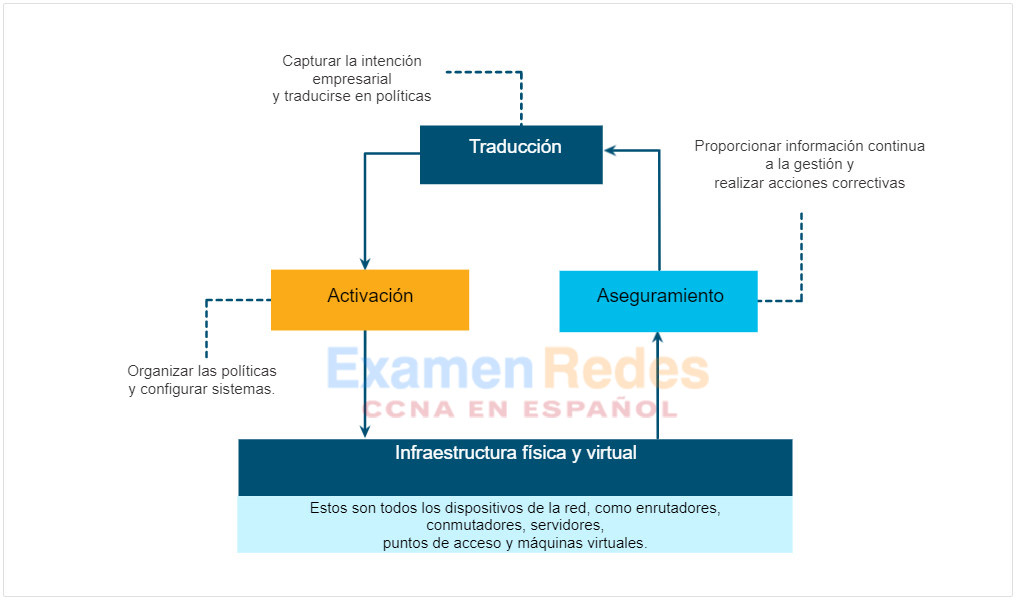
- Traducción: – la función de traducción permite al administrador de red expresar el comportamiento de red esperado que mejor admitirá la intención empresarial.
- Activación: – la intención capturada debe interpretarse en directivas que se pueden aplicar a través de la red. La función de activación instala estas directivas en la infraestructura de red física y virtual mediante la automatización en toda la red.
- Aseguramiento – Para comprobar continuamente que la red respeta la intención expresada en cualquier momento, la función de aseguramiento mantiene un bucle continuo de validación y verificación.
14.6.3. Infraestructura de red como tejido
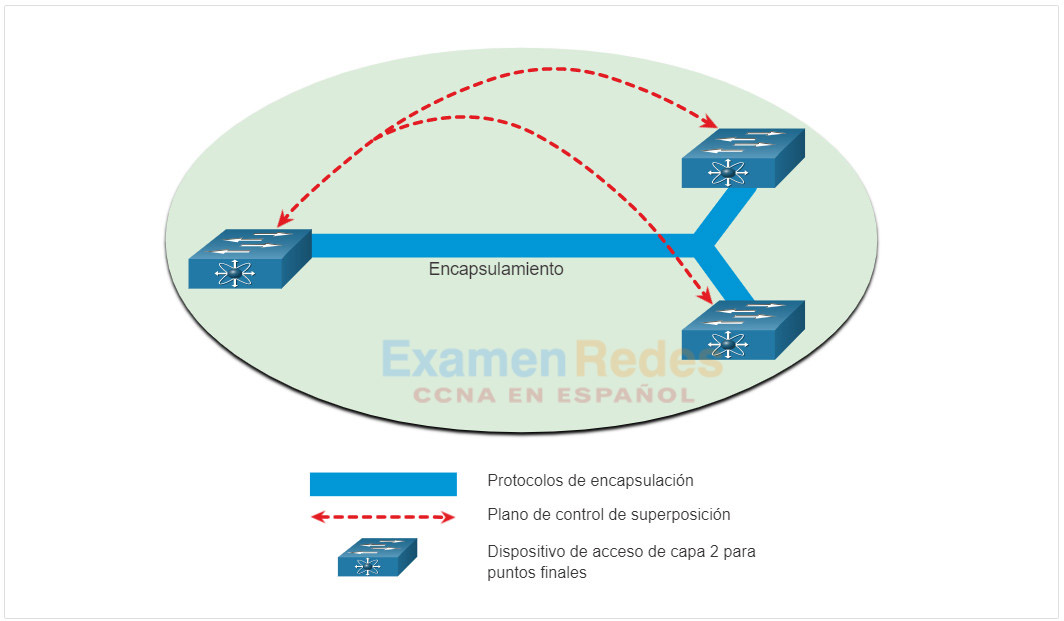
Desde la perspectiva de IBN, la infraestructura de red física y virtual es un tejido. Fabric es un término utilizado para describir una superposición que representa la topología lógica utilizada para conectarse virtualmente a los dispositivos, como se muestra en la figura. La superposición limita el número de dispositivos que el administrador de red debe programar. También proporciona servicios y métodos de reenvío alternativos no controlados por los dispositivos físicos subyacentes. Por ejemplo, la superposición es donde ocurren los protocolos de encapsulación como la Seguridad IP (IPsec) y el control y el aprovisionamiento de los Puntos de acceso inalámbricos (CAPWAP). Mediante una solución IBN, el administrador de red puede especificar a través de directivas exactamente lo que sucede en el plano de control de superposición. Observe que cómo los switches están conectados físicamente no es una preocupación de la superposición.
Ejemplo de red superpuesta
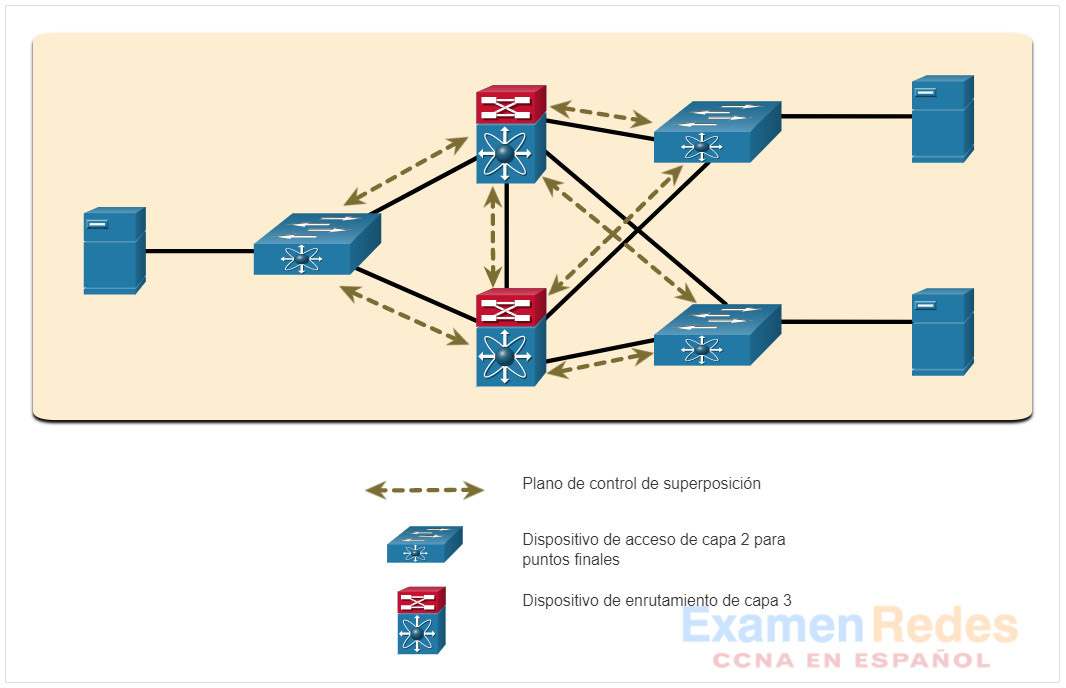
La red subyacente es la topología física que incluye todo el hardware requerido para cumplir con los objetivos comerciales. La capa subyacente revela dispositivos adicionales y especifica cómo están conectados estos dispositivos, como se muestra en la figura. Los puntos finales, como los servidores de la figura, acceden a la red a través de los dispositivos de Capa 2. El plano de control subyacente es responsable de las tareas de reenvío simples.
Ejemplo de red superpuesta
14.6.4. Arquitectura de red digital (DNA, Digital Network Architecture)
Cisco implementa el tejido IBN utilizando Cisco DNA. Como se muestra en la figura, la intención comercial se implementa de forma segura en la infraestructura de red (la estructura). Cisco DNA recopila continuamente datos de una multitud de fuentes (dispositivos y aplicaciones) para proporcionar un rico contexto de información. Esta información puede analizarse para asegurarse de que la red se desempeña de manera segura en su nivel óptimo y de acuerdo con la intención comercial y las políticas de red.
Implementación continua de ADN de Cisco de intención comercial
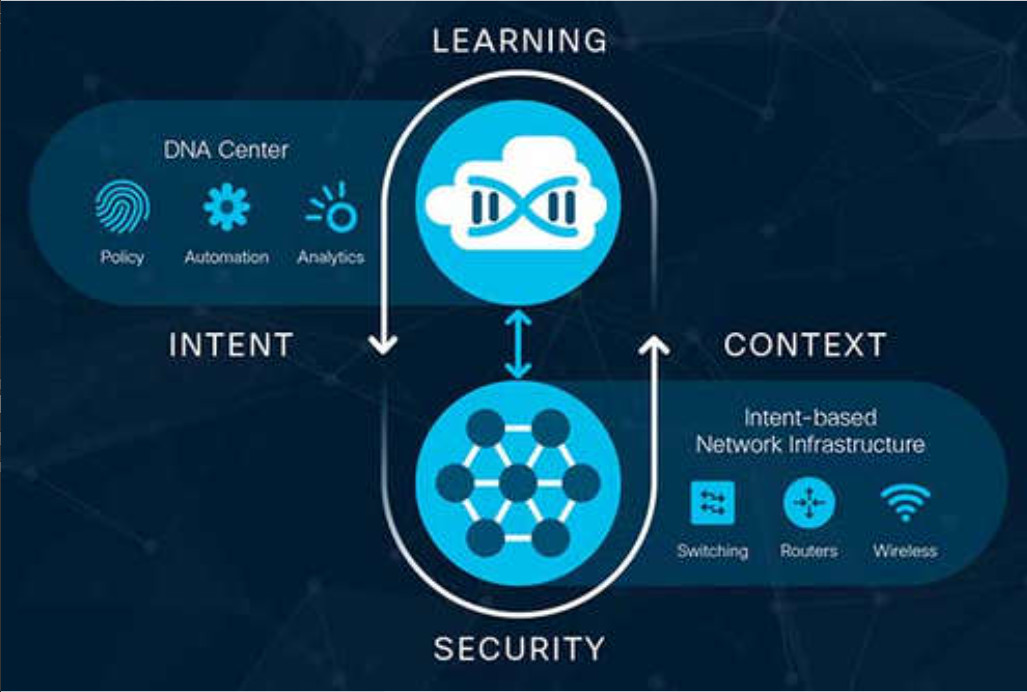
Cisco DNA es un sistema que está constantemente aprendiendo, adaptándose para satisfacer las necesidades del negocio. La tabla enumera algunos productos y soluciones de Cisco DNA.
| Soluciones Cisco DNA | Descripción | Beneficios |
|---|---|---|
| Acceso definido por software | – Primera solución de red empresarial basada en la intención creada con Cisco DNA. – Utiliza una estructura de red única a través de LAN y WLAN para crear una experiencia de usuario consistente y altamente segura. – Segmenta el tráfico de usuarios, dispositivos y aplicaciones y automatiza las políticas de acceso de usuarios para establecer la política correcta para cualquier usuario o dispositivo, con cualquier aplicación, a través de una red. |
Habilite el acceso de cualquier usuario o dispositivo a cualquier aplicación en minutos sin poner en riesgo la seguridad. |
| SD-WAN | – Utiliza una arquitectura segura entregada en la nube para administrar centralmente las conexiones WAN. – Simplifica y acelera la entrega de servicios WAN seguros, flexibles y ricos para conectar centros de datos, sucursales, campus e instalaciones de colocación. |
– Ofrece mejores experiencias de usuario para aplicaciones que residen en las instalaciones o en la nube. – Logre una mayor agilidad y ahorro de costos a través de implementaciones más fáciles e independencia de transporte. |
| Cisco DNA Assurance. | – Se utiliza para solucionar problemas y aumentar la productividad de TI. – Aplica análisis avanzados y aprendizaje automático para mejorar el rendimiento y la resolución de problemas, y predecir para asegurar el rendimiento de la red. – Proporciona notificaciones en tiempo real para condiciones de red que requieren atención. |
– Le permite identificar las causas raíz y proporciona soluciones recomendadas para una resolución de problemas más rápida. – Cisco DNA Center proporciona un panel único y fácil de usar con información y capacidades de desglose. – El aprendizaje automático mejora continuamente la inteligencia de la red para predecir problemas antes de que ocurran. |
| Cisco DNA Center Security | – Se utiliza para proporcionar visibilidad mediante el uso de la red como sensor para análisis e inteligencia en tiempo real. – Proporciona un mayor control granular para aplicar políticas y contener amenazas en toda la red. |
– Reduzca el riesgo y proteja a su organización contra amenazas, incluso en tráfico encriptado. – Obtenga visibilidad de 360 grados a través de análisis en tiempo real para una inteligencia profunda en toda la red. – Menor complejidad con seguridad de extremo a extremo. |
Estas etapas no son mutuamente excluyentes. Por ejemplo, las cuatro soluciones podrían ser implementadas por una organización.
Muchas de estas soluciones se implementan utilizando Cisco DNA Center, que proporciona un panel de software para administrar una red empresarial.
14.6.5. Cisco DNA Center
Cisco DNA Center es el controlador básico y la plataforma de analítica clave de Cisco DNA. Admite la expresión de intenciones para múltiples casos de uso, incluidas las capacidades básicas de automatización, el aprovisionamiento de estructuras y la segmentación basada en políticas en la red empresarial. Cisco DNA Center es un centro de comando y administración de red para el aprovisionamiento y la configuración de dispositivos de red. Es una plataforma de hardware y software que proporciona un «panel de vidrio único» (interfaz única) que se centra en la garantía, el análisis y la automatización.
La página de inicio de la interfaz de DNA Center le ofrece un resumen general del estado y una instantánea de la red, como se muestra en la figura. Desde aquí, el administrador de la red puede profundizar rápidamente en áreas de interés.
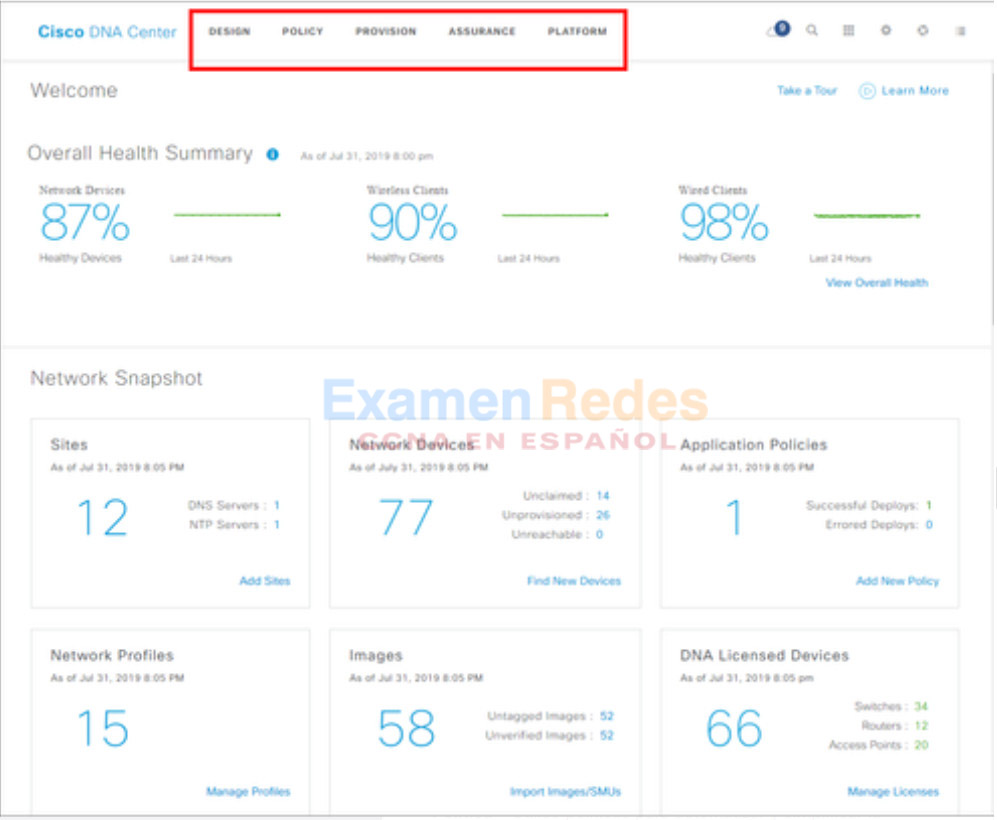
En la parte superior, los menús le brindan acceso a las cinco áreas principales de DNA Center. Como se muestra en la figura, los pasos son:
- Diseño -Modelar toda la red, desde sitios y edificios hasta dispositivos y enlaces, tanto físicos como virtuales, en todo el campus, la sucursal, la WAN y la nube.
- Política – Utilice políticas para automatizar y simplificar la administración de la red, lo que reduce el costo y el riesgo al tiempo que acelera la implementación de servicios nuevos y mejorados.
- Aprovisionamiento – Proporcione nuevos servicios a los usuarios con facilidad, velocidad y seguridad en toda la red empresarial, independientemente del tamaño y la complejidad de la red.
- Aseguramiento – Utilice monitoreo y perspectivas proactivos de la red, los dispositivos y las aplicaciones para predecir los problemas con mayor rapidez y asegurarse de que los cambios en la configuración y la política logren la intención comercial y la experiencia del usuario que usted desea brindar.
- Plataforma – Utilice las API para integrarse con sus sistemas de TI preferidos para crear soluciones de extremo a extremo y agregar soporte para dispositivos de múltiples proveedores.
14.6.6. Video: descripción general de DNA Center y API de plataforma
Esta es la primera parte de una serie de cuatro partes que demuestra el Cisco DNA Center.
La primera parte es una descripción general de la GUI de Cisco DNA Center. Esta incluye herramientas de diseño, políticas, provisión y garantía utilizadas para controlar múltiples sitios y múltiples dispositivos.
Haga clic en Reproducir (Play) en la figura para ver el video.
14.6.7. Video – Diseño y provisión del Centro de ADN
Esta es la primera parte de una serie de cuatro partes que demuestra el Cisco DNA Center.
La segunda parte es una descripción general de las áreas de diseño y provisión de Cisco DNA Center.
Haga clic en Reproducir en la figura para ver el video.
14.6.8. Video – Política y garantía del Centro de ADN
Esta es la primera parte de una serie de cuatro partes que demuestra el Cisco DNA Center.
La tercera parte explica las áreas de política y garantía de Cisco DNA Center.
Haga clic en Reproducir en la figura para ver el video.
14.6.9. Video – DNA Center Solución de problemas de conectividad del usuario
Esta es la primera parte de una serie de cuatro partes que demuestra el Cisco DNA Center.
La cuarta parte explica cómo usar Cisco DNA Center para solucionar problemas de dispositivos.
Haga clic en Reproducir en la figura para ver el video.
14.7. Práctica del módulo y cuestionario
14.7.1. ¿Qué aprenderé en este módulo?
La automatización es cualquier proceso impulsado de forma automática que reduce y, a la larga, elimina, la necesidad de intervención humana. Cada vez que un dispositivo toma una decisión, en función de información externa, dicho dispositivo se conoce como dispositivo inteligente. Para que un dispositivo pueda «pensar», el mismo debe ser programado utilizando herramientas de automatización de red.
Los formatos son simplemente una manera de almacenar e intercambiar datos de una manera estructurada. Uno de esos formatos es el Lenguaje de marcas de hipertexto (Hypertext Markup Language – HTML). Los formatos de datos comunes que se utilizan en muchas aplicaciones, incluida la automatización de red y la programación, son JavaScript Object Notation (JSON), eXtensible Markup Language (XML) y YAML Ain’t Markup Language (YAML). El formato de datos posee reglas y estructuras similares a los que tenemos en programación y lenguajes escritos.
Un API es un conjunto de reglas que describe como una aplicación puede interactuar con otra, y las instrucciones para que esa interacción ocurra. Las API abiertas/públicas están, como su nombre indica, disponibles públicamente. Las API internas/privadas se utilizan dentro de una organización. Las API de socios son API entre una empresa y sus socios comerciales. Existen cuatro tipos de API de servicio web: Protocolo simple de acceso a objetos (SOAP), Transferencia de estado representacional (REST), Llamada a procedimiento remoto de lenguaje de marcado extensible (XML-RPC) y Llamada a procedimiento remoto de notación de objetos JavaScript (JSON-RPC).
Define un conjunto de funciones que los desarrolladores pueden usar para realizar solicitudes y recibir respuestas a través del protocolo HTTP como GET y POST. El cumplimiento de las restricciones de la arquitectura REST generalmente se conoce como «RESTful». Las API RESTful utilizan métodos HTTP comunes, como POST, GET, PUT, PATCH y DELETE. Estos métodos corresponden a operaciones RESTful: Crear, Leer, Actualizar y Eliminar (o CRUD). Los recursos web y los servicios web, como las API RESTful, se identifican mediante un URI. Un URI tiene dos especializaciones, Nombre uniforme de recurso (URN, Uniform Resource Name) y Localizador uniforme de recursos (URL, Uniform Resource Locator). En un servicio web RESTful, una solicitud realizada al URI de un recurso obtendrá una respuesta. La respuesta será una carga normalmente formateada en JSON. Las diferentes partes de la solicitud de API son servidor de API, recursos y consulta. Las consultas pueden incluir formato, clave y parámetros.
Existen métodos nuevos y diferentes para que los operadores de red supervisen, administren y configuren automáticamente la red. Como se muestra en la figura, estos incluyen protocolos y tecnologías como REST, Ansible, Puppet, Chef, Python, JSON, XML y más. Las herramientas de administración de configuración utilizan las solicitudes de API RESTful para automatizar tareas y pueden escalar en miles de dispositivos. Las características de la red que se benefician de la automatización incluyen el control de software y versiones, los atributos del dispositivo, como los nombres, el direccionamiento y la seguridad, las configuraciones de protocolo y las configuraciones de ACL. Las herramientas de gestión de la configuración suelen incluir automatización y orquestación. La orquestación organiza un conjunto de tareas automatizadas que dan como resultado un proceso de coordenadas o un flujo de trabajo. Ansible, Chef, Puppet y SaltStack vienen con documentación de API para configurar solicitudes de API RESTful.
IBN se basa en SDN, adoptando un enfoque centrado en el software y totalmente automatizado para diseñar y operar redes. Cisco considera que IBN tiene tres funciones esenciales: traducción, activación y seguridad. La infraestructura de red física y virtual es un tejido. El término fabric describe una superposición que representa la topología lógica utilizada para conectarse virtualmente a los dispositivos. La red subyacente es la topología física que incluye todo el hardware requerido para cumplir con los objetivos comerciales. Cisco implementa el fabric IBN utilizando Cisco DNA. Como se muestra en la figura, la intención comercial se implementa de forma segura en la infraestructura de red (la estructura). Cisco DNA recopila continuamente datos de una multitud de fuentes (dispositivos y aplicaciones) para proporcionar un rico contexto de información. Cisco DNA Center es el controlador básico y la plataforma de analítica clave de Cisco DNA. Cisco DNA Center es un centro de comando y administración de red para el aprovisionamiento y la configuración de dispositivos de red. Es una plataforma de hardware y software que proporciona un «panel de vidrio único» (interfaz única) que se centra en la garantía, el análisis y la automatización.